Recopilación de información
Trataremos encontrar, recopilar y procesar la mayor cantidad de información sobre el objetivo para ayudarnos a poder indentificar vectores de ataque que, potencialmente, puedan comprometer la confidencialidad, integridad o disponibilidad de los activos del cliente. Casi todos los métodos que se mostrarán a continuación son pasivos porque no se interactua directamente con el objetivo.
Metodología
Recopilaremos información de varias fuentes usando el siguiente método:
- Guardando la información con CherryTree
- Consultando información en buscadores de internet
- Buscadores habituales
- Certificate Transparency
- Netcraft
- IPv4info
- Censys
- Shodan
- Internet Archive
- Have I Been Pwned
- Pastebin
- Realizando busquedas específicas
- Operadores de Google para filtrar busquedas
- Google Hacking Database (GHDB)
- Operadores de Shodan para filtrar busquedas
- Páginas web
- Cabeceras HTTP y código fuente
- Web crawlers (Web Spiders)
- Ataques de diccionario para descubrir directorios y ficheros
- Web scrapers
- Descargar web para navegación offline
- Metadatos en archivos
- Buscando información en redes sociales
- Procesando la información contenida en redes sociales
- Usando buscadores específicos para redes sociales
- Email
- Recopilando emails de un dominio usando The Harvester
- Buscando información en las cabeceras de un email
- Bases de datos WHOIS
- Bases de datos WHOIS
- Consultas a bases de datos WHOIS desde la línea de comandos
- Consultas a bases de datos WHOIS en España
- Consultas a bases de datos WHOIS usando páginas web
- DNS
- Breve introducción de manera muy informal a DNS
- Consultas a servidores DNS usando nslookup
- Consultas a servidores DNS usando dig
- Consultas a servidores DNS usando páginas web
- Usando el RIR para encontrar bloques de red
Referencias usadas
1. Guardando la información con cherrytree
Antes de comenzar el proceso de recopilación de información, es recomendable tener algún programa donde almacenar la información que vayamos recopilando. Aunque existen muchas opciones, por facilidad de uso, usamos cherrytree. Podemos descargarlo de su web:
Tras instalarlo, lo ejecutamos y tendremos una interfaz muy parecida a esta:

Pulsamos en el botón de arriba a la izquierda para añadir un nuevo nodo. En la venta de opciones, le ponemos el nombre del activo o compañia que estemos auditando y pulsamos el botón OK:
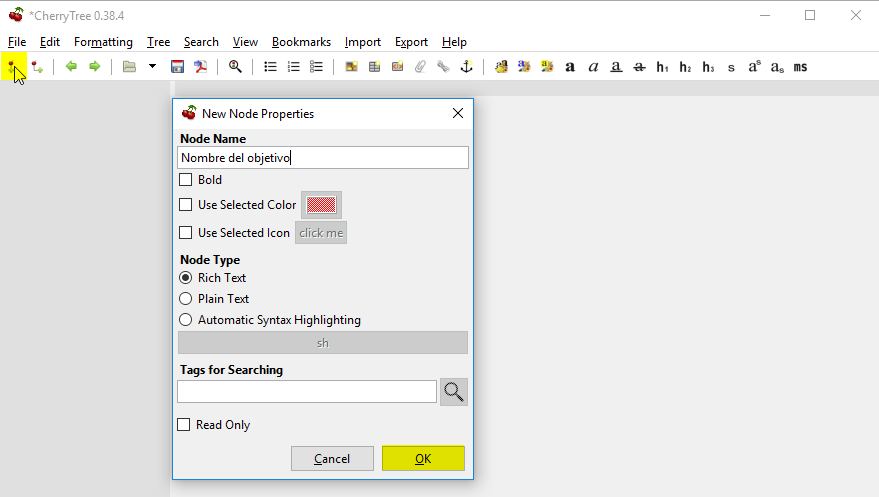
Vemos como se ha añadido el nodo en el panel de la izquierda:

En el recuadro azul podemos indicar el alcance de la auditoria y otros detalles que consideremos importantes. Una vez determinado el alcance, pulsamos sobre el botón de añadir subnodos para recopilar los datos de la primera parte de la auditoria:

En este caso lo llamamos recopilación de información:
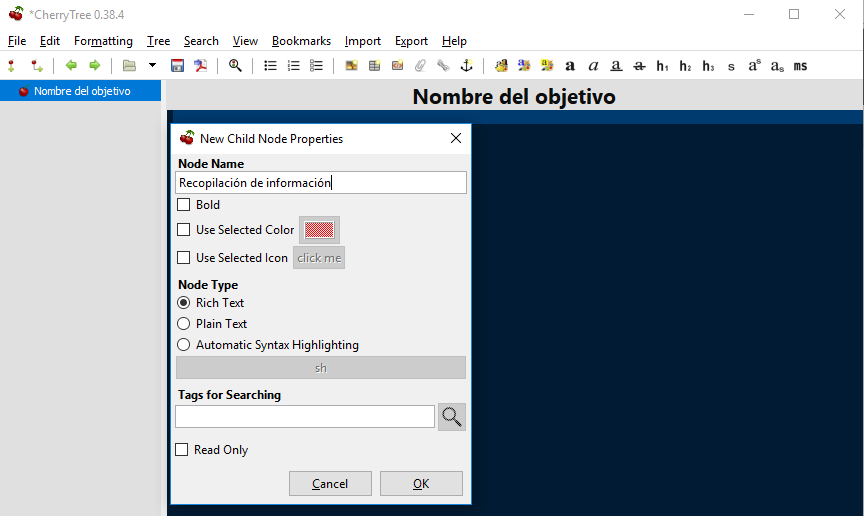
En este caso, también podemos usar el recuadro azul para definir el alcance:
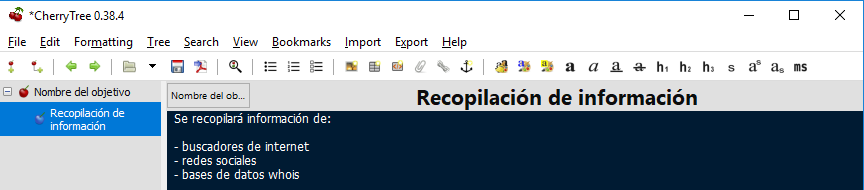
y podemos seguir añadiendo tantos subnodos como necesitemos. Por ejemplo, añadamos el de buscadores de internet. Para ello pulsamos nuevamente el botón añadir subnodo y le damos nombre:
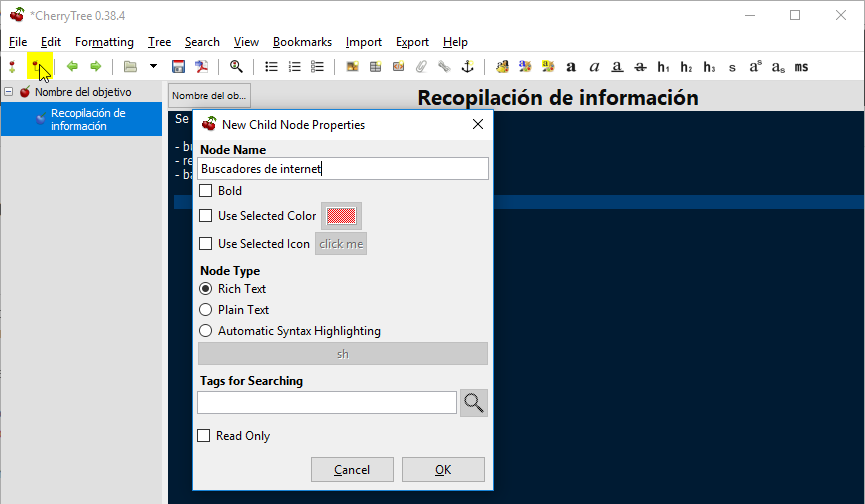
En el recuadro azul podemos ir pegando las evidencias que recopilemos de las busquedas en distintos navegadores:
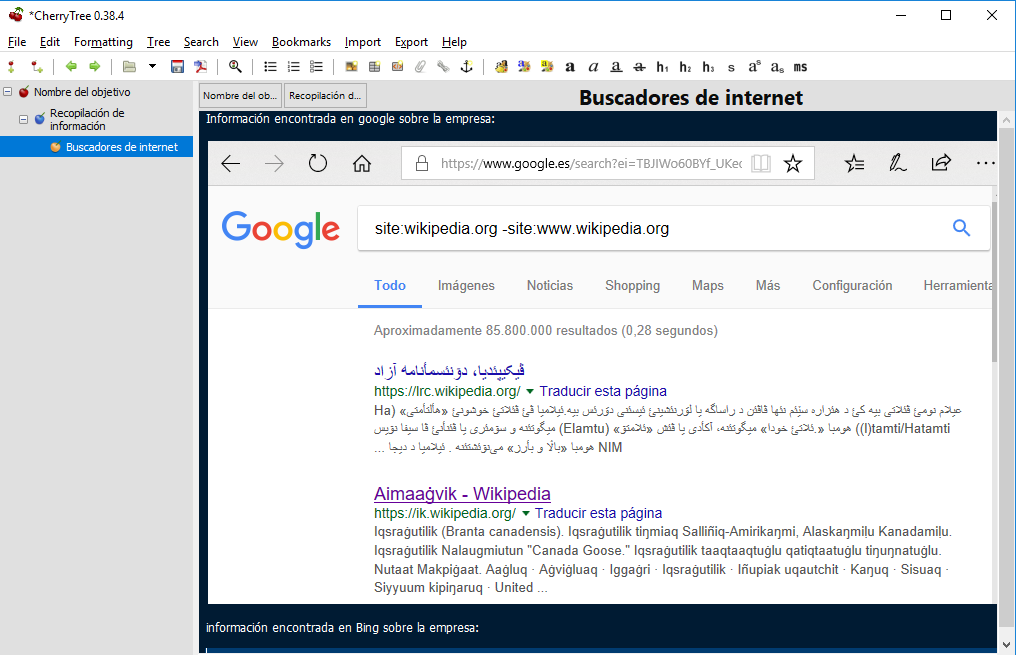
en resumen, podremos crear todos los nodos y subnodos queramos para la auditoria que tengamos que realizar:
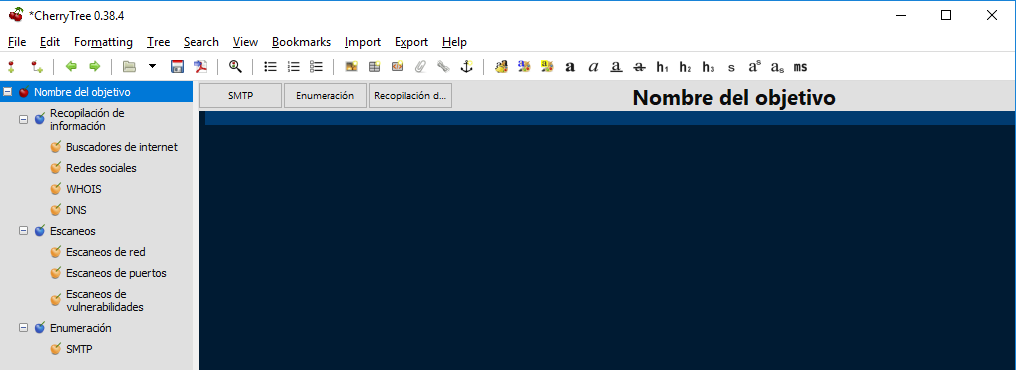
la finalidad es ir documentando a medida que vamos obteniendo evidencias.
2. Consultando en buscadores de internet
Aparte de los buscadores que habitualmente utilizamos para realizar busquedas en internet:
Existen otros sites más específicos que pueden aportarnos algo más de información:
Certificate Transparency
El proyecto, Certificate Transparency de Google, se ha creado para auditar y verificar certificados TLS/SSL en tiempo real con el fin de prevenir usos fraudulentos o maliciosos de los certificados. Aunque esto se ha creado para favorecer la seguridad, también favorece la recopilación pasiva de información sobre un objetivo porque obliga a todas las autoridades certificadores (CA) que participen, a publicar todos los certificados que hayan expedidos. Esta información, entre otros, podría revelar hostnames y subdominios del objetivo. Para realizar una busqueda accedemos al buscador de cerfificados:
![]()
En los resultados podemos ver:
- Los certificados expedidos para el dominio
- La fecha de validez de los certificados
- Incluso el número de subdominios (DNS Names) asociados al certificado
![]()
Si pulsamos sobre See Details en cualquiera de ellos podremos ver los subdominios:
![]()
Netcraft
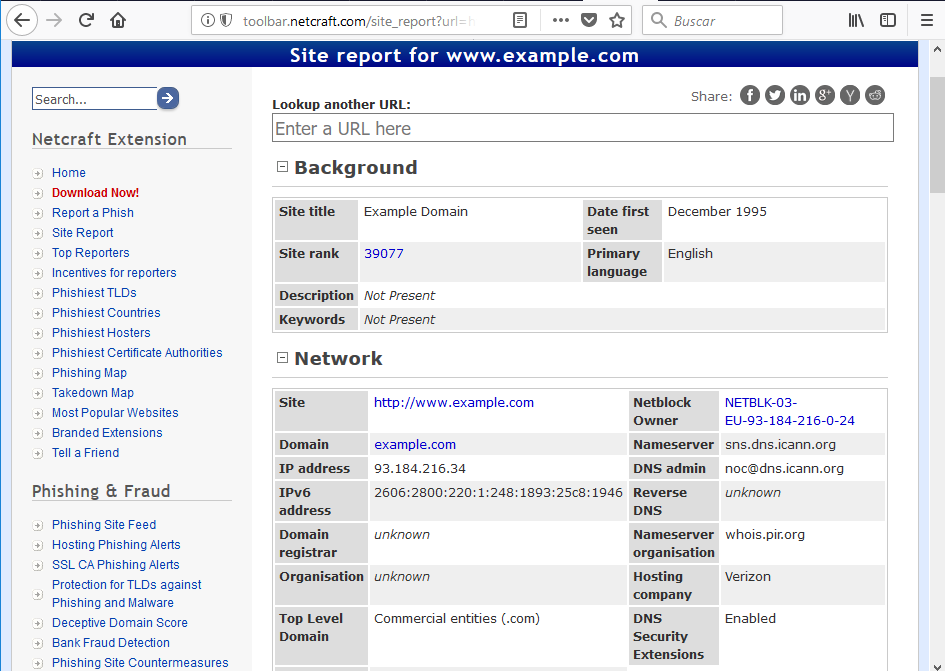
Netcraft puede ayudarnos a encontrar información específica sobre un objetivo. Por ejemplo, si quisieramos recopilar información sobre el dominio www.example.com:

Dependiendo del dominio que busquemos, entre otros, podremos encontrar:
- Información sobre el dueño del dominio
- La IP asociada al dominio
- La localización física de la IP del dominio
- Sistemas operativos que usan
IPv4info
IPv4info nos puede ayudar a conocer mucha información sobre la infraestructura de red de un objetivo:
Veamos un ejemplo:
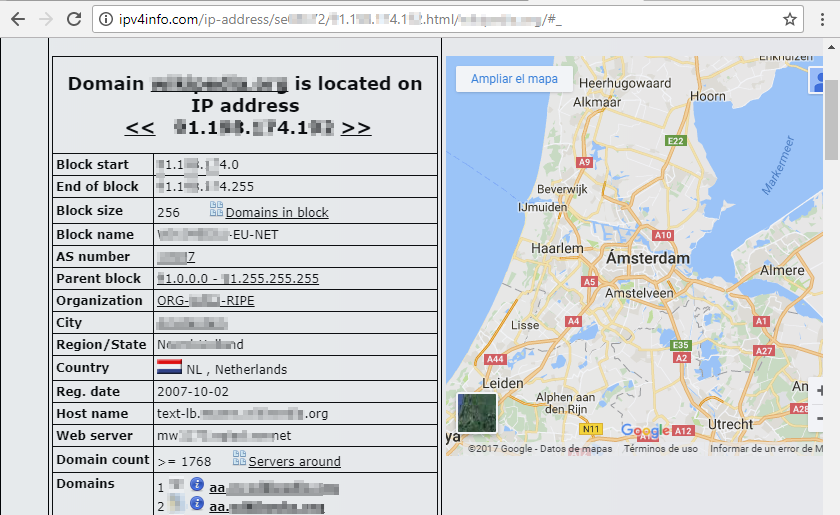
Dependiendo del dominio que busquemos, entre otros, podremos encontrar:
- Los subdominos asociados a ese dominio
- Información sobre el dueño del dominio
- La IP asociada al dominio
- La localización física de la IP del dominio
- Bloque de red
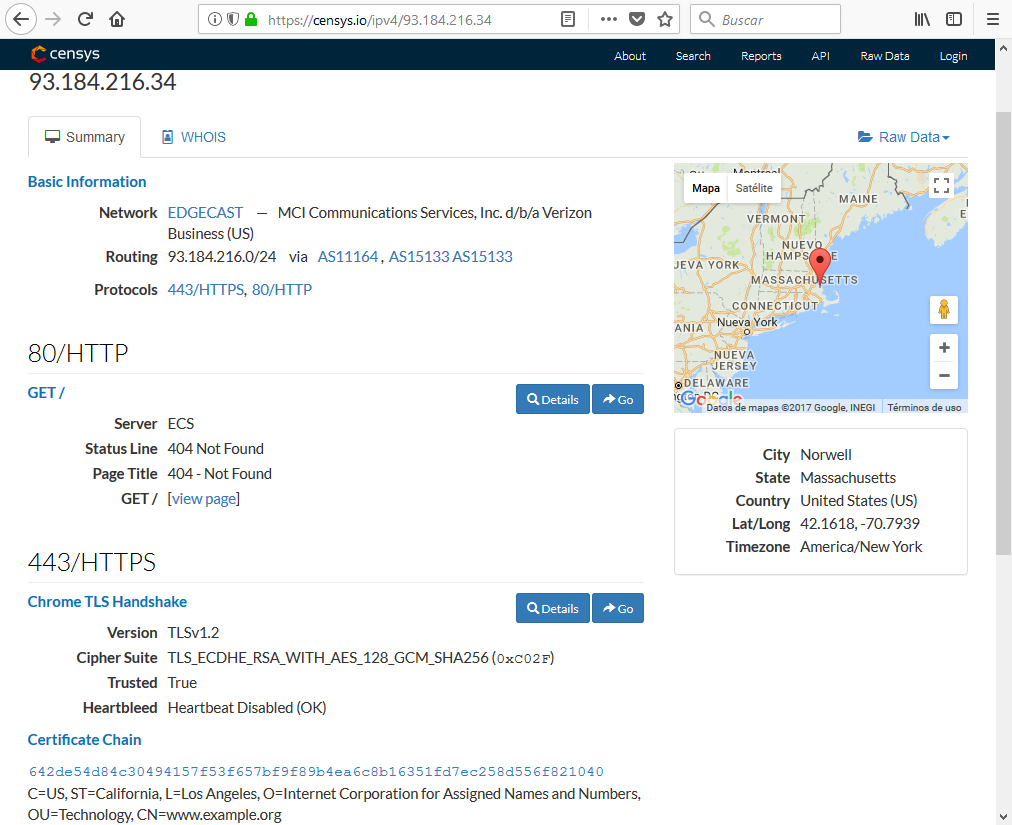
Censys
Censys es un buscador de dispositivos conectados a internet como frigoríficos, aparatos de domótica, cámaras de vigilancia, ordenadores, servidores, routers, switches, etc. Lo que hoy en día se denomina internet de las cosas (IoT). Nos va a facilitar información sobre el activo que busquemos:

Entre otros nos muestra:
- Los puertos y servicios a la escucha
- La localización física del activo
- Información sobre los certificados
Shodan
Shodan es un buscador de dispositivos conectados a internet como frigoríficos, aparatos de domótica, cámaras de vigilancia, ordenadores, servidores, routers, switches, etc. Lo que hoy en día se denomina internet de las cosas (IoT). Nos va a facilitar información sobre el activo que busquemos:
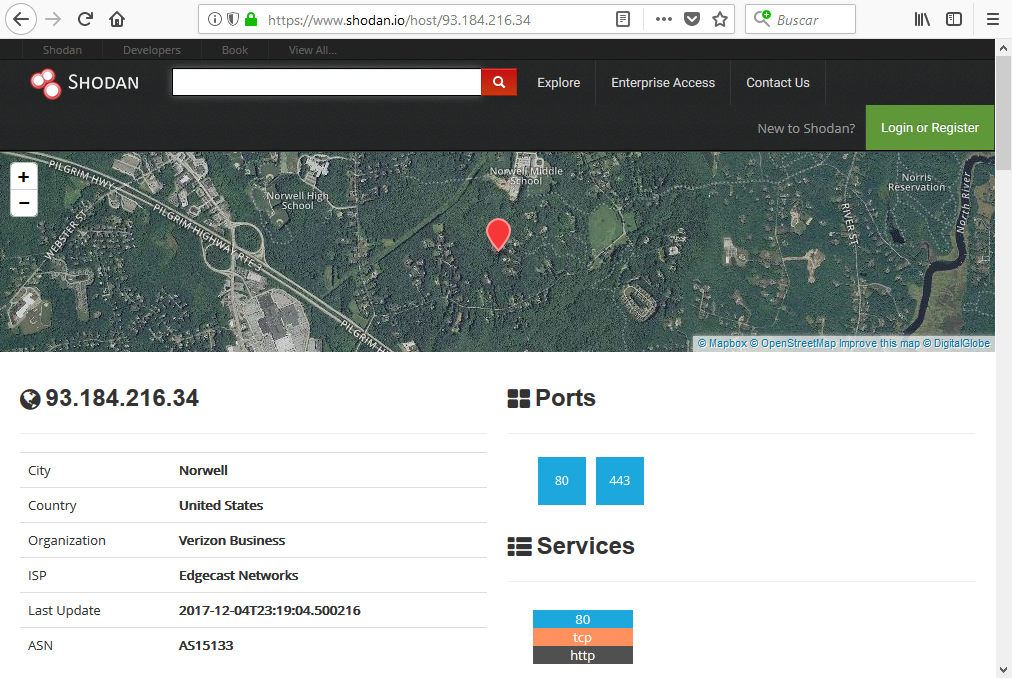
Nuevamente vemos:
- Los puertos y servicios a la escucha
- La localización física del activo
- Información sobre los certificado
Internet Archive
Internet Archive es una biblioteca que guarda versiones antiguas de páginas web y recursos como videos, audios, libros, etc. Debido a que podremos acceder a versiones archivadas de la misma página web o recurso, nos puede ser muy útil para:
- Acceder a información que el objetivo haya borrado o modificado.
- Acceder a documentación que se haya borrado o modificado.
- Ver contenidos que ya no están disponibles
Para usarlo buscamos el recurso:

Elegimos la fecha para ver la versión que se archivo del mismo:

Have I been pwnd?
Have I been pwnd? nos facilita información sobre cuentas que han sido comprometidas. Sólo tenemos que indicar la cuenta que queramos buscar:
para acceder a la información:
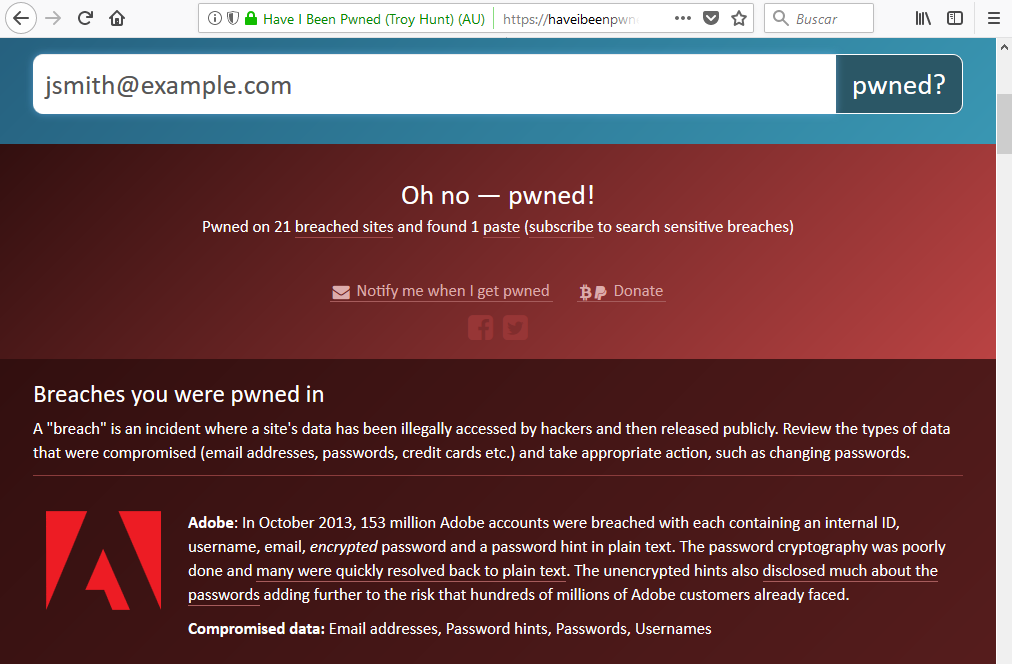
A veces podremos encontrar enlaces que nos faciliten conseguir la password de la cuenta comprometida y si no, sabiendo que ha sido comprometida, podemos buscar la contraseña en pastebin.
Pastebin
Permite copiar y pegar información de forma completamente anónima. Lo cual es muy atractivo para publicar, entre otros, la información confidencial que se extrae de las brechas de seguridad:
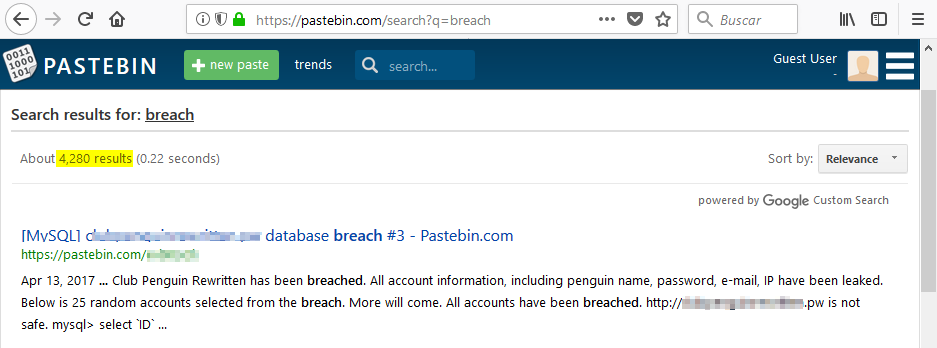
Por ejemplo, si buscamos la palabra breach, nos aparecen resultados de bases de datos que han sido comprometidas:
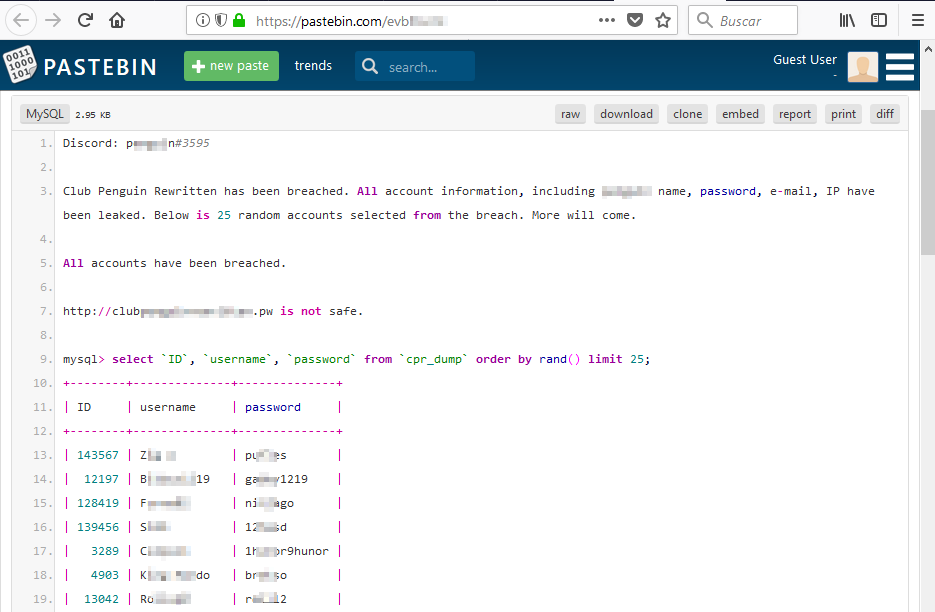
Y accediendo a ellos podemos, por ejemplo, encontrar usuarios y contraseñas:
3. Realizando busquedas específicas
Operadores de Google para filtrar busquedas
Las busquedas personalizadas en el buscador de Google son un mundo al que se han dedicado libros como Google Hacking for Penetration Testers.
Google permite usar una serie de términos, que se denominan operadores, para filtrar las consultas que realicemos al buscador. Podemos combinar varios operadores en la misma busqueda. Además estos términos (operadores) pueden combinarse utilizando wildcards (comodines) o operadores booleanos. Algunos terminos (operadores) conocidos son:
site:
Nos permite restringir los resultados de la busqueda a un dominio/subdominio concreto. Por ejemplo, podemos buscar información sobre android en la web xataca.com:
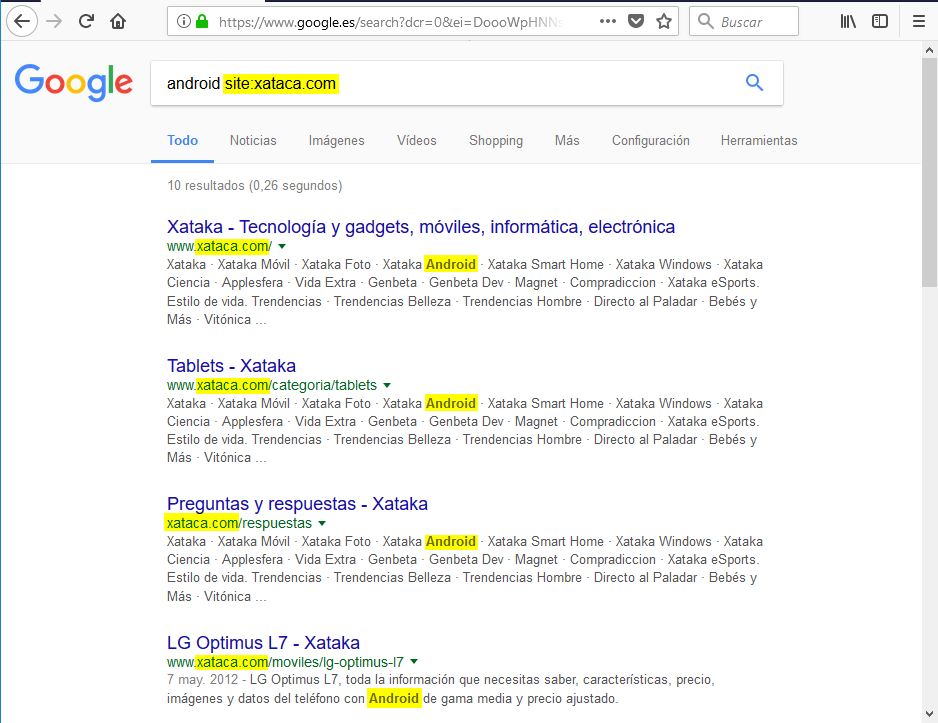
También nos permitiría buscar los subdominios de un dominio. Para ello, utilizamos el operador booleano de negación (-) delante de site. Es decir que si:
site: filtra los resultados a un dominio/sudominio concreto
entonces con:
-site: obtendremos los resultados que no esten incluidos en ese dominio/subdominio
Utilizando el operador booleano de negación, podemos sacar todos los subdominios del dominio google.com:
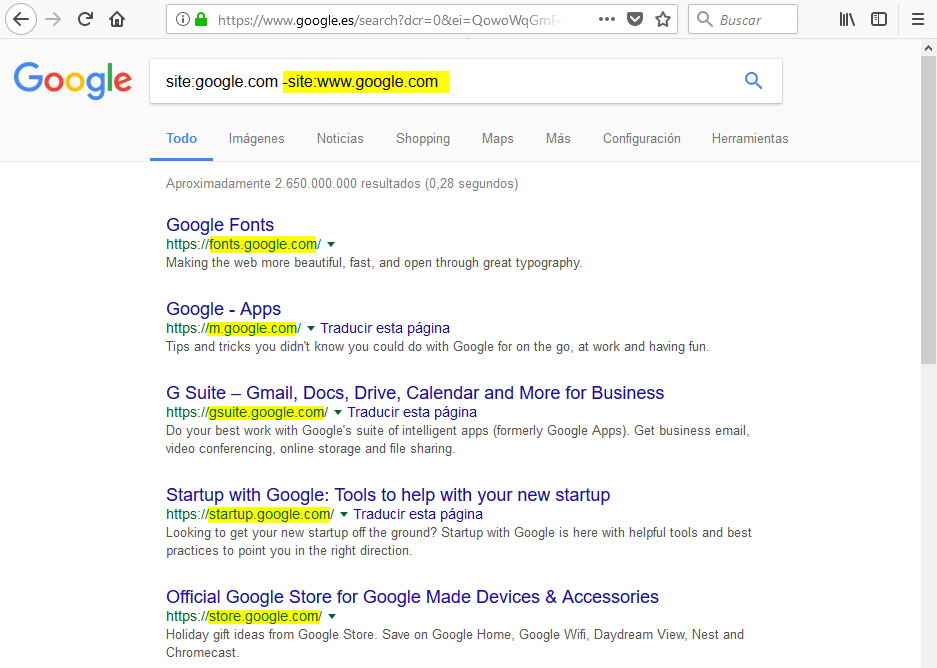
El comodín (wildcard) asterisko (*) se puede utilizar para representar alguna palabra que no conozcamos al hacer la busqueda. En pastebin se hacen dumps (volcados) de diversa información como cuentas, bases de datos, etc. Estos volcados, habitualmente, incluyen alguna palabra y después la palabra dump como account dump o nombreDeCompañia dump. Podemos buscar los dumps usando el comodían asterisco:
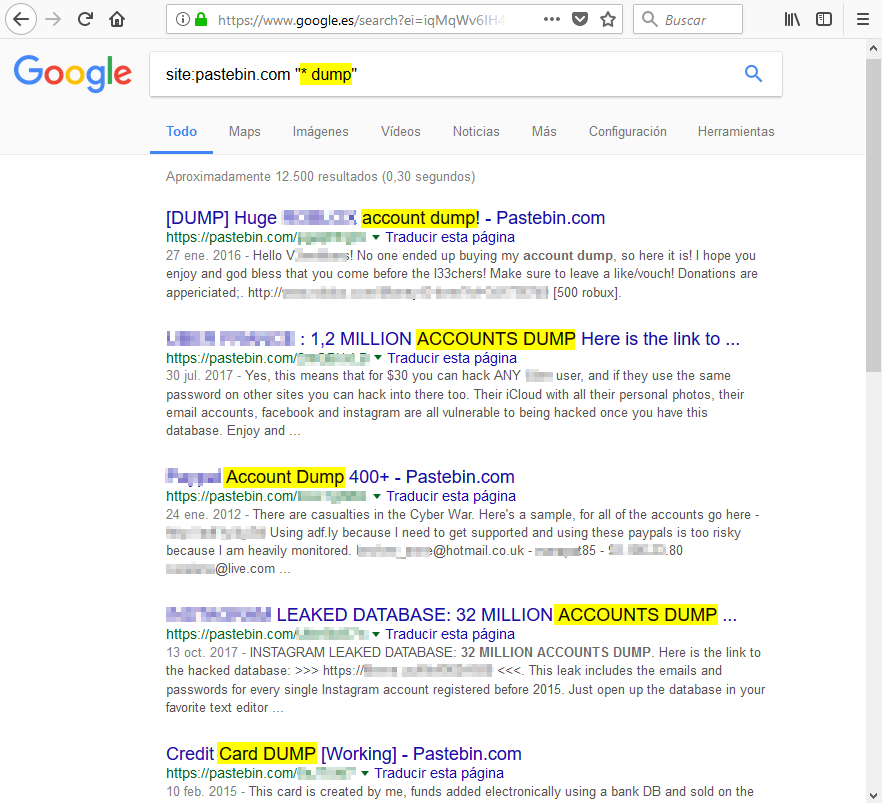
Siguiendo con el ejemplo de los dumps, podemos añadir un parámetro en el query string de la URL llamado as_qdr para filtrar los resultados a sitios que hayan sido actualizados desde hace x tiempo. Por ejemplo, podemos buscar los dumps (vocados) en pastebin publicados o actualizados en el último mes pasando el valor m1:
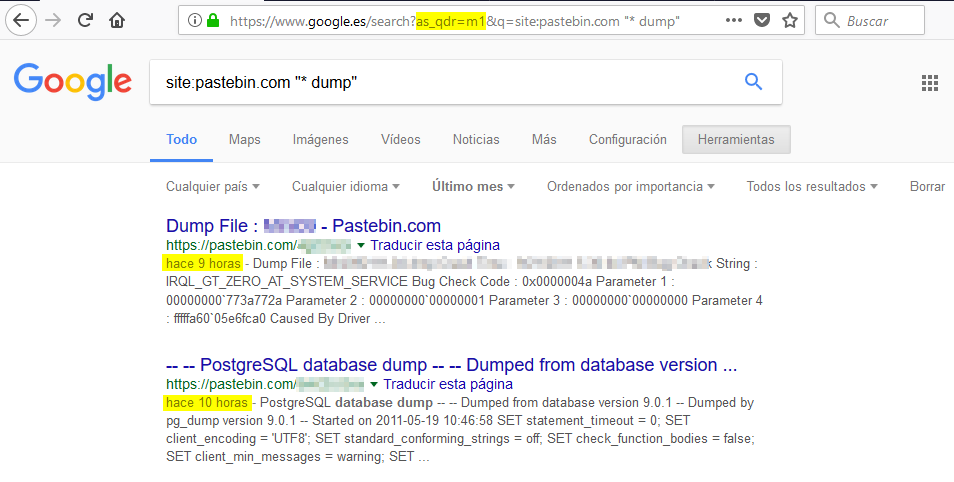
Otros valores que podemos usar con as_qdr son:
- d3 buscaría resultados actualizados en los últimos 3 días
- w2 buscaría resultados actualizados en las últimas 2 semanas
- m1 buscaría resultados actualizados en el último mes
- y2 buscaría resultados actualizados en los 2 últimos años
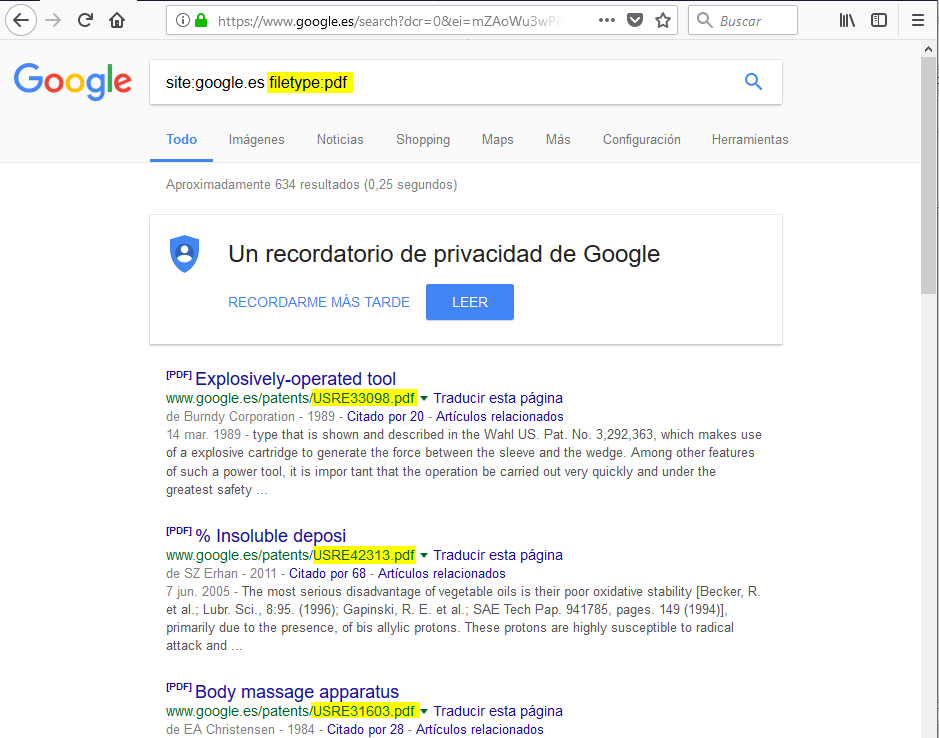
filetype:
Nos permite buscar ficheros del tipo que le indiquemos. Por ejemplo, para buscar ficheros de tipo pdf en google.es:
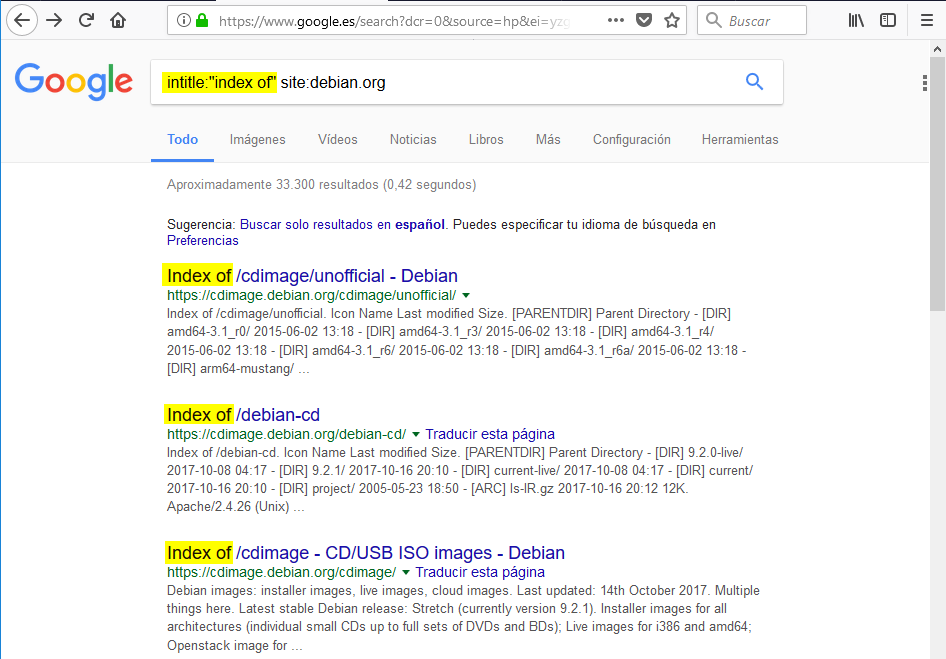
intitle:
Retringe la busqueda a aquellas páginas que contengan en el título de la página las palabras buscadas. Esto puede ser útil, por ejemplo, para encontrar servidores que tienen habilitada la opción de listar directorios. En muchas ocasiones, cuando los servidores listan archivos y carpetas en un servidor, el título contiene las palabras Index Of. Veamos un ejemplo:
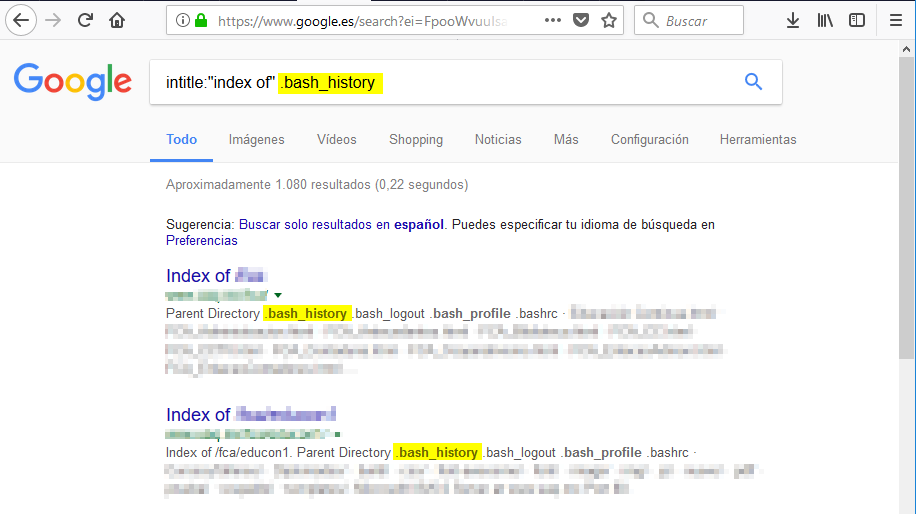
Dentro de estos listados de directorios, podemos buscar ficheros importantes como .bash_history:
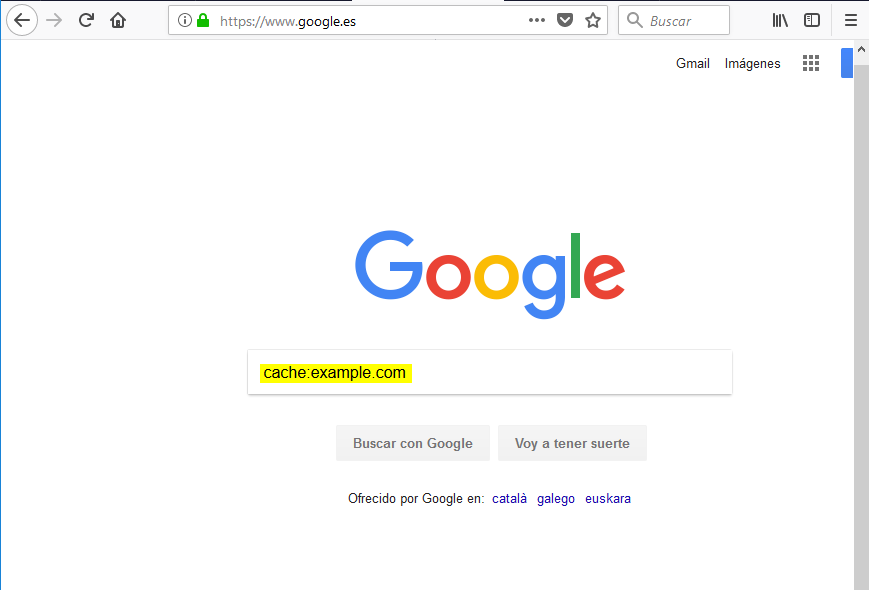
cache:
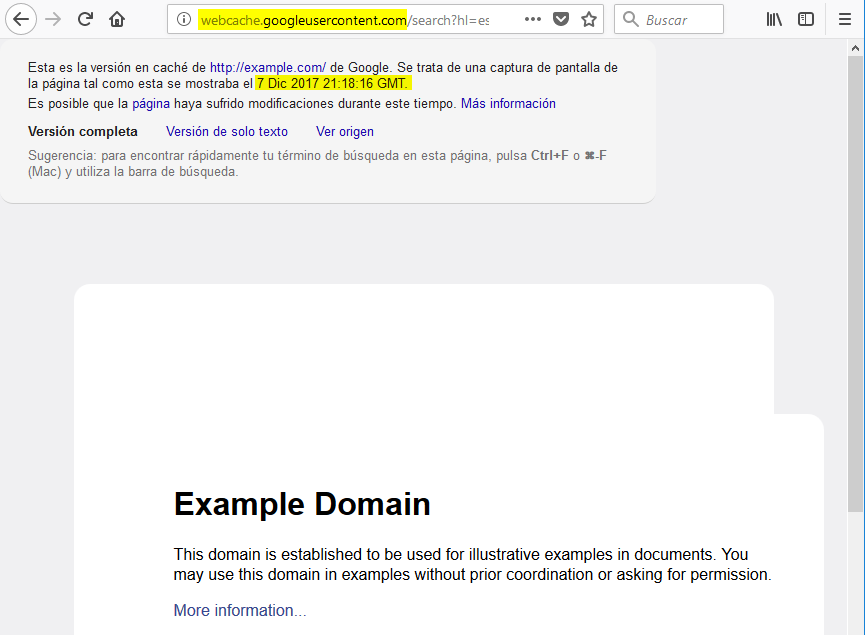
Google guarda snapshots (copias) de los sitios que indexa cada cierto tiempo. El operador cache: nos permite acceder a estas versiones (copias) de la página web. Esto nos va a permitir, entre otros, poder navegar por un sitio web de forma pasiva o anónima de cara al dueño del sitio ya que no interactuamos directamente con su web. Esto además nos permite crawlear o descargar una copia de un sitio web de forma pasiva. Para ver el sitio web en cache de example.com utilizamos el operador cache:
y accedemos a la web en cache:
Google Dorks / Google Hacking Database (GHDB)
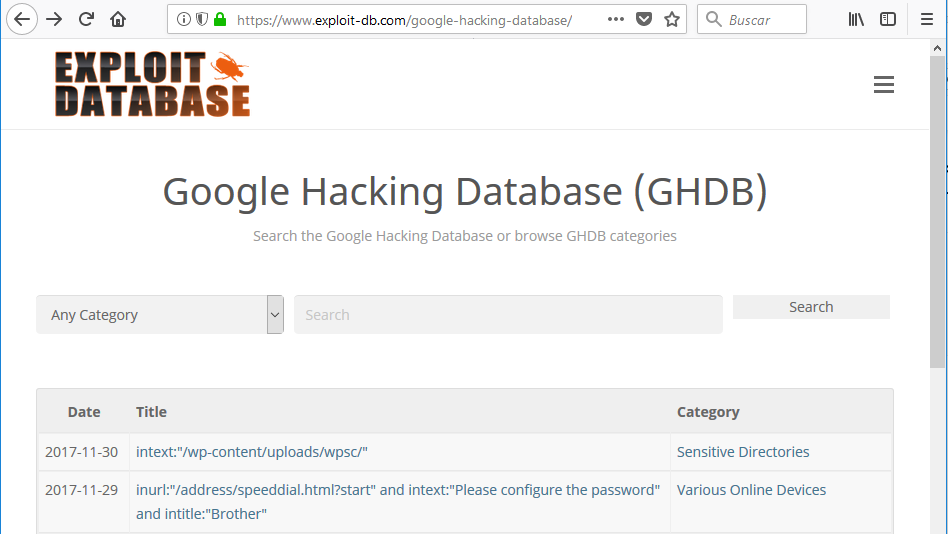
Como hemos visto en el punto anterior, filtrar las busquedas en google puede ser muy útil a la hora de recopilar información. Sin embargo hay muchos operadores y distintas formas de combinarlos. GHDB es un proyecto que nos va a permitir realizar este tipo de busquedas sin necesidad de conocer los operadores:
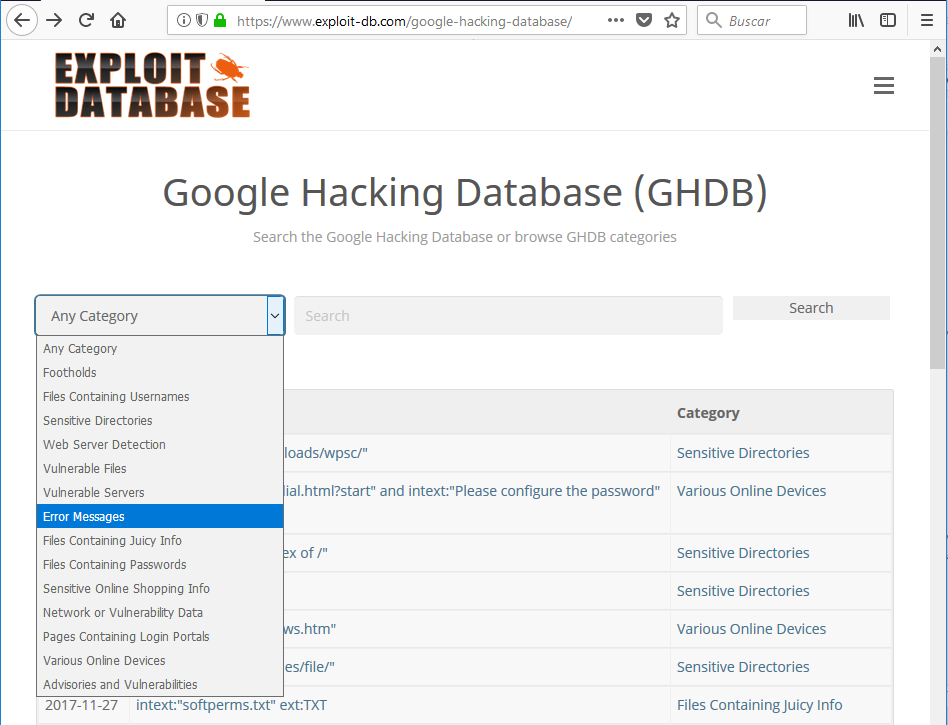
Como podemos ver en el desplegable, existen varias categorias por las que podemos buscar:
Operadores de Shodan para filtrar busquedas
En shodan también podemos utilizar términos (operadores) para filtrar las busquedas.
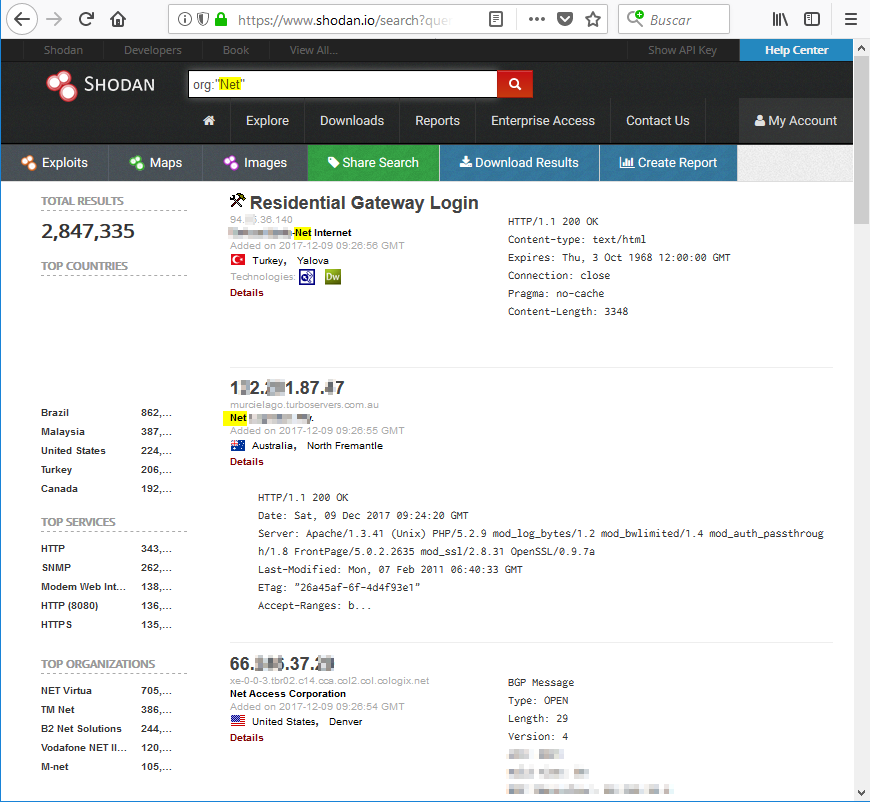
org
El filtro org nos permite buscar dispositivos de una organización concreta. Por ejemplo, lo utilizamos para buscar organizaciones que contengan la palabra Net:
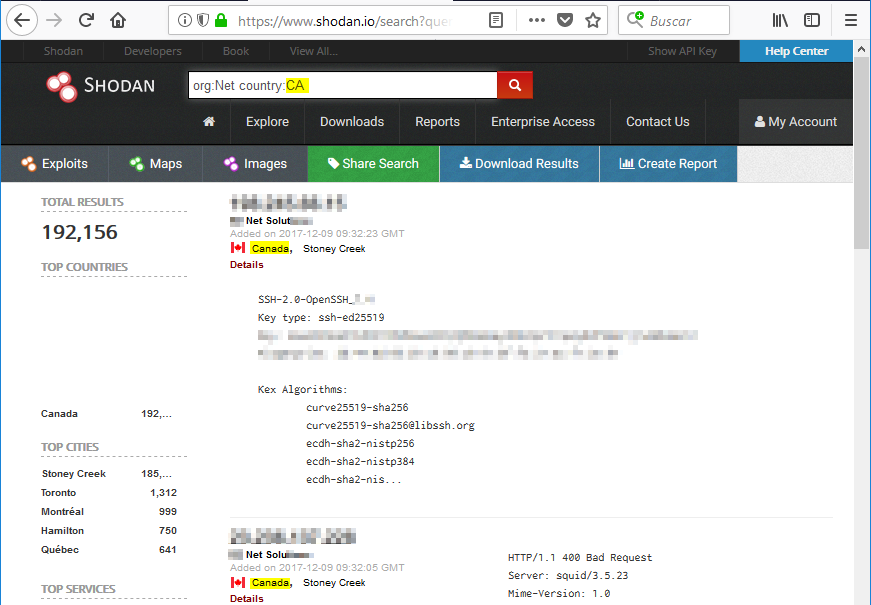
country
Nos permite filtrar los resultados a un páis concreto como Canadá:
city
Nos permite filtrar los resultados a una ciudad concreta como Québec:
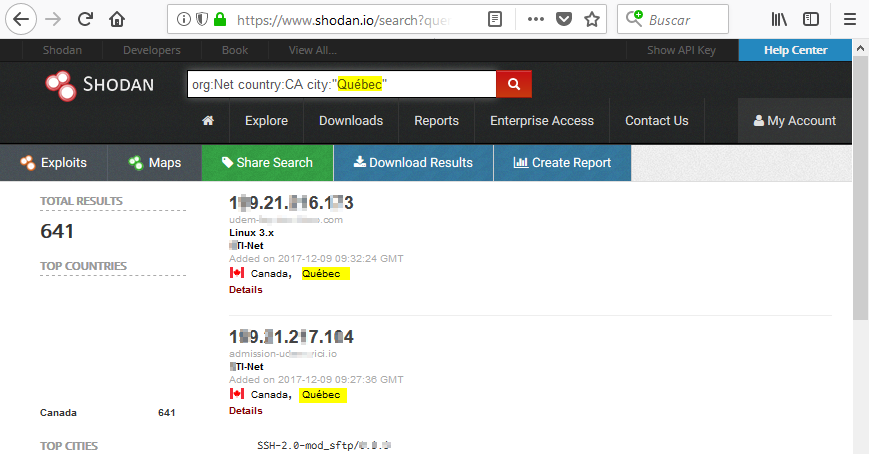
Al igual que ocurría en las consultas en el buscador de Google, podemos utilizar operadores booleanos como el de negación. Por ejemplo, podemos filtrar los resultados a todas las ciudades de Canadá menos Québec:

4. Páginas Web
La mayoría de los métodos de reconocimiento que veremos aquí son activos porque se interactua directamente con el objetivo.
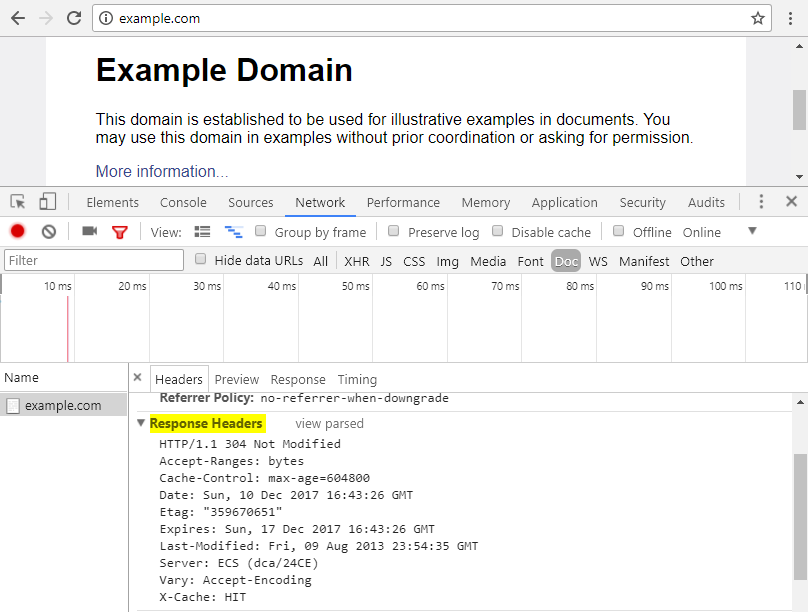
Cabeceras HTTP y código fuente
Las cabeceras de respuesta del protocolo HTTP pueden facilitarnos información como el tipo de servidor que se esta utilizando o si estan implementadas cabeceras que mejoren la seguridad. Para ver las cabeceras de una petición, entre otros, podemos usar las herramientas de desarrollo de cualquier navegador web:
El código fuente de una página puede darnos muchísima información pero, de momento, se sale del objeto del presente documento.
Web crawlers (Web Spiders)
Los web crawlers también conocidos como arañas web (web spiders) son programas que siguen todos los enlaces que haya en un sitio web permitiendonos descubrir la estructura del sitio objetivo. Por ejemplo, como las páginas web usan enlaces para enlazar contenidos dentro del mismo sitio web o contenidos en otros sitios web, los buscadores de internet usan arañas web para indexar todos los contenidos de las páginas web que luego nos muestran en el buscador. Por ejemplo, la araña de Google se llama GoogleBot. Nosotros también usaremos arañas para conocer la estructura de las páginas webs que tengamos que auditar. Aunque lo mejor es lo artesano, vamos a ver como usar la araña de Burp Suite. Para ello tenemos que configurar el navegador que usemos para utilzar Burp Suite como proxy. Como Burp y Firefox vienen por defecto en Kali, veamos como realizar la configuración con ambos:
En la sección Advanced de las menu de preferencias (opciones) del navegador, bajo la pestaña Network, hacemos click en el botón Settings..:
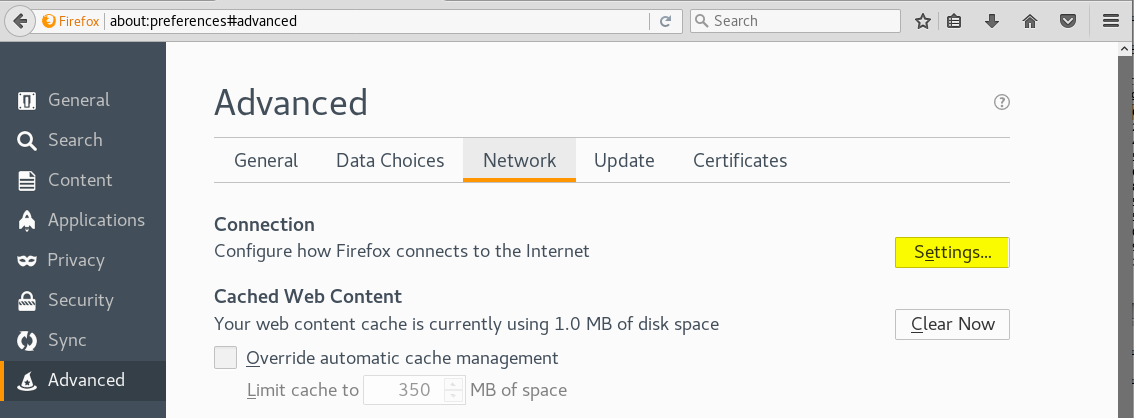
Burp Suite usa por defecto el puerto 8080, lo configuramos para que use ese puerto y pulsamos el botón OK:
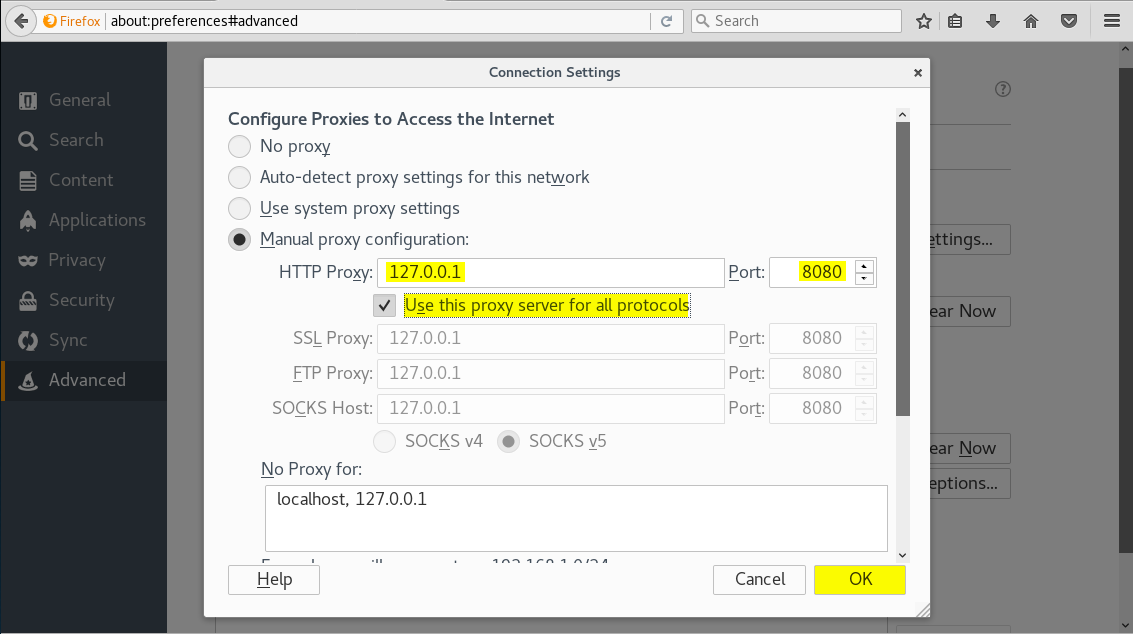
Una vez configurado burp, nos aparecerá la siguiente pantalla:
Si está activado el proxy lo desactivamos. Para que este desactivado tiene que poner Intercept is off en el botón:

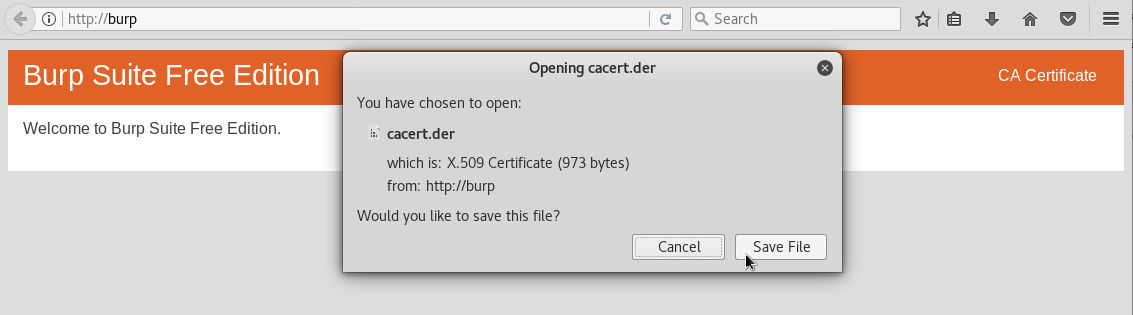
Como muchas páginas estan encriptadas usando TLS/SSL, necesitamos un certificado para que burp pueda conectarse a ellas. Burp Suite nos facilita un certificado de forma gratuita, para descargarlo debemos ir a http://burp en el navegador donde tengamos configurado el proxy. Una vez ahí, hacemos click sobre CA Certificate y lo descargamos:

y lo descargamos:
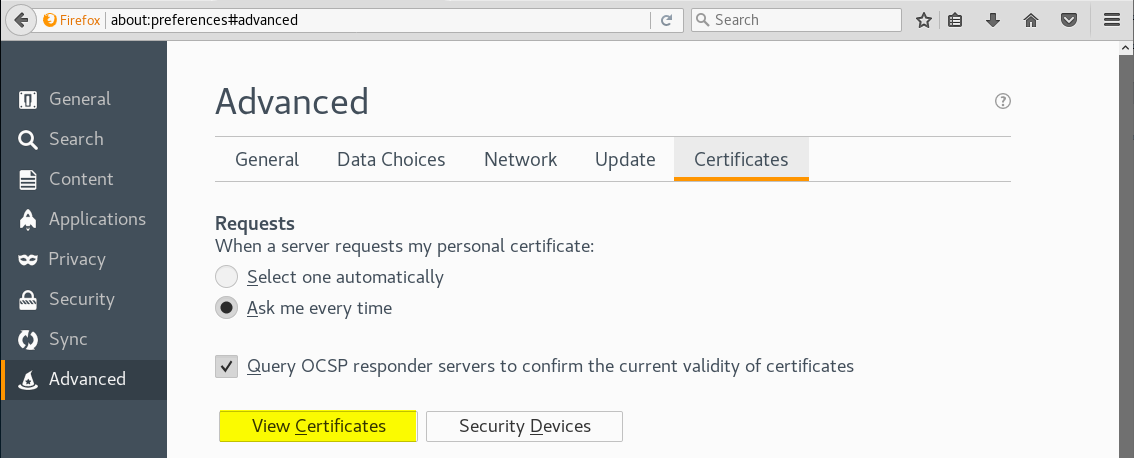
Una vez tengamos el certificado, lo tenemos que importar en Firefox. Para ello en la sección Advanced de las menu de preferencias (opciones) del navegador, bajo la pestaña Certificates, hacemos click en el botón View Certificates:
Hacemos click en Import:
Seleccionamos el certificado que acabamos de descargar y pulsamos el botón Open:

Marcamos todas las casillas y pulsamos OK para instalar el certificado:
Una vez tenemos Burp Suite y Firefox configurados, podemos usar la araña de Burp. Para ello, navegamos al sitio web:

Tras acceder al sitio web, nos aparecerá en Burp bajo la pestaña Target. Pinchamos con el botón derecho del ratón en el sitio web y hacemos click en la opción Add to Scope:
Una vez añadido vamos a la pestaña Spider y vemos las opciones:

Aunque no entraremos en ver todas las opciones por se sale del objetivo del presente documento, si decir que Burp tiene dos modos de crawling:
- Pasivo (Passive Spidering) - registra los enlaces a los que vamos accediendo desde el navegador
- Activo - Sigue los enlaces de forma autónoma
Por defecto, Burp va a registrar todos los enlaces sobre los que nosotros como usuarios vayamos navegando en la página web (a este modo le llama pasivo). También seguirá todos los enlaces de forma autónoma como cualquier otra araña. Para activarla, vamos a la pestaña Control y pulsamos sobre Spider is paused:

y comenzará a funcionar:

Podremos ver los resultados en la pestaña Site map debajo de la pestaña Target:

Ataques de diccionario para descubrir directorios y ficheros
Algunos ficheros o directorios de las páginas web no tienen ningún enlace que nos lleve a ellos como es el caso de ciertos ficheros de configuración. Para poder encontrarlos podemos usar programas como dirb o wfuzz que vienen incluidos en la distribución Kali Linux. Estos programas prueba una lista con nombres de ficheros y directorios contrar el dominio que le indiquemos. Estas listas se denominan diccionarios. En Kali Linux, por defecto, los diccionarios se guardan:

Para ver que aspecto tienen, podemos observar las primeras 10 entradas de uno de ellos:
Los diccionarios no sólo se usan para descubrir directorios, sino que se pueden usar para diferentes tipos de ataques. Aparte de los que vienen incluidos en Kali, podemos encontrar otros en internet como los que proporciona SecList:
En este caso, intentaremos descubrir ficheros y directorios usando el programa dirb. El método de uso es el siguiente:
dirb {https://paginaWebObjetivo.com} {diccionarioAUtilizar} {opciones}
En este caso usamos las siguientes opciones:
- -z para esperar un tiempo entre petición y petición HTTP. En este caso 2 segundos.
- -H para utilizar las siguientes cabeceras del protocolo HTTP en nuestra petición:
- User-Agent Esta cabecera indica al servidor web quién esta haciendo la petición. En este caso, hemos copiado la misma cabecera que hay google chrome decirle al servidor web que es el navegador chrome quién hace la petición
- Referer esta cabecera indica la página web anterior desde la que hemos llegado a la actual. Es bueno poner como valor de esta cabecera el de la web objetivo.

Web scrapers
Al igual que los web crawlers, los web scrapers pueden de seguir los enlaces pero además son capaces de extraer y analizar la información que hay en las páginas web. Por ejemplo, entre otros, pueden:
- Descargar todos los videos, imágenes, audios, ejecutables, etc
- Pueden descargarse el texto y procesarlo
- Pueden tomar decisiones de acuerdo a la información que procesan
Aunque programar web scrapers se sale del objetivo de este resumen. Os dejo en enlace a 2 frameworks muy utilizados:
y un par de enlaces a 3 librerias de python para los que quieran algo más artesano:
también para cosas sencillas, podemos usar el comando curl para descargar el contenido de una página -nuevamente le paso como opciones las cabeceras del protocolo HTTP User-Agent y Referer:
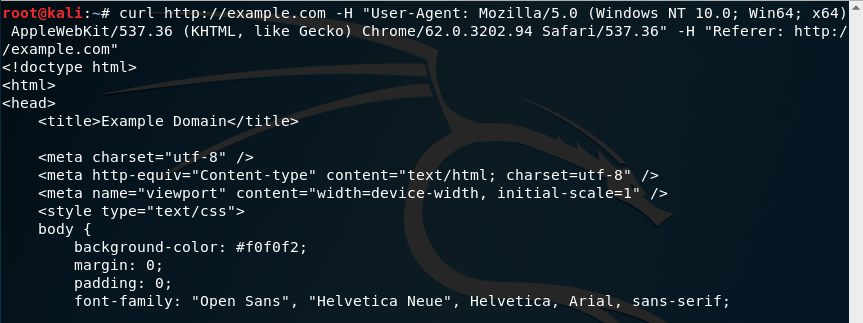
y pasar el contenido al comando grep utilizando pipes para filtrar el texto. En este caso buscamos las líneas que contengan la palabra example:

curl y grep tienen muchas opciones que se les pueden pasar que son interesantes.
Descargar web para navegación offline
También existen scrapers que siguen todos los links y nos descargan cada uno de ellos. Por lo que nos descargaría una web entera. Como ejemplo, veamos el scraper HTTrack que viene incluido en Kali Linux y que nos permite descargar una página para navegar offline por ella. El modo de uso es:
httrack {https://paginaWebObjetivo.com}
En este caso usamos las siguientes opciones:
- -O para indicar donde queremos que nos guarde la web.
- --user-agent para decirle al servidor web que es el navegador chrome quién hace la petición
- --referer-- para indicar la página web anterior desde la que hemos llegado a la actual

Una vez descargada, podremos navegar offline:
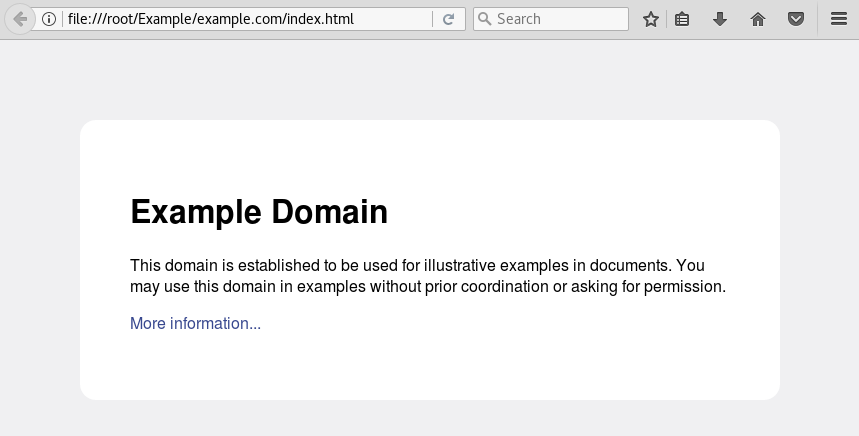
Metadatos en archivos
Los metadatos son información que se utiliza para describir otra información o datos. Por ejemplo, en una fotografía, los metadatos, entre otros, podrían ser:
- Cuando ha sido creada la foto
- Cuándo ha sido modificada la foto por última vez
- Programa que se ha utilizado para retocar la fotografía
- Modelo de cámara con el que se ha tomado la foto
Existen programas como Exiftool que nos permiten ver los metadatos de un archivo. Para instalarlo en Kali ejecutamos el siguiente commando:
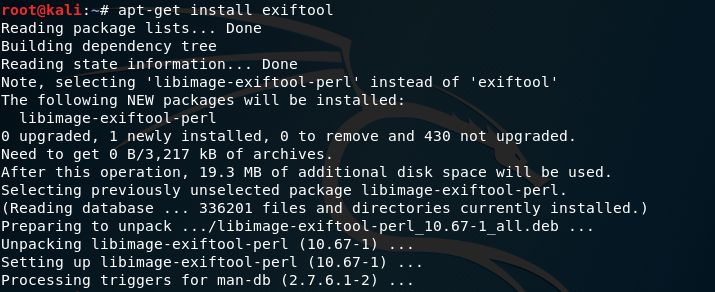
Como ejemplo, podemos descargar una foto de dominio público utilizando el comando wget:
y ver los metadatos de la foto usando exiftool. En este caso, entre otros metadatos, podemos ver el modelo de la cámara con que se tomó la foto y el programa que se uso:

5. Buscando información en redes sociales
Procesando la información contenida en redes sociales
El procesamiento de la información que se publica en redes sociales para el uso particular que se le quiera dar, se sale del rango de este resumen. No obstante, muchos análisis se hacen utilizando las APIs para desarrolladores de las distintas redes sociales. Por lo que os dejo el enlace a sus sitios web para desarrolladores y alguna referencia a la información que podemos encontrar en cada red social:
- Twitter
- Simpatía hacía movimientos sociales
- Identidad política
- Identidad religiosa
- Idolatrías
- Intereses
- Facebook
- Simpatía hacía movimientos sociales
- Identidad política
- Identidad religiosa
- Idolatrías
- Intereses
- Amistades
- Rasgos de personalidad
- Datos personales
- Relaciones sentimentales
- Gustos
- Fotografías
- Influencia
- Google+
- Simpatía hacía movimientos sociales
- Identidad política
- Identidad religiosa
- Idolatrías
- Intereses
- Amistades
- Rasgos de personalidad
- LinkedIn
- Técnologías con las que trabaja una empresa a través de las ofertas de trabajo que publican
- Perfiles profesionales que necesita cubrir una empresa
- Cargos importantes de una empresa
- Perfil profesional
- Perfil académico
- Situación laboral
- Instagram
- Fotografías
- Datos personales
- Amistades
- Influencia
Las fotos e imágenes publicadas en redes sociales pueden contener metadatos interesantes
Usando buscadores específicos para redes sociales
También existen buscadores en internet que nos pueden ayudar a recopilar información sobre una persona objetivo. Por ejemplo veamos el buscador WebMii:
Cuanta más actividad tenga la persona en internet más fácil será obtener resultados. Por ejemplo, si buscamos a un personaje con mucha actividad:
Podremos encontrar mucha información como fotos:
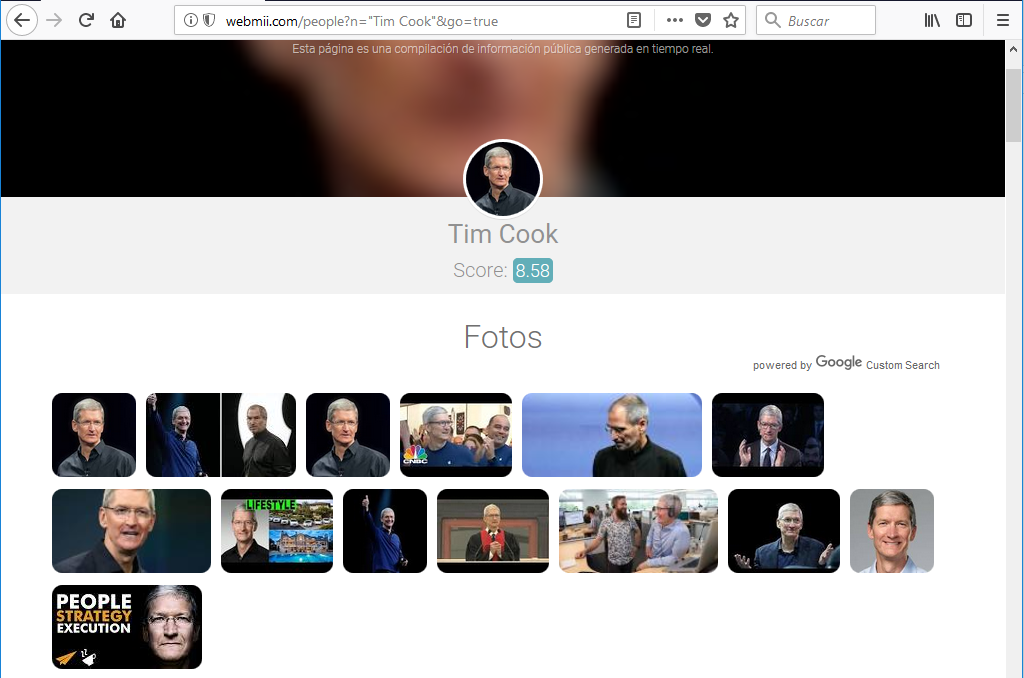
una pequeña biografía, sus perfiles en redes sociales:
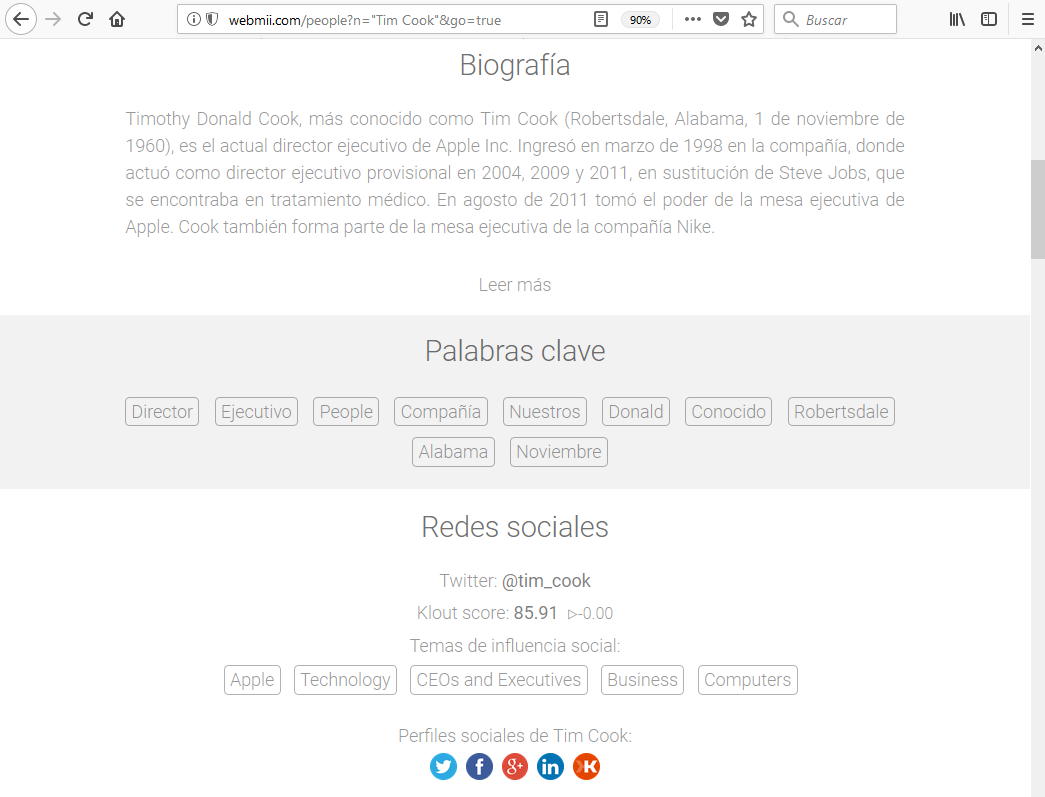
personas que están relacionadas con el personaje, videos en los que ha sido grabado:
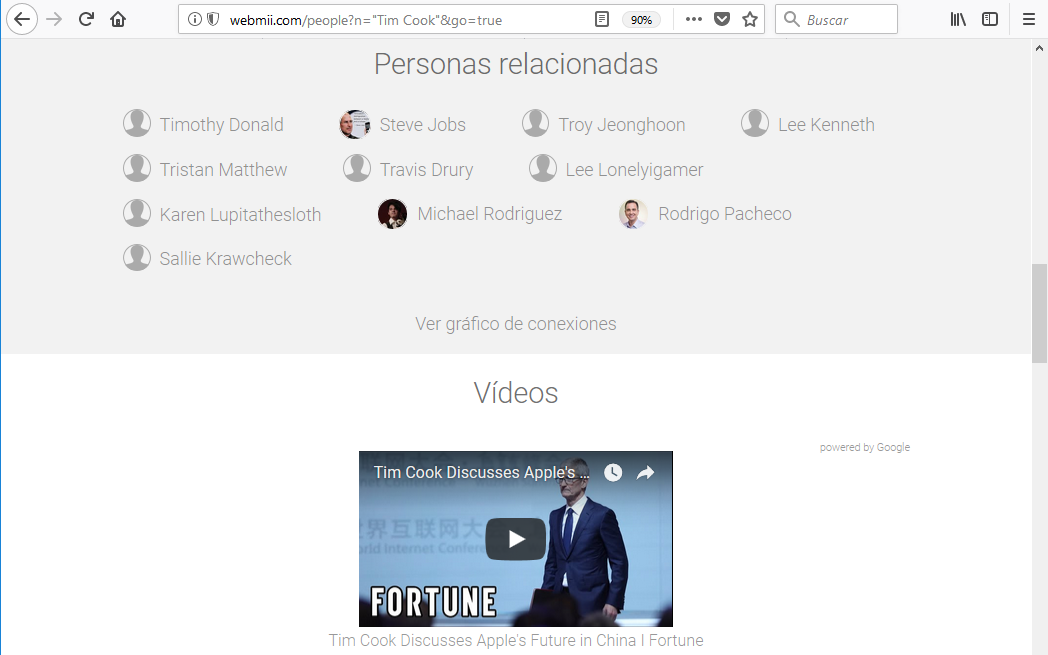
noticias o incluso menciones en sitios web:
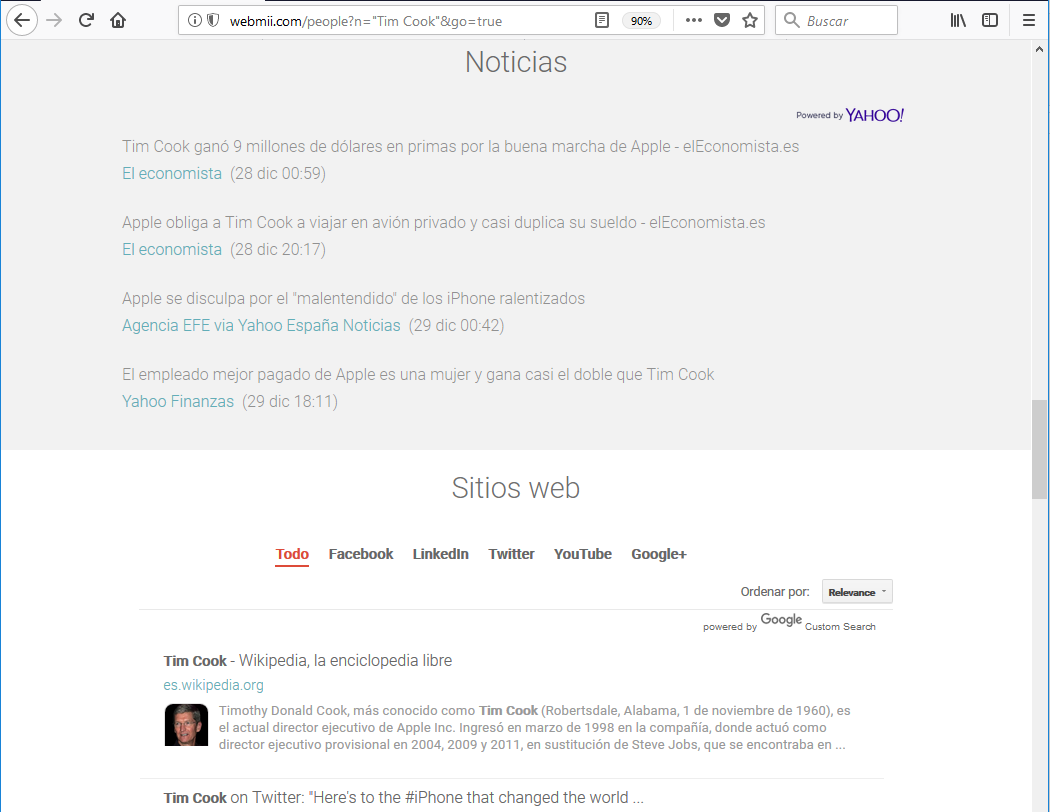
6. Email
Recopilando emails de un dominio usando The Harvester
The Harvester es una herramienta de código abierto desarrollada en python, incluida en Kali Linux, que nos va a ayudar a conseguir información útil, como nombres de usuario o emails, utilizando mayoritariamente fuentes públicas de información tales como el buscador de Google o la red social LinkedIn. Las opciones más comunes que le podemos pasar a la herramienta son:
-d {nombreDeDominioABuscar}
-b {fuentesDeInformaciónDeDondeExtraerLosDatos}
-l {limitarLosResultadosDeLaBusqueda}
-f {guardarLosResultadosEnXMLoHTML}
Veamos algunos ejemplos:
Podemos buscar cuentas de email del dominio, example.com, usando como fuente de busqueda el buscador de Google:

Si quisieramos guardar estos resultados en un archivo html para consultarlo más adelante, podemos usar la opción -f al lanzar el comando:
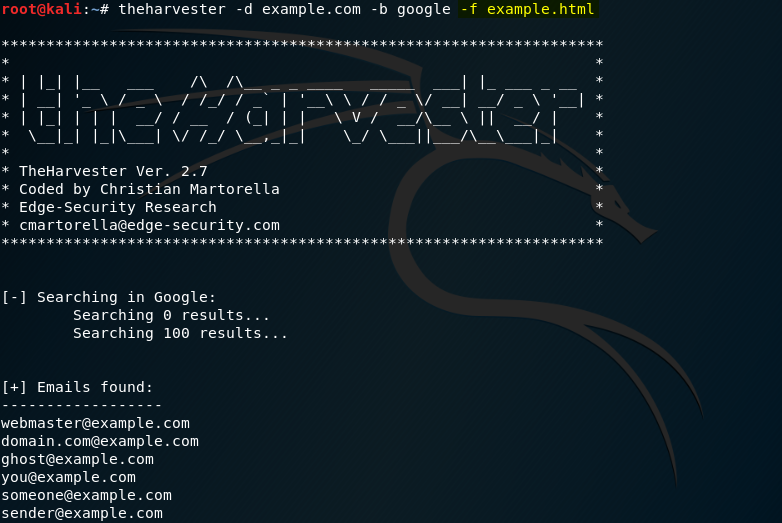
y después ver los resultados en el archivo html. En este caso, por ejemplo, encontramos 27 emails usando el buscador de Google:
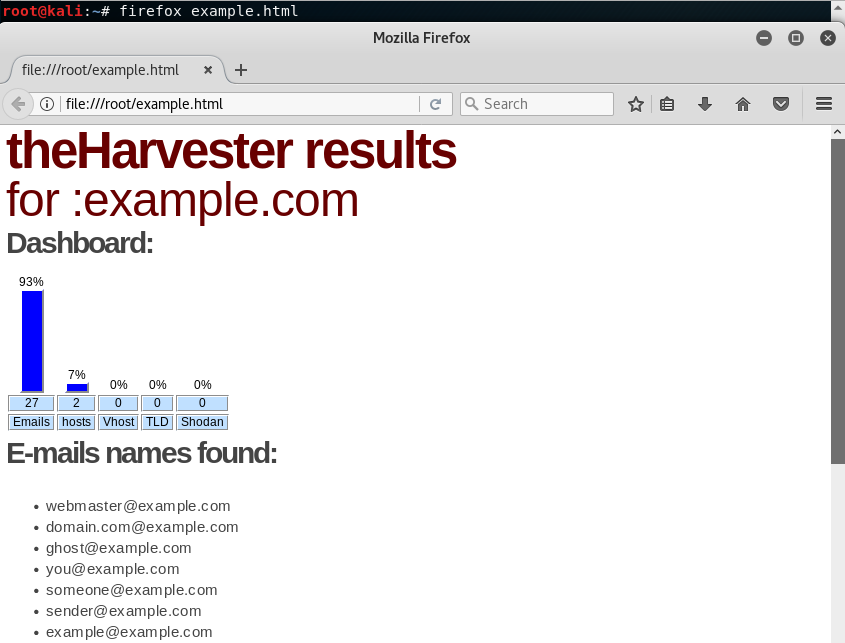
Si quisieramos extraer información sobre el dominio de todas las fuentes de las que dispone la herramienta, podemos usar la palabra clave all con la opción -b:
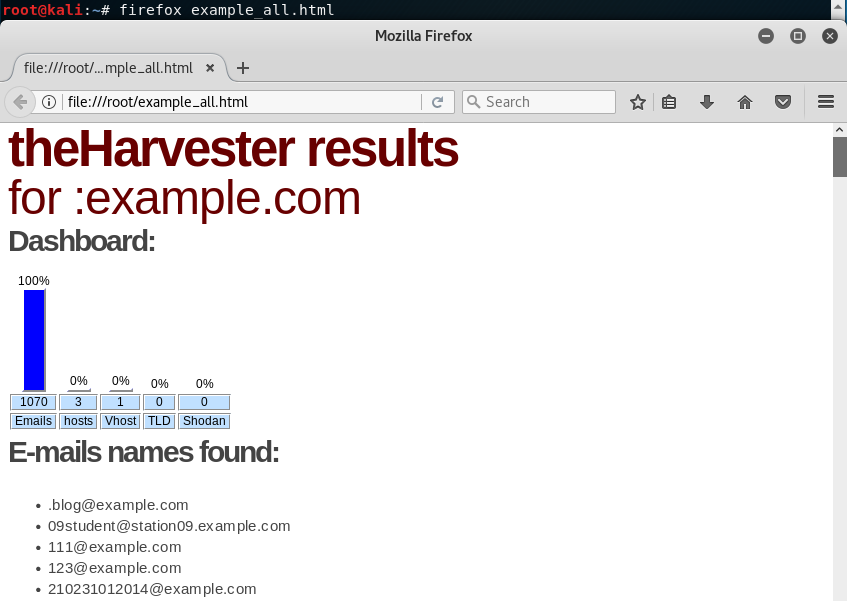
En este caso vemos que el número de emails encontrados aumenta hasta 1070:
Buscando información en las cabeceras de un email
Aparte del contenido que habilitualmente se nos muestra cuando recibimos un email como:
- Remitente (From)
- Destinatario (To)
- Personas en copia (CC)
- Asunto del email (Subject)
- Texto del email (Body)
- Archivos adjuntos (Attachements)
En cada email que enviamos o recibimos hay una cabecera con información el servidor emisor del correo, fecha de creación del correo, ordenadores por los que pasa, etc. Si bien estas cabeceras son manipulables, ver la información siempre arroja algo de luz. Veamos un ejemplo con gmail. En este caso he creado una cuenta para realizar la prueba:
Me subscribo a una newsletter (Hunchly Daily Hidden Services Report) para estar informado de los nuevos servicios que se descubren en la red Tor:
Tras subscribirme, recibo el email de bienvenida:
Lo abro y para ver las cabeceras, pulso sobre la triángulo a la derecha del botón responder para desplegar el menú. en el menú selecciono Mostrar original:

Y podremos ver el contenido completo del email incluyendo las cabeceras:

Las cabeceras siempre es la información que esta al comienzo del mensaje. Para ayudarnos a entenderlas un poco mejor, podemos copiar la cabecera del email:

Fijaros que sólo copio la cabecera, no el contenido del email. Una vez copiada la cabecera, podemos utilizar la herramienta MessageHeader de Google para entender mejor el contenido:
Pegamos la cabecerá en el cuadro de texto y pulsamos el botón ANALIZAR LA CABECERA ANTERIOR:
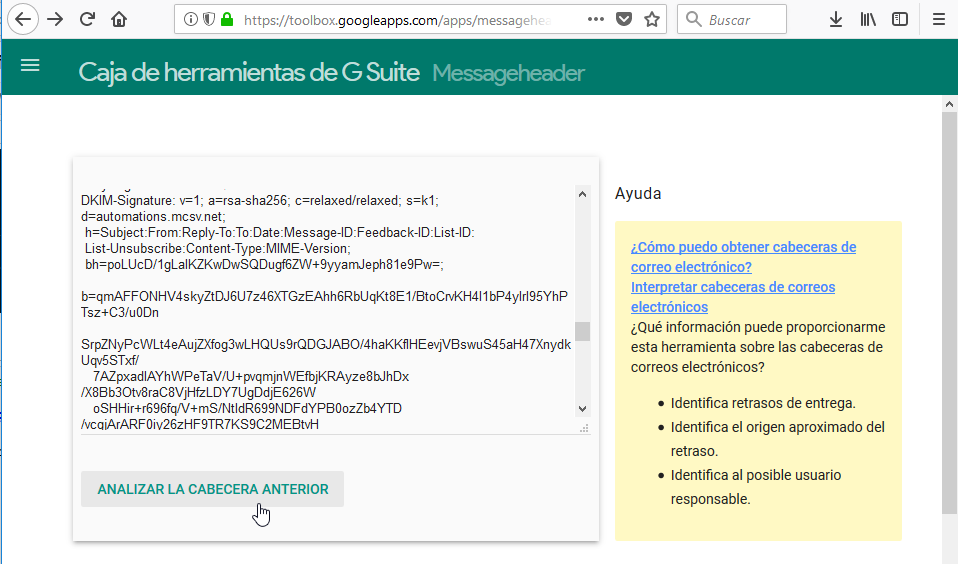
Y en el resultado, aunque no está la información contenida en la cabecerá del email ya que eso no esta dentro del propósito de este resumen, podremos ver información básica como el número de ordenadores por donde ha pasado o desde dónde se envío el email:
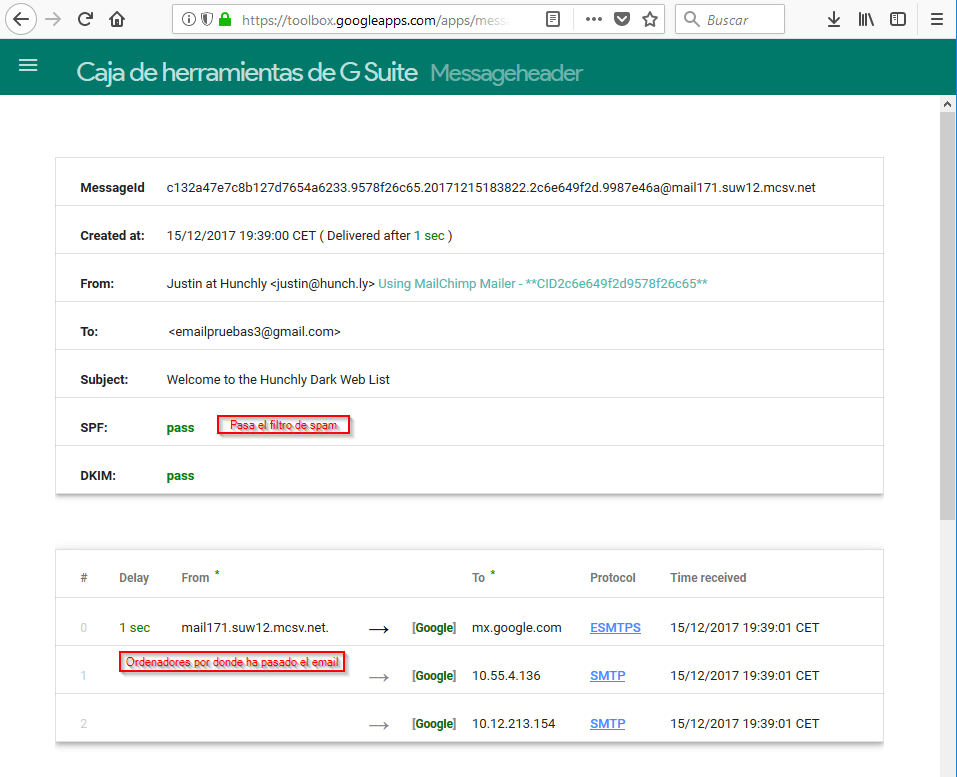
Buscando información sobre el emisor del email
En las cabeceras del email, si nadie las ha manipulado, podemos ver la IP desde dónde nos han enviado ese email:
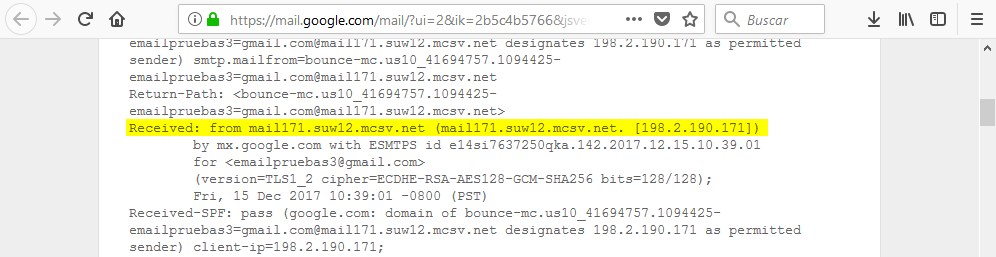
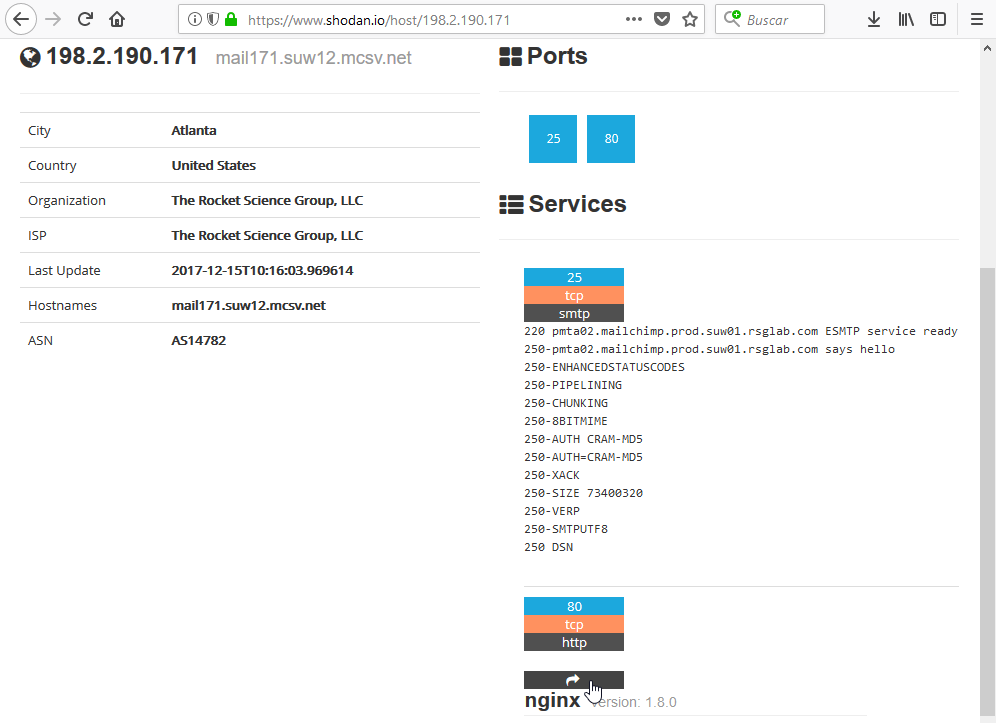
Con la IP podemos ir a shodan para que nos facilite información sobre la misma:

Vemos que, como esperabamos, al ser un servidor de email tiene habilitado el protocolo SMTP que se utiliza para enviar correos. Aquí tendríamos que anotar que el SMTP esta habilitado en el puerto 25 que por definición no esta encriptado. Esta información podría sernos útil a la hora de enumerar usuarios en la fase de enumeración. Otra punto que vemos es que tiene el protocolo HTTP habilitado en el puerto 80. Es decir tiene un servicio web habilitado y probablemente una página web. Accedemos a ella pulsando en el botón con una flecha que esta debajo del número 80:
Y llegamos a la web de MailChimp que es un servicio que puede usarse para hacer campañas de marketing por email o newsletters:
7. WHOIS
Trataremos de encontrar información sobre la persona o entidad a la que esta registrada un nombre de dominio o recurso de internet.
Bases de datos WHOIS
Existen unas bases de datos, llamadas WHOIS, que contienen información pública sobre el propietario de un nombre de dominio registrado y otros recursos de internet. Cuando registramos un nombre de dominio, es obligatorio cumplimentar ciertos datos de contacto y decidir si queremos que esta información sea pública o si preferimos pagar un importe extra por un registro privado en donde figurarán los datos de un tercero. Si el nombre de dominio ha sido registrado publicamente, entre otros, podremos ver:
- Servidores DNS (nameservers) de la empresa objetivo
- Cuando caduca el registro del dominio
- Dirección física de una sede de la empresa objetivo
- Rango de red asociado a la persona o empresa objetivo
- Datos de contacto de la persona que registro el dominio. Aunque no siempre, podría ser un empleado con un cargo importante en la empresa al que dirigir un ataque de ingenieria social
Las bases de datos WHOIS son administradas y mantenidas por los RIR (Regional Internet Registries)
Consultas a bases de datos WHOIS desde la línea de comandos
Existe un protocolo para realizar consultas a bases de datos WHOIS que usa el puerto 43 del protocolo TCP. Podemos realizar consultas desde la línea de comandos usando el programa whois:
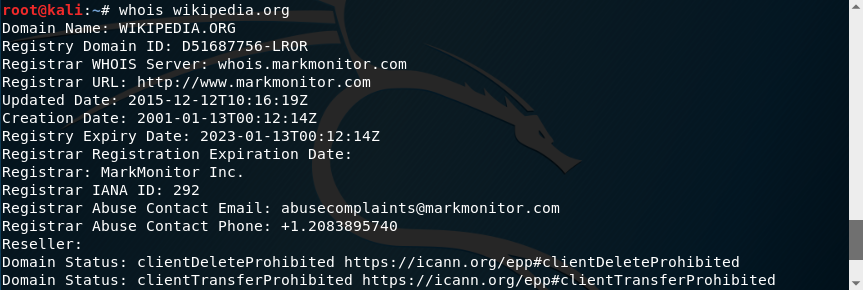
Por ejemplo, entre los resultados podemos ver emails, teléfonos o los servidores dns:
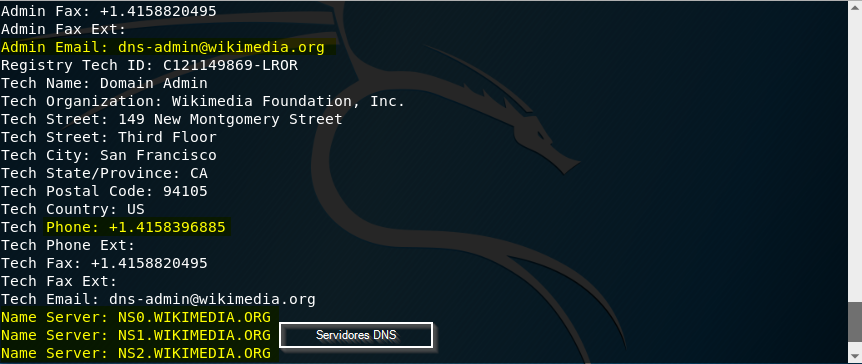
Consultas a bases de datos WHOIS en España
Si intentamos consultar información sobre un nombre de dominio en España usando whois, obtendremos el siguiente mensaje:

Esto quiere decir que no tenemos configurado el servidor donde esta la base de datos whois para los dominios de España (.es). Si queremos configurar sólo el de España, debemos crear el fichero, whois.conf, en el directorio /etc. Para ello, podemos usar cualquier editor de texto como, por ejemplo, el editor Vim:

y configurar el servidor donde está la base de datos de España añadiendo el texto .es$ whois.nic.es:

NOTA Las líneas que empiezan por # son comentarios
Si, en vez de configurar sólo el servidor donde esta la base de datos whois de España, queremos configurar todos los servidores que contienen bases de datos whois de los distintos países, podemos bajarnos el fichero desde algún repositorio de internet. Por ejemplo, podemos acceder al siguiente repositorio:

y descargarlo en el directorio /etc:

Esto bastaría para la mayoría de los países. Sin embargo, en España, no es suficiente:
Aparte de crear o descargar el fichero whois.conf, debemos solicitar acceso al servidor desde la web de red.es:

Consultas a bases de datos WHOIS usando páginas web
También podemos consultar información en base de datos whois usando páginas web como domaintools. Sólo debemos indicar el nombre de dominio que deseamos buscar:

y nos mostrará los datos:

8. DNS
Una vez que hemos localizado los servidores DNS en el punto anterior, trataremos de identificar equipos importantes dentro de la red objetivo.
Breve introducción de manera muy informal a DNS
Aunque se sale del objetivo de estas notas cubrir el protocolo DNS, a modo de recordatorio y manera informal hago esta pequeña introducción. Debido a que, en general, resulta más sencillo recordar nombres que secuencias numéricas, existe un protocolo llamado DNS encargado de traducir nombres de dominio como google.com o apple.es a direcciones IP. El protocolo DNS es el medio de comunicación que utilizamos para solicitar la traducción de un nombre a su dirección IP. Las traducciones se solicitan a un servidor DNS que vendría a ser, en este ejemplo, el diccionario de traducciones donde podemos buscar el nombre y obtener la IP. Al igual que ocurre con los diccionarios que clasifican las palabras en adjetivos, sustantivos, determinantes, etc. Los servidores DNS clasifican las cada una de las entradas en su diccionario con unas letras a las que llaman registros. Algunos conocidos son:
- A (para solicitar la IPv4 de un nombre de dominio)
- AAAA (para solicitar la IPv6 de un nombre de dominio)
- CNAME (para conocer los nombres (alias) de todos los servicios bajo una misma IP)
- PTR (para conociendo la IP preguntar por el nombre de dominio)
- NS (para saber el servidor o los servidores DNS que continen los registros del dominio)
- MX (para saber los servidores de correo)
- SPF (indica que servidores de correo están autorizados para enviar emails con el dominio)
El protocolo DNS, normalmente, funciona en el puerto 53 del protocolo UDP, pero para ciertas operaciones usa el puerto 53 del protocolo TCP.
Consultas a servidores DNS usando nslookup
nslookup es un programa que suele venir por defecto en sistemas operativos de windows y en sistemas operativos GNU/Linux. El modo más sencillo de hacer una consulta con nslookup es escribir:
nslookup {nombreDeDominio.com}
por defecto nos devolvera la IPv4 (registro A) y, si está disponible, la IPv6 (registro AAAA) del nombre de dominio que le solicitemos:
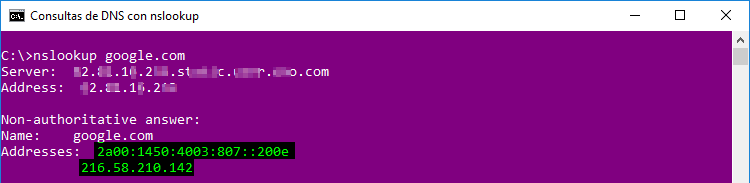
Podemos comprobar que esto es así copiando la IP y pegandola en la barra de direcciones de cualquier navegador. Al navegar a la página usando la IP nos mostrará una advertencia de que el certificado de la página no esta autorizado para ese nombre de dominio:
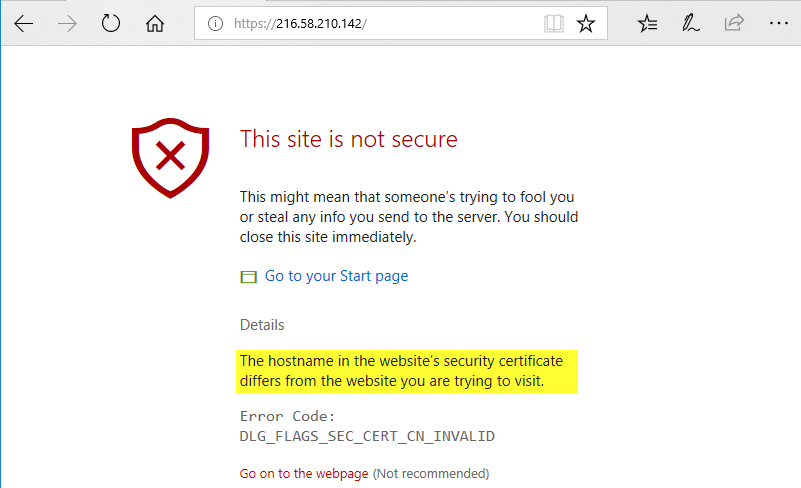
si pulsamos en continuar accederemos a la web. Otra forma de utilizar nslookup es en modo interactivo. Para ello simplemente tecleamos nslookup:

Vemos que, por defecto, nos aparece el servidor DNS que nos ha configurado nuestro proveedor de servicios de internet. Pero podemos usar el que queramos, por ejemplo, para usar el servidor DNS de google tecleamos server y la dirección IPv4 del servidor DNS de google que es 8.8.8.8:

Ahora las consultas las haremos al servidor de google. Vamos a comenzar consultando las direcciones IPv4 del dominio hackthissite.org. Para ello le decimos que tipo de registro queremos buscar utilizando el comando set type. Como en este caso queremos buscar una dirección IPv4 (registro A), escribimos:
set type={registro} {nombreDelDominio.ext}
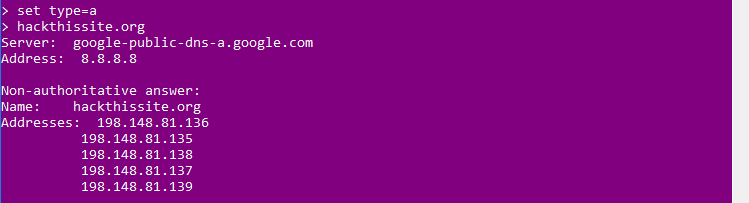
como podemos ver nos facilita las direcciones IPv4 del dominio. Si, en vez de las de IPv4, quisieramos las direcciones IPv6:
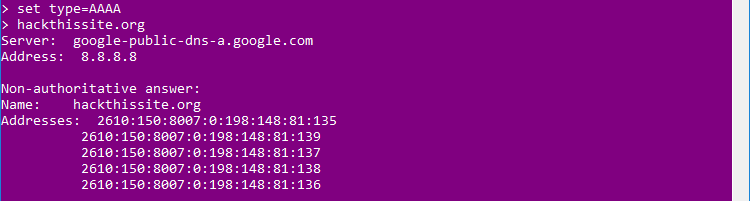
o los servidores de email:
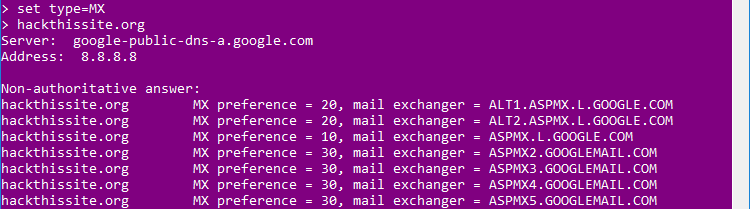
en este caso vemos que estan usando los servidores de google. También podemos ver los servidores DNS que continen los registros del dominio:

y realizar consultas a estos servidores:

Consultas a servidores DNS usando dig
Dig es un programa que, normalmente, viene instalado en la mayoria de distribuciones de GNU/Linux. Para usarlo escribimos:
dig {nombreDeDominio.com}

Para hacer consultas a otro servidor DNS usamos:
dig @{ipServidorDNS} {nombreDeDominio.com}
Por ejemplo, para realizar consultas al servidor DNS de google:

Como podemos ver, por defecto, nos devuelve los registros A, pero si quisiesemos otros registros, podemos escribir
dig @{ipServidorDNS} {registroQueQueramos} {nombreDeDominio.com}
Por ejemplo, para consultar por los registros AAAA (IPv6):

o los registros MX:

Consultas a servidores DNS usando páginas web
Existen páginas web que nos permiten hacer consultas a servidores DNS. Por ejemplo, google nos permite usar el programa dig online a través del siguiente enlace:

9. Usando el RIR para encontrar bloques de red
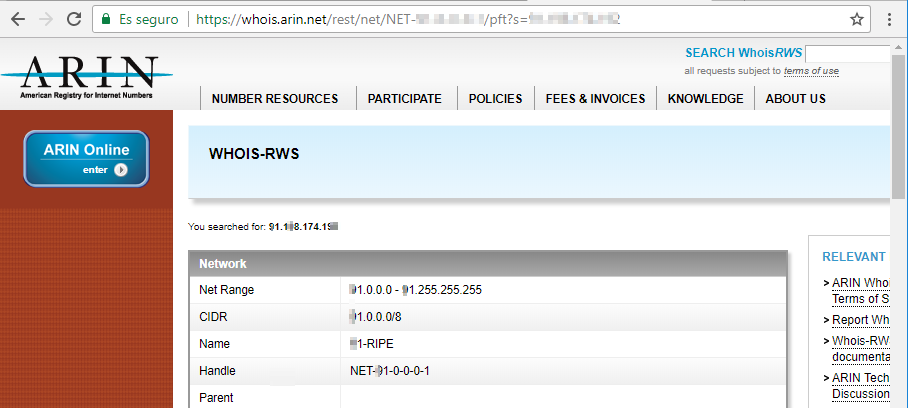
Aunque hemos visto en ejemplos anteriores que en buscadores como ipv4info puede encontrarse el bloque de red de la empresa objetivo:
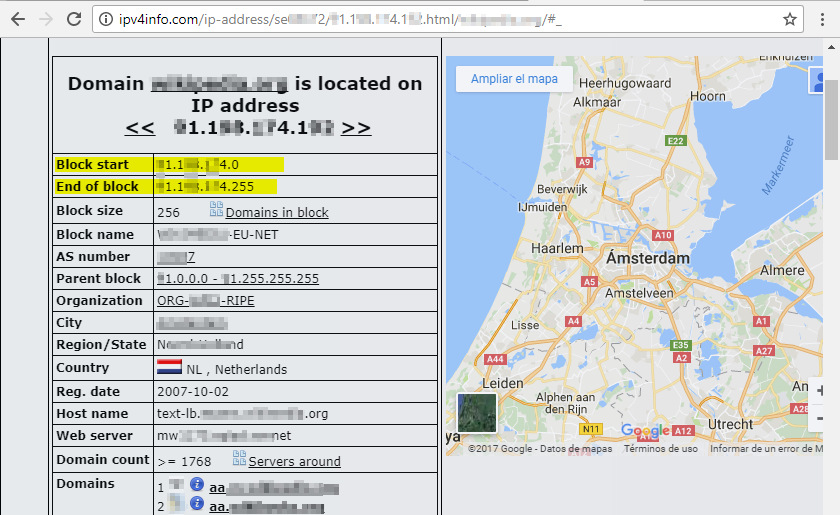
En caso de no haberlo encontrado, podemos buscar, utilizando la IP asociada al nombre de dominio, en la web del RIR donde se haya registrado la web para obtener el bloque de red. En este caso, el RIR es ARIN. Buscamos por IP:

En los resultados podemos ver el bloque de red: